

Named Entity Recognition, NER, is a process in NLP for finding relevant information, called as Named Entities. It classifies these entities into pre-defined classes like name, location, time, organization, etc. NER helps in building applications based on Information Extraction.
NER allows extracting the necessary keywords from the text.
For example, consider a sentence “I have a flight to New York at 5 pm”. Here, we have 2 entities:
- New York: Location
- 5pm: Datetime
We can use this information to answer questions like how, where, with whom, etc. Additionally, NER also performs Chunking. Notice how “New York”, being 2 tokens are considered as one during NER. Although, it is possible to recognize only common classes. If one requires a specific class that is uncommon, one may need to build their own NER model.
Named Entity Recognition
Stanford CoreNLP
- Enter the input text to annotate
- Select the required annotations
- Select the language
- Submit
Stanza
Stanford’s CoreNLP provides an online interface for various Natural Language Processing tools. One such tool is Named Entity Recognition.
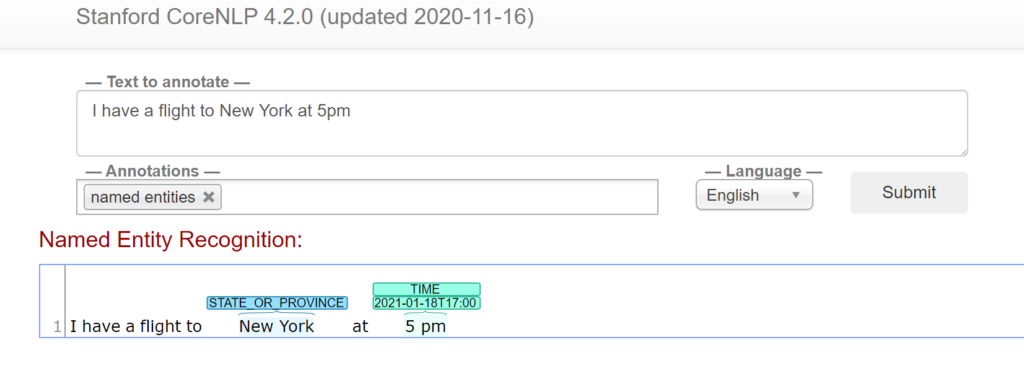
This will generate results for the input based on selected annotations. This is a handy tool to work with NER manually.
Although CoreNLP provides quick results, it is a web interface. Hence, to automate the task of NER or to integrate with the code, Stanford provides a package named Stanza (stanfordnlp.github.io). This package is available in Python, built on top of PyTorch.
Firstly, install PyTorch based on your system.
Once you have installed PyTorch, you can install Stanza through pip.
pip install stanzaBefore using the library, you need to download the English model. This is done through Python shell or saving the code into a python file and running it.
import stanza
stanza.download('en')Now we can use the library for our Named Entity Recognition.
import stanza
nlp = stanza.Pipelinnlp = stanza.Pipeline(lang='en', processors='tokenize,ner')
text = "I have a flight to New York at 5pm"
doc = nlp(text)
print(doc.entities)Output
[{
"text": "New York",
"type": "GPE",
"start_char": 20,
"end_char": 28
}, {
"text": "5pm",
"type": "TIME",
"start_char": 32,
"end_char": 35
}]Here, GPE refers to Country, State or City. In addition to GPE, some other common tags are PER (person), LOC (Location), TIME (DateTime) and ORG(Organization). The extended Stanza model provides up to 18 classes, however, these 4 classes are enough for most applications. Refer to Stanza documentation for a list of all available classes and additional usage.
With this, we end our series on A Complete Introduction to Natural Language Processing. Further, we will be adding blogs on various applications on NLP.



