
As discussed in Stages of Natural Language Processing, Syntax Analysis deals with the arrangement of words to form a structure that makes grammatical sense. A sentence is syntactically correct when the Parts of Speech of the sentence follow the rules of grammar. To achieve this, the given sentence structure is compared with the common language rules.
Part of Speech
Part of Speech is the classification of words based on their role in the sentence. The major POS tags are Nouns, Verbs, Adjectives, Adverbs. This category provides more details about the word and its meaning in the context. A sentence consists of words with a sensible Part of Speech structure.
For example: Book the flight!
This sentence contains Noun (Book), Determinant (the) and a Verb (flight).
Part Of Speech Tagging
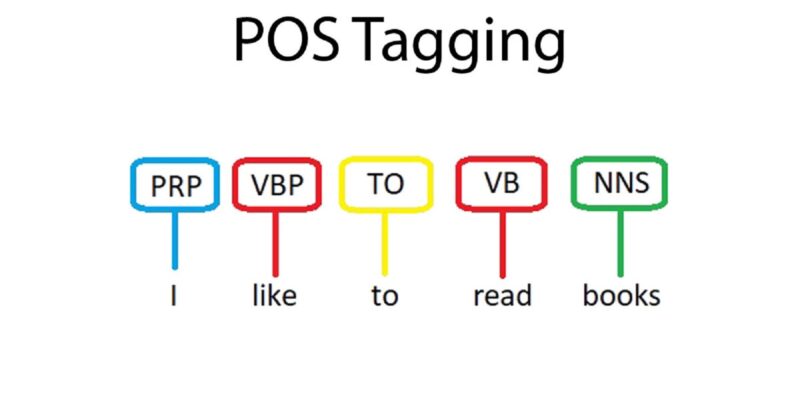
POS tagging refers to the automatic assignment of a tag to words in a given sentence. It converts a sentence into a list of words with their tags. (word, tag). Since this task involves considering the sentence structure, it cannot be done at the Lexical level. A POS tagger considers surrounding words while assigning a tag.
For example, the previous sentence, “Book the flight”, will become a list of each word with its corresponding POS tag – [(“Book”, “Verb”), (“the”, “Det”), (“flight”, “Noun”)].
Similarly, “I like to read book” is represented as: [(“I”, “Preposition”), (“like”, “Verb”), (“to”, “To”), (“read”, “Verb”), (“books”, “Noun”)]. Notice how the word Book appears in both sentences. However, in the first example, it acts as a Verb but takes the role of a Noun in the latter.
Although we are using the generic names of the tags, in real practice, we refer a tagset for tags. The Penn TreeBank Tag Set is most used for the English language. Some examples from Penn Treebank:
| Part Of Speech | Tag |
| Noun (Singular) | NN |
| Noun (Plural) | NNS |
| Verb | VB |
| Determiner | DT |
| Adjective | JJ |
| Adverb | RB |
Difficulties in POS Tagging
Similar to most NLP problems, POS tagging suffers from ambiguity. In the sentences, “Book the flight” and “I like to read books”, we see that book can act as a Verb or Noun. Similarly, many words in the English dictionary has multiple possible POS tags.
- This (Preposition) is a car
- This (Determiner) car is red
- You can go this (Adverb) far only.
These sentences use the word “This” in various contexts. However, how can one assign the correct tag to the words?
POS Tagging Approaches
Rule-Based POS Tag
- Get all the possible POS tags for individual words: A – Article; Book – Noun or Verb
- Use the rules to assign the correct POS tag: As per the possible tags, “A” is an Article and we can assign it directly. But, a book can either be a Noun or a Verb. However, if we consider “A Book”, A is an article and following our rule above, Book has to be a Noun. Thus, we assign the tag of Noun to book.
Stochastic Tagger
- Word Frequency: In this approach, we find the tag that is most assigned to the word. For example: Given a training corpus, “book” occurs 10 times – 6 times as Noun, 4 times as a Verb; the word book will always be assigned as “Noun” since it occurs the most in the training set. Hence, a Word Frequency Approach is not very reliable.
- Tag Sequence Frequency: Here, the best tag for a word is determined using the probability the tags of N previous words, i.e. it considers the tags for the words preceding book. Although this approach provides better results than a Word Frequency Approach, it may still not provide accurate results for rare structures. Tag Sequence Frequency is also referred to as the N-gram approach.
This is one of the oldest approaches to POS tagging. It involves using a dictionary consisting of all the possible POS tags for a given word. If any of the words have more than one tag, hand-written rules are used to assign the correct tag based on the tags of surrounding words.
For example, if the preceding of a word an article, then the word has to be a noun.
Consider the words: A Book
POS Tag: [(“A”, “Article”), (“Book”, “Noun”)]
Similarly, various rules are written or machine-learned for other cases. Using these rules, it is possible to build a Rule-based POS tagger.
A Stochastic Tagger, a supervised model, involves using with frequencies or probabilities of the tags in the given training corpus to assign a tag to a new word. These taggers entirely rely on statistics of the tag occurrence, i.e. probability of the tags.
Based on the words used for determining a tag, Stochastic Taggers are divided into 2 parts:
Note: There are other methods for POS tagging as well, including Deep Learning approach. However, for most applications, N-gram model provides great results to work with.
Part of Speech Tagging in NLTK
NLTK comes with a POS Tagger to use off-the-shelf. The tagger takes tokens as input and returns a tuple of word with it’s corresponding POS tag. If you are following the series, you already have the required packages. However, if you directly landed on this blog, we recommend to go through Tokenization and Stopwords and Filtering. Once you have the necessary downloads, you can use the POS tagger directly.
""" This block of code snippet is stolen from our blog on Stopwords and Filtering """
import nltk
import string
text = "This is an example text for stopword removal and filtering. This is done using NLTK's stopwords."
words = nltk.word_tokenize(text)
stopwords = nltk.corpus.stopwords.words("english")
# Extending the stopwords list
stopwords.extend(string.punctuation)
# Remove stop words and tokens with length < 2
cleaned = [word.lower() for word in words if (word not in stopwords) and len(word) > 2]
""" End of stolen code """
# Assign POS Tags to the words
tagged = nltk.pos_tag(cleaned)
print(tagged)Output
[("this", "DT"), ("example", "NN"), ("text", "NN"), ("stopword", "NN"), ("removal", "NN"), ("filtering", "VBG"), ("this", "DT"), ("done", "VBN"), ("using", "VBG"), ("nltk", "JJ"), ("stopwords", "NNS")]Thus, we successfully got POS tags for the given text input.
Further in the series: Hidden Markov Model (HMM) Tagger in NLP
References
- Part-of-speech tagging – Wikipedia
- NLP Guide: Identifying Part of Speech Tags using Conditional Random Fields
- Categorizing and Tagging Words (nltk.org)



