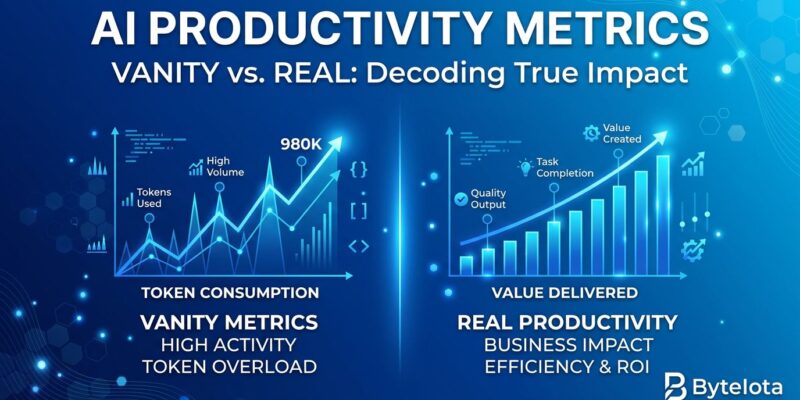
Tokenmaxxing is the “lines of code” vanity metric reborn. Thirty years ago, the industry learned measuring productivity by lines of code was foolish—more code didn’t mean better software, just more code. Now we’re repeating the mistake with AI tokens. Companies track how many tokens developers consume (the AI processing units determining costs) as a productivity proxy. More tokens equals more AI help equals more productive, right? Wrong.
Research analyzing 22,000 developers shows engineers with the highest token budgets achieved 2x throughput at 10x cost, with 54% more bugs, 861% code churn, and review times that increased 5x. We learned this lesson once. Why are we learning it again?
What Is Tokenmaxxing?
Tokenmaxxing happens when companies treat AI token consumption as a productivity metric. Tokens are small chunks of text AI models process—roughly four characters per token. Companies originally tracked token usage to measure costs. However, someone had an idea: what if token consumption also measured developer productivity? The more tokens you burn, the more productive you must be.
This isn’t hypothetical. Meta burned through 60.2 trillion tokens in 30 days—an estimated $100 million cost—before their internal leaderboard leaked to the press and got shut down. Salesforce sets minimum spending targets of $70-100 per month per developer. Microsoft engineers rack up charges asking AI redundant questions instead of reading documentation. Companies build internal leaderboards and public dashboards showing peer usage averages, creating competitive dynamics where low token consumption signals you’re “not embracing AI.”
The Data Exposes the Tokenmaxxing Problem
Two major studies reveal tokenmaxxing’s fatal flaw: it optimizes for activity, not results.
Faros AI analyzed 22,000 developers across 4,000 teams over two years. The throughput metrics look good on paper: task completion up 34%, epics up 66%, code-specific tasks up 210%. Nevertheless, the quality metrics tell a different story. Bugs per developer jumped 54%. Code churn—lines deleted versus lines added—exploded 861%. Median review time increased 5x. The incident-to-PR ratio tripled. More code ships faster, but it breaks more often, takes longer to review, and gets rewritten at nearly nine times the normal rate.
Jellyfish studied 7,548 engineers in Q1 2026 to measure cost-effectiveness. Developers in the bottom 20% of token consumption spent $3 per quarter and shipped 11 merged PRs on average—that’s $0.28 per merged PR. Developers in the top 20% spent $1,822 per quarter and shipped 23 merged PRs—that’s $89.32 per merged PR. The highest token consumers produced 2x throughput at 10x cost per PR. The productivity gain isn’t proportional to token spend.
Here’s the hidden problem: managers see 80-90% initial code acceptance rates. Developers approve and keep AI-generated code at that rate. But when engineers revise that code in the following weeks, the real-world acceptance rate drops to 10-30%. That means 70-80% of “accepted” code gets rewritten or deleted. The initial velocity managers celebrate creates downstream problems they don’t measure.
Why Smart People Fall for Tokenmaxxing
Tokenmaxxing persists because it exploits normal organizational dynamics.
Companies face measurement pressure. They invested heavily in AI tools and want measurable ROI. Tokens are easy to track—every API call gets logged. However, business outcomes like code quality and maintainability are harder to measure. When executives ask “Are developers using the AI tools we bought?” token consumption provides an immediate answer.
Internal leaderboards create competitive dynamics. Developers see peer usage on dashboards. Consequently, low token consumption looks like you’re “not embracing AI” or “falling behind.” This hits junior engineers hardest—they accept far more AI-generated code and deal with the most rework later, but they feel pressure to participate to avoid being tagged as insufficiently “AI-native.”
Moreover, tokenmaxxing is easy to game. Just like lines of code before it. Run agents overnight producing throwaway work. Ask AI redundant questions instead of reading documentation. Over-prompt simple tasks. Calibrate usage to peer averages regardless of need. The metric measures activity, so gaming it just requires more activity.
The Real Cost of AI Productivity Metrics
Tokenmaxxing’s downstream costs far exceed its initial velocity gains.
The 861% code churn creates massive technical debt. Code written today gets deleted or rewritten within weeks. Initial velocity creates future slowdown. The quality degradation compounds: 54% more bugs, incident rates tripling, 31% more PRs merging without review because teams can’t keep up with the volume. Furthermore, review times increase 5x because there’s more code to review, lower quality requires deeper scrutiny, and AI-generated code is harder to evaluate.
The financial waste is measurable. Cost per merged PR jumped from $0.28 to $89.32. Meta’s estimated $100 million token spend in one month. Salesforce’s minimum spending targets pushing developers to hit quotas regardless of need.
Then there’s cognitive overload. Developers report “brain fry” from continuous prompting. Burnout from managing AI agents. “Token anxiety” about consumption targets. The tools were supposed to reduce cognitive load. Tokenmaxxing turns them into stressors.
What to Measure Instead of Token Consumption
Stop measuring inputs. Start measuring outcomes.
Don’t track token consumption, AI tool usage frequency, or number of AI-generated PRs. Instead, track code that survives revision—the real acceptance rate, not the initial one. Measure bugs per feature shipped, not bugs per developer in isolation. Track time to working solution, not time to first draft. Monitor long-term velocity across quarters, not just sprint throughput.
Shopify provides a model. They renamed “leaderboards” to neutral “usage dashboards,” removing competitive framing. They implemented circuit breakers detecting runaway agents burning tokens on low-value work. Leadership reviews high spenders with context—are they solving hard problems or gaming metrics? They focus on expensive tokens (complex operations that genuinely need AI) rather than volume.
Measure throughput, efficiency, and quality together. Optimizing one dimension destroys others. As Pragmatic Engineer Gergely Orosz put it: “The number of tokens a dev generates can easily be gamed without corresponding business benefit.”
History Doesn’t Have to Repeat
We learned this lesson with lines of code. Measuring activity instead of value always fails. More code didn’t make better software. More tokens don’t make better developers.
Token consumption is an input, not an outcome. It measures AI usage, not productivity. AI is a tool. Using more of a tool doesn’t automatically mean you’re better at your job. A carpenter who uses twice as many nails isn’t necessarily twice as productive—maybe they’re just wasting nails.
The data is clear. Tokenmaxxing produces 2x throughput at 10x cost, with quality degradation that creates future slowdown. Junior developers bear the brunt, accepting more AI code and facing more rework. Companies waste millions on token spend chasing a metric that can be gamed. Review cycles slow to a crawl. Technical debt accumulates faster than teams can pay it down.
We don’t have to repeat this mistake. Measure what matters: code that works, problems solved, value delivered. Not tokens burned, prompts submitted, or AI calls made.
Thirty years ago we learned that lines of code was a vanity metric. We can learn faster this time.