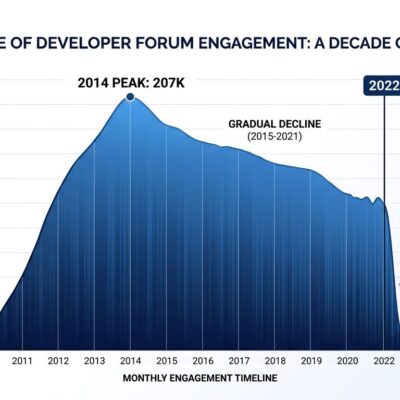
In July 2025, METR published a bombshell study: AI coding tools made experienced developers 19% slower, even though those same developers believed they were 20% faster. Seven months later, in February 2026, METR backtracked, admitting their methodology was fatally flawed—developers who benefit most from AI refused to participate in no-AI experiments, even at $50/hour. Their revised conclusion? “We don’t know if AI makes developers more productive.” That’s the AI coding productivity debate in a nutshell: 84% adoption based on vibes, not evidence.
We’re Terrible at Measuring Our Own Productivity
The METR study uncovered something more disturbing than whether AI tools work: developers are spectacularly bad at assessing their own productivity. Researchers tested 16 experienced open-source contributors—developers from repositories averaging 22,000 stars and over 1 million lines of code—on 246 real tasks from their own projects. The results revealed a 39-percentage-point gap between perception and reality.
Before the study, developers expected AI would make them 24% faster. After completing tasks with AI assistance, they estimated they were 20% faster. Objective measurements showed they were actually 19% slower. That’s a 39-point perception gap. If seasoned developers with years of expertise can’t accurately judge their own performance, every self-reported productivity claim becomes suspect.
This undermines the foundation of most AI coding tool marketing. McKinsey surveys developers: “Are you faster with AI?” Developers say yes. But METR proved we’re unreliable narrators of our own productivity. We feel fast during code generation, but we don’t properly account for the debugging time that comes later.
66% Say AI Solutions Are “Almost Right, But Not Quite”
Stack Overflow’s 2025 developer survey identified the core problem: 66% of developers cite “AI solutions that are almost right, but not quite” as their top frustration. This isn’t productivity—it’s productivity theater. Debugging plausible-looking incorrect code wastes more time than writing correct code from scratch.
The second-biggest frustration? Forty-five percent say “debugging AI-generated code is more time-consuming.” Meanwhile, 46% actively distrust AI accuracy, compared to just 33% who trust it. Only 3% report “high trust” in AI output. The numbers tell a consistent story: AI tools generate code that looks correct but contains subtle logical errors, security vulnerabilities, or architectural problems that surface later.
“Almost right” is worse than wrong. Wrong code fails tests immediately and forces you to rethink the approach. Almost-right code passes initial review, ships to production, and creates bugs that take hours to debug because you’re hunting for what’s wrong with plausible-looking code rather than solving a clear problem. The perception gap exists precisely because we feel fast during generation but don’t account for debugging compound interest.
The Evidence Contradictions: 46% Faster or 19% Slower?
We’re two years into mass AI coding tool adoption, and competing studies offer wildly contradictory findings. McKinsey claims 46% time savings on routine tasks from a February 2026 survey of 4,500+ developers. METR found 19% productivity loss, then retracted the finding due to methodological flaws. GitClear reports code quality collapsing with 4x more code cloning and 40% code churn. The industry can’t even agree on the direction of the effect, let alone the magnitude.
Consider the range: GitHub and Google claim 20-55% faster task completion. McKinsey says 46% time savings. Bain & Company describes real-world savings as “unremarkable.” METR measured 19% slower, then admitted their sample systematically excluded heavy AI adopters who refused to work without tools. GitClear shows delivery stability declining 7.2% for every 25% increase in AI adoption, with main branch success rates at a five-year low of 70.8%.
When studies disagree this dramatically, it means we don’t know. The contradictions suggest different researchers measure different things. McKinsey measures “time to write code.” GitClear measures “quality of code written.” METR measures “time to working solution including debugging.” All three could be correct because they’re measuring speed versus quality trade-offs. But we’ve adopted AI tools as if the question is settled. It isn’t.
84% Use AI Tools, 46% Distrust Them
Stack Overflow’s 2025 survey reveals a striking paradox: 84% of developers use or plan to use AI coding tools, yet 46% actively distrust their accuracy. We’ve adopted tools we don’t trust. Even more telling, positive sentiment is declining—down from 70%+ in 2023-2024 to just 60% in 2025. This isn’t enthusiasm. It’s FOMO.
Fifty-one percent use AI tools daily despite widespread distrust. Experienced developers are most skeptical: only 2.6% highly trust AI output, while 20% highly distrust it. Adoption isn’t driven by proven productivity gains—it’s driven by fear of falling behind. Developers use AI tools because they’re afraid not to, not because they’ve seen evidence the tools work. One METR study participant explained why they refused to participate without AI access: “My head’s going to explode if I try to do too much the old fashioned way because it’s like trying to get across the city walking when all of a sudden I was more used to taking an Uber.”
That quote encapsulates the problem. We’ve become dependent on tools before proving they’re effective. The declining sentiment indicates early enthusiasm is giving way to skepticism as the reality of “almost right but not quite” sets in. Adoption numbers look impressive until you realize they measure fear more than confidence.
The Bills Are Coming Due
GitClear’s analysis of 153 million lines of code shows AI-assisted development creating a quality crisis. Code churn jumped from 33% to 40%—meaning more code gets rewritten or deleted shortly after being written. Code cloning surged from 8.3% in 2020 to 12.3% in 2024, a 48% relative increase, with AI-assisted code showing 4x more duplication. By 2026, 75% of technology decision-makers face moderate-to-severe technical debt.
This is the lag effect in action. Productivity measured today—lines written per hour—doesn’t account for maintenance costs tomorrow. Time spent untangling duplicated code, fixing churned implementations, and debugging “almost right” solutions compounds over months and years. We’re entering the period where those bills come due.
The trade-off is now clear: AI tools may help write code faster, but that code is measurably worse. Delivery stability declines, success rates drop, and technical debt accumulates. McKinsey can claim 46% gains while GitClear reports quality collapse because they measure different time horizons. Short-term speed gains don’t account for long-term maintenance costs.
Key Takeaways
- The METR study saga exposes a fundamental problem: developers believed they were 20% faster with AI while objectively testing 19% slower—a 39-point perception gap that undermines all self-reported productivity claims.
- Sixty-six percent of developers cite “AI solutions that are almost right, but not quite” as their top frustration, revealing why speed gains don’t translate to productivity—debugging plausible-looking incorrect code wastes more time than writing from scratch.
- Competing studies offer contradictory findings (McKinsey: 46% faster, METR: 19% slower, GitClear: quality collapse) because they measure different trade-offs—we’re optimizing for code generation speed while ignoring quality, debugging time, and maintenance costs.
- Eighty-four percent adoption coupled with 46% active distrust and declining positive sentiment (70%+ to 60%) proves adoption is driven by FOMO, not proven productivity gains.
- GitClear’s quality metrics (40% code churn, 4x code cloning, 70.8% stability at 5-year low) show we’re trading short-term speed for long-term technical debt—the bills are coming due as early enthusiasm gives way to maintenance reality.
The industry rushed to declare AI coding tools essential before answering basic questions about whether they work. The METR flip-flop proves even researchers studying productivity can’t avoid selection bias. Stop optimizing on vibes. Run your own experiments. Measure objectively. And be skeptical of any claim—positive or negative—that doesn’t account for the 39-point gap between how fast we feel and how fast we actually are.