
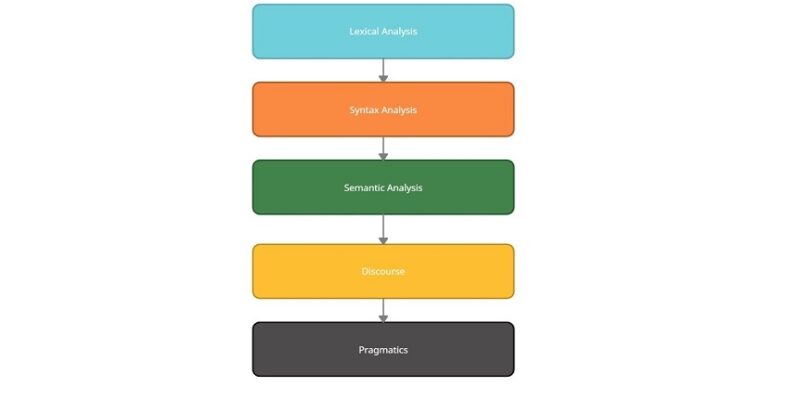
The process of Natural Language Processing is divided into 5 major stages or phases, starting from basic word-level processing up to finding complex meanings of sentences.
This blog is a part of the series: A Complete Introduction to Natural Language Processing.
Stages of Natural Language Processing
Morphological Analysis/ Lexical Analysis
Syntax Analysis
Semantic Analysis
Discourse
Pragmatics
The final stage of NLP, Pragmatics interprets the given text using information from the previous steps. Given a sentence, “Turn off the lights” is an order or request to switch off the lights.
Morphological or Lexical Analysis deals with text at the individual word level. It looks for morphemes, the smallest unit of a word. For example, irrationally can be broken into ir (prefix), rational (root) and -ly (suffix). Lexical Analysis finds the relation between these morphemes and converts the word into its root form. A lexical analyzer also assigns the possible Part-Of-Speech (POS) to the word. It takes into consideration the dictionary of the language.
For example, the word “character” can be used as a noun or a verb.
Syntax Analysis ensures that a given piece of text is correct structure. It tries to parse the sentence to check correct grammar at the sentence level. Given the possible POS generated from the previous step, a syntax analyzer assigns POS tags based on the sentence structure.
For example:
Correct Syntax: Sun rises in the east.
Incorrect Syntax: Rise in sun the east.
Consider the sentence: “The apple ate a banana”. Although the sentence is syntactically correct, it doesn’t make sense because apples can’t eat. Semantic analysis looks for meaning in the given sentence. It also deals with combining words into phrases.
For example, “red apple” provides information regarding one object; hence we treat it as a single phrase. Similarly, we can group names referring to the same category, person, object or organisation. “Robert Hill” refers to the same person and not two separate names – “Robert” and “Hill”.
Discourse deals with the effect of a previous sentence on the sentence in consideration. In the text, “Jack is a bright student. He spends most of the time in the library.” Here, discourse assigns “he” to refer to “Jack”.
Further in the series: Tokenization in Natural Language Processing
References
- Natural Language Processing with Python
- Natural Language Processing: State of The Art, Current Trends and Challenges (researchgate.net)



