
Stopwords and Filtering is the next step in NLP pre-processing after Tokenization. If we consider the same example from the previous blog on Tokenization, we can see that many tokens are rather irrelevant. As a result, we need to filter the required information.
Stopwords
Stop words refers to common words in a language. These are words that do not contain major information but are necessary for making the sentence complete. Some examples of stop words are “in”, “the”, “is”, “an”, etc. We can safely ignore these words without losing the meaning of the content.
Let’s consider the previous example:
["This", "is", "an", "example", "text", "for", "word", "tokenization", ".", "Word", "tokenization", "split", "'s", "texts", "into", "individual", "words", "."]Here, words like “is”, “an”, “for” add no value to the sentence.
While stop words refer to “common words”, there is no universal set of stop words. Every tool provides a different set of stop words. However, we can see major stop words covered in all the sets.
Since stop words are words that do not contain any information, we can ignore them when training deep learning models for classification.
However, one must note that stop word removal is not recommended in Machine Translation and Summarization tasks.
Stopwords in NLTK
NLTK is one of the tools that provide a downloadable corpus of stop words. Before we begin, we need to download the stopwords. To do so, run the following in Python Shell.
import nltk
nltk.download("stopwords")Once the download is successful, we can check the stopwords provided by NLTK. As of writing, NLTK has 179 stop words.
To get the list of all the stop words:
from nltk.corpus import stopwords
print(stopwords.words("english"))Example of some stop words:
["i", "me", "my", "myself", "we", "our", "ours", "ourselves", "you", "you're", "you've", "you'll", "you'd", "your", "yours", "yourself", "yourselves", "he", "him", "his", "himself", "she", "she's", "her", "hers", "herself"]Filtering
Now that we know what stop words are, we can use them to filter out in a from a given sentence. Filtering is the process of removing stop words or any unnecessary data from the sentence. We can easily filter stop words using Python. For this purpose, we consider a different but similar example.
import nltk
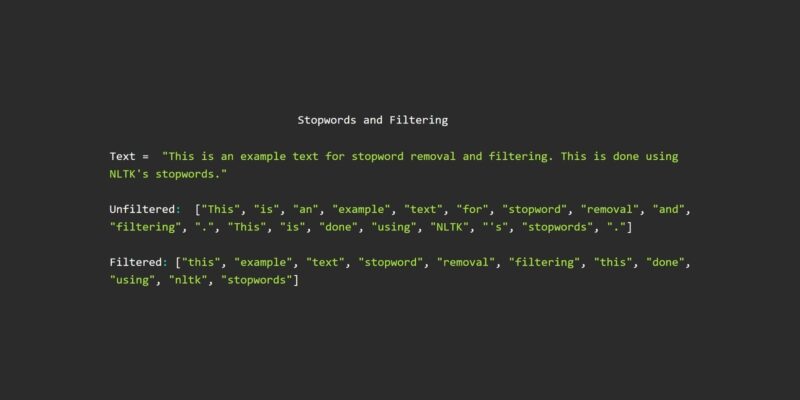
text = "This is an example text for stopword removal and filtering. This is done using NLTK's stopwords."
words = nltk.word_tokenize(text)
print("Unfiltered: ", words)
stopwords = nltk.corpus.stopwords.words("english")
cleaned = [word for word in words if word not in stopwords]
print("Filtered: ", cleaned)Output
Unfiltered: ["This", "is", "an", "example", "text", "for", "stopword", "removal", "and", "filtering", ".", "This", "is", "done", "using", "NLTK", "'s", "stopwords", "."]
Filtered: ["This", "example", "text", "stopword", "removal", "filtering", ".", "This", "done", "using", "NLTK", "'s", "stopwords", "."]Although we got rid of stop words, we see that we still have punctuations. For this purpose, we can extend the list of stop words to contain all the punctuations from string.punctuations. Similarly, we can modify the stopwords list as per the application to include or exclude words of our choice.
Moreover, the token “‘s” is not providing any information. A crude way to tackle this issue is to remove all words with less than 2 characters. Similarly, other filters can be applied to get the most information from the text.
Additionally, we see that some words are capitalized. Hence, to avoid treating them as 2 different strings, we convert all tokens into lowercase.
import nltk
import string
text = "This is an example text for stopword removal and filtering. This is done using NLTK's stopwords."
words = nltk.word_tokenize(text)
stopwords = nltk.corpus.stopwords.words("english")
# Extending the stopwords list
stopwords.extend(string.punctuation)
# Remove stop words and tokens with length < 2
cleaned = [word.lower() for word in words if (word not in stopwords) and len(word) > 2]
print(cleaned)Final Output
["this", "example", "text", "stopword", "removal", "filtering", "this", "done", "using", "nltk", "stopwords"]Thus, we used stopwords and filtering to pre-process our text to keep only the essential tokens and ignore the irrelevant information.
Further in the series: Stemming and Lemmatization in Natural Language Processing










correction:
at the second code bracket you import the stopwords
you use:
from nltk import stopwords
instead:
from nltk.corpus import stopwords
later you use correctly
Fixed, Thanks for pointing out!