
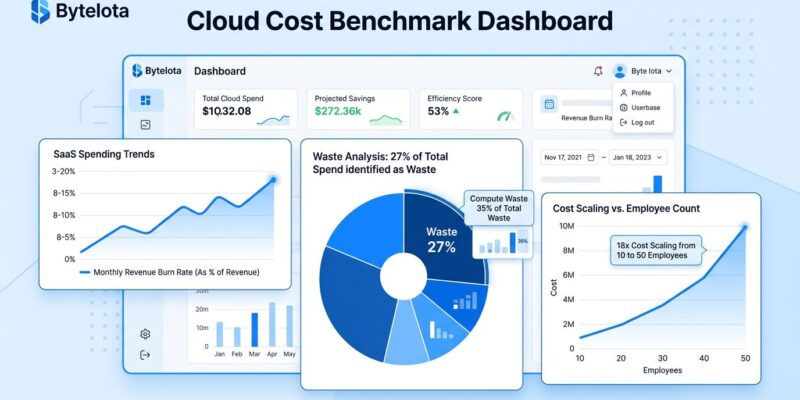
New benchmark data from 2026 reveals what SaaS companies actually spend on cloud infrastructure, and the numbers expose harsh realities most startups underestimate. SaaS companies burn 8-15% of revenue on cloud, while the average organization wastes 27% of cloud spend—with compute waste leading at 35%. The most counterintuitive finding: a 50-person company pays approximately 18x more than a 10-person team at the same revenue level. Cloud costs scale with headcount, not usage efficiency.
SaaS Spending Benchmarks: What’s Normal vs Wasteful
SaaS companies spend 8-15% of revenue on cloud infrastructure, with a median of 11.5%. Fintech burns even higher at 10-20%, with a median of 15%. These aren’t hypothetical ranges—they’re the actual spending patterns Spendark’s 2026 Cloud Cost Benchmark Report identified across thousands of companies.
Cost per employee tells an even more specific story. SaaS companies average $380/month per employee. Fintech teams pay $620/month. E-commerce operates leaner at $210/month. Media and streaming companies top out at $750/month per employee. If your SaaS startup with 20 employees spends $12,400/month, you’re at the fintech median—that’s normal. If you’re spending $20,000/month, you’re overspending by roughly 60% or running unusually compute-heavy workloads.
The most surprising insight: company headcount is the strongest single predictor of cloud spend—stronger than funding stage, geography, or technology stack. A 50-person company pays approximately 18x more than a 10-person company even with identical revenue. More engineers don’t just mean more compute. They mean more environments (dev, staging, prod), more experimental projects, more microservices, more CI/CD pipelines, more logging, more monitoring. Cloud sprawl correlates with team size, not product complexity.
The 27% Waste Problem: Where Cloud Spend Leaks
Organizations waste an average of 27% of cloud spend according to 2026 cloud computing statistics. Compute leads the waste breakdown at 35%, storage accounts for 25%, data transfer 20%, and unused resources 15%. That’s not vendor inefficiency—it’s self-inflicted. Developers make architecture decisions (instance sizing, Kubernetes resource requests, storage retention policies) without visibility into the financial consequences.
The top causes are predictable. No Reserved Instance or Savings Plan coverage means forfeiting 50-72% discounts. Kubernetes resource requests set to worst-case assumptions mean most K8s clusters run at 8-25% CPU utilization. Storage audits never happen, leaving unattached EBS volumes, old snapshots, and S3 buckets without lifecycle policies to accumulate costs. Dev and staging environments run 24/7 when they could shut down nights and weekends for 60% savings.
Well-managed organizations with monthly FinOps review processes achieve 10-15% waste rates—roughly half the industry average. The gap from 27% to 12% isn’t tooling; it’s discipline. A startup spending $10,000/month with 27% waste is burning $2,700/month on nothing. That’s $32,400 annually—three months of runway.
The Reserved Instance Paradox: Why 72% Savings Don’t Materialize
Reserved Instances and Savings Plans promise 50-72% discounts on compute. The marketing is relentless. Yet adoption remains catastrophically low. The reason: modern architectures evolve faster than multi-year commitments allow.
Usage shifts daily. Teams adopt new instance types. Containerization breaks EC2 Reserved Instance alignment. Lambda and Fargate don’t benefit from EC2 RIs at all. The result: stranded capacity, underutilized commitments, and the most common mistake—purchasing 3-year reservations for oversized instances, cementing waste into the budget. Once the reservation is made, organizations have no incentive to rightsize. The discount becomes a subsidy for inefficiency.
Usage AI’s analysis nails it: “AWS makes savings dependent on predictions no one can reliably make. Usage shifts daily, architectures evolve, and engineering teams adopt new compute types long before old commitments expire.” Duckbill Group notes EC2 Reserved Instances are being quietly deprecated because the RI model assumes environments stay predictable for years. Engineering teams don’t operate that way. Right-sizing, migrating to new instance families, shifting regions, or adopting containers breaks RI alignment instantly.
The marketing says “save 72%.” The reality: most teams can’t commit for 1-3 years without risking stranded capacity.
Provider Pricing Reality: AWS vs Azure vs GCP in 2026
Storage pricing varies by pennies, but pennies scale. Azure Blob Hot is cheapest at $0.018 per GB per month. Google Cloud Standard costs $0.020. AWS S3 Standard runs $0.023. For a company storing 100TB, that’s $1,800/month on Azure versus $2,300/month on AWS—$6,000 annually for identical functionality.
Compute discounts follow similar patterns according to CloudZero’s 2026 cloud pricing comparison. AWS and Azure both offer Reserved Instances with up to 72% savings, but require active commitment purchases. GCP applies sustained-use discounts automatically with no commitment—teams that can’t forecast usage for multi-year periods benefit from GCP’s approach. Azure Hybrid Benefit offers up to 85% savings for Microsoft-heavy organizations by leveraging existing licenses. That’s an unmatched advantage if you’re already paying for Microsoft infrastructure.
Market share reflects these trade-offs: AWS leads at 32%, Azure holds 23%, GCP captures 12%. Despite 89% of companies employing multi-cloud strategies, operational complexity often outweighs cost savings. Most “multi-cloud” deployments are actually multi-provider—one cloud for production, another for analytics or backup. Active multi-cloud orchestration adds overhead small teams underestimate.
Related: AWS, Google, Oracle Pick Valkey Over Redis: 33% Cheaper
Practical Optimization: How to Cut Waste from 27% to 10-15%
Well-managed organizations achieve 10-15% waste rates through monthly FinOps review processes, not superior tooling. The optimization hierarchy matters: eliminate idle resources first, then shutdown non-prod environments, then rightsize based on actual usage, and only then consider commitment-based discounts.
Idle resources are the low-hanging fruit. Instances running under 10% average CPU utilization over 30 days are waste. Unattached EBS volumes accumulate silently. Old snapshots older than 90 days serve no purpose. Cloud-cost-CLI and similar open source tools scan AWS, Azure, and GCP accounts to surface these opportunities, commonly identifying 20-40% savings potential.
Non-prod environments don’t need to run 24/7. AWS Instance Scheduler or simple cron jobs can auto-shutdown dev and staging environments nights and weekends, delivering 60% savings on those resources instantly. Spot instances work for batch jobs, ML training, and CI/CD runners—up to 90% off compute costs with the trade-off of potential interruption on 2-minute notice.
Storage lifecycle policies are set-it-and-forget-it optimization. S3 objects can auto-transition to Glacier after 90 days, cutting storage costs 30-50%. CloudWatch Logs exported to S3 after 7 days reduces expensive log retention charges. These aren’t one-time fixes—they’re structural improvements that compound monthly.
Organizations focusing only on deleting idle resources typically reduce costs by 10-20%. Teams that also optimize commitment coverage—after rightsizing first—can achieve 30-50% reductions without changing application code. The gap between 27% waste and 10-15% waste is roughly $1,700/month on a $10,000/month bill. That’s $20,400 annually—real money for startups.
Related: KKR’s $10B Helix: AI Infrastructure Goes Full-Stack
Key Takeaways
- SaaS companies spend 8-15% of revenue on cloud infrastructure (median 11.5%), with cost per employee ranging from $210/month (e-commerce) to $750/month (media). Benchmark your spend against these numbers to identify if you’re overspending.
- The average organization wastes 27% of cloud spend, with compute waste leading at 35%. Well-managed teams achieve 10-15% waste through monthly FinOps reviews—the gap is discipline, not tooling.
- Cloud costs scale with headcount, not usage. A 50-person company pays approximately 18x more than a 10-person team at the same revenue level due to environment sprawl (dev, staging, CI/CD, monitoring).
- Reserved Instances promise 50-72% savings but suffer from low adoption because modern architectures evolve faster than multi-year commitments allow. Stranded capacity is the real cost.
- Optimization hierarchy: eliminate idle resources (10-20% savings), shutdown non-prod nights/weekends (60% on those resources), rightsize based on actual usage, then—and only then—commit to Reserved Instances or Savings Plans.
Cloud cost benchmarks aren’t abstract metrics. They’re the reality check developers and CTOs need to answer “Are we overspending?” with concrete data. The 2026 numbers reveal the harsh math: 8-15% of revenue, 27% waste on average, and 18x scaling from 10 to 50 employees. Without benchmarks, teams fly blind. With them, optimization becomes engineering work—not guesswork.

