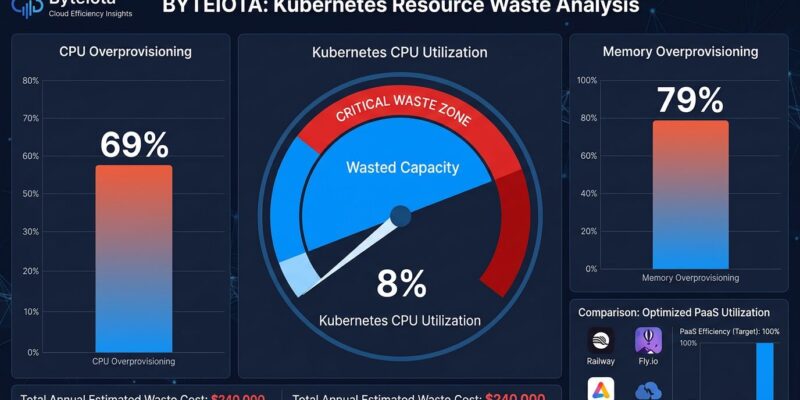
The CAST AI 2026 State of Kubernetes Optimization Report analyzed tens of thousands of Kubernetes clusters and found average CPU utilization at 8%—down from 10% the previous year. That’s not a typo. Teams are running infrastructure at 10x overcapacity, with 69% CPU overprovisioning and 79% memory overprovisioning across 2,000+ organizations. If your Kubernetes cluster runs at 8% CPU utilization, you didn’t need Kubernetes. You needed a simpler deployment platform.
The Utilization Scandal Nobody Talks About
The numbers from CAST AI’s analysis of tens of thousands of clusters across AWS, GCP, and Azure reveal a systematic problem: teams pad resource requests to avoid throttling and OOM errors, but the cost of that padding is invisible to the platform team. There’s no systematic process to revisit those definitions after deployment. The result? Roughly 70% of requested CPU sits idle. Memory utilization at 20% tells the same story. GPU utilization for AI workloads hits 5%—even worse.
This isn’t just waste. It’s proof that most teams adopted Kubernetes without operating at the scale Kubernetes is designed for. Year-over-year, the problem is getting worse. CPU overprovisioning jumped from 40% to 69%. Teams aren’t learning to optimize—they’re doubling down on overcapacity.
The Operational Complexity Tax
Underutilization is the symptom. The disease is operational complexity. Nearly 80% of Kubernetes incidents are caused by operational complexity, not infrastructure failures. Kubernetes engineers are extremely desirable but very expensive. Without a dedicated platform team, developers deal with Kubernetes complexity instead of shipping features. McKinsey observed that complexity introduced by modern architectures often outpaces the organization’s ability to manage it.
A Hacker News case study from January 2026 put numbers to the pain: an 8-engineer team spent 60 hours per week managing Kubernetes. They moved to Docker Compose and saved 60 hours per week with no loss of functionality. That’s an entire full-time role reclaimed from infrastructure management. The operational overhead—containers, orchestration, service meshes, API gateways, observability platforms—becomes the product instead of supporting the product.
The hidden costs compound. Keeping clusters patched, upgrading versions, rotating certificates. Third-party tools for backup, disaster recovery, automation. Each adds subscriptions and maintenance burden. As cluster count increases, complexity grows non-linearly. Without cost intelligence, 30-40% of Kubernetes cloud spend is typically wasted.
Who Actually Needs Kubernetes
Kubernetes is designed for configurations that meet specific criteria: up to 5,000 nodes, 150,000 total pods, 300,000 total containers. Multi-cluster architecture for global workloads, regulatory requirements, hybrid infrastructure strategies. If you’re operating at Top 100 website scale, running custom GPU training farms, or managing dozens of services with dedicated platform teams, Kubernetes delivers value. The complexity pays for itself.
For everyone else—small teams, fewer than 20 services, single-region deployments, no dedicated DevOps staff—the complexity doesn’t pay. Speed matters more than flexibility. A straightforward product doesn’t need orchestration designed for Google-scale infrastructure.
The data supports this. The CNCF 2025 survey found 42% of organizations that adopted microservices are consolidating services back to larger deployable units. Service mesh adoption declined from 18% in Q3 2023 to 8% in Q3 2025. Teams are rejecting distributed complexity. The Hacker News consensus from multiple threads: “Kubernetes is overkill for 90% of systems.”
The PaaS-First Alternative
In 2026, the question changed. Not “should I use Kubernetes?” but “have I demonstrated I need Kubernetes?” The PaaS-first movement positions Kubernetes as the exception, not the default. For 90% of teams, PaaS platforms deliver faster feature velocity without infrastructure management.
Railway offers arguably the best developer experience: push code, it deploys. Fly.io provides multi-region infrastructure without managing Kubernetes clusters, ideal when latency to users is a first-class requirement. Render lets teams configure scaling rules at accessible pricing. Qovery abstracts Kubernetes complexity while deploying on your own cloud accounts—Kubernetes power without Kubernetes overhead.
The tradeoff is clear. Small and mid-size teams shipping features fast choose Railway or Render. Multi-region with low latency needs choose Fly.io. Teams that want Kubernetes flexibility without managing it choose Qovery. Demonstrated need for 5,000+ nodes? That’s when raw Kubernetes makes sense.
Why Kubernetes Became the Default (When It Shouldn’t)
Cloud-native evangelism positioned Kubernetes as best practice. Fear of outgrowing simpler solutions drove adoption—”we’ll need it eventually.” Resume-driven development played a role: engineers wanted Kubernetes on their CV. Vendors pushed complexity with warnings that starting simple would create regret later.
The reality is that most teams never reach the scale where Kubernetes pays off. The 8% CPU utilization proves adoption wasn’t based on demonstrated need. Simpler solutions—PaaS, Docker Compose—work for 90% of use cases. Premature optimization for scale that never materializes is still premature optimization.
Engineers aren’t anti-microservices or anti-Kubernetes. They’re anti-unnecessary complexity. When a team spends 60 hours per week managing infrastructure instead of building features, the novelty wears off. When 8% CPU utilization reveals you’re paying for 12x the infrastructure you use, the calculation changes.
Start Simple, Add Complexity When Demonstrated
Kubernetes is brilliant engineering for massive scale. But 8% CPU utilization across tens of thousands of clusters proves most teams don’t operate at that scale. The PaaS-first approach is the sensible default for 2026: deploy without managing infrastructure, focus on code, ship features fast. When you demonstrate you’ve outgrown PaaS—when you’re actually running dozens of services, managing global workloads, or hitting 5,000+ nodes—that’s when Kubernetes makes sense.
Until then, the best architecture is the one that ships features fastest. Not the one with the most impressive infrastructure diagram.