

Masked Face Verification
What is Masked Face Verification?
Face Verification is the process of authenticating the person in a given image. It is one of the steps of Face Recognition. With the tremendous development in the domain of Computer Vision, we have come to a point where we use Face Verification Systems in our day-to-day lives; for example, automated attendance systems, activity trackers, finding a missing person, etc. We have numerous techniques at our disposal to deal with these tasks of Face Verification. Masked Face Verification is an extended version of Face Verification where people have their masks on.
Read more about Face Recognition and learn how to build your model: Face Recognition using Python, OpenCV and One-Shot Learning | byteiota
Why do we need Masked Face Verification?
With the rise of covid and the recent Omicron variant, it is uncertain when can we take a break from wearing masks. It has become a necessity, perhaps even more than our mobile devices while stepping out. Most of the Face Verification models provide an accuracy close to 100% on unmasked faces. However, these models fail when it comes to masked faces.
We experience this issue because the models are not trained to deal with masked faces. Adding a mask covers most of the facial features that the models rely upon. However, as we may see further, some models do not suffer from this issue and with very minor changes to the existing model, it can provide great results for the masked face as well.
In this blog, we will explore how the existing models perform with the masked faces. Moreover, we retrain some of the models to deal with a generalized scenario: masked + unmasked; i.e. the models will be trained on a dataset consisting of both, masked and unmasked images. We then evaluate how well the models hold with the generalized condition and whether they can be reliable enough to introduce to our existing systems.
What models are we going to cover?
For analysis, we’ve picked some common Face Verification models that allow fine-tuning on the go:
We’ll be using Transfer Learning to use these pre-trained models for unmasked faces and fine-tune them for our use case (combined data).
Note: Other models such as Facebook DeepFace, OpenFace and ArcFace are very common in use as well. However, fine-tuning them is not convenient and hence we do not consider them.
A priori questions
Before we begin, we need to lay down a few questions that we hope to answer by the end.
- Can a generalized model provide an acceptable accuracy?
- Will generalizing the dataset improve or degrade the robustness to external noise? For example lighting conditions, viewing angles
- Out of all the models, will some models have an edge? If yes, why so?
- Are all the models scalable? Or would they perform better with a smaller number of people (a group of 15-20 people)
- How well do these generalized models hold in real-world experimentation?
Existing Analysis on Masked Face Verification
In Efficient Masked Face Recognition Method during the COVID-19 Pandemic, Walid Hariri address some techniques that one can adopt to change the models to work with the Masked Faces. Using the quantization mentioned in the paper, we can produce great accuracies on the Masked Faces. On RMFRD (Real-world Masked Face Recognition Dataset), the paper achieves a score of 91.3% while also improving the inference times. However, the major issue that the paper does not address is after re-training the model with masked faces, how well can it perform with unmasked faces?
Although one may argue on having 2 Face Verification models and running a Mask detector on top of it.
- If the person is wearing a mask: run Masked Face Verification
- If the person is not wearing a mask: run traditional Face Verification
However, one fails to consider the resources required for 3 models. We see a high implementation of Face Verification models due to the lightness of the models. On the other hand, an object detector like Face Mask Detection is heavy in terms of resources even for inference. It may not be practical to incorporate a Face Mask Detector along with 2 Face Verification models.
Moreover, it is intriguing to find out if we can build a generalized model without changing the existing feature extractors marginally.
Read more about how to build a Face Mask Detector: Train An Object Detection Model using Tensorflow on Colab | byteiota
Datasets for Masked Face Verification
The fuel for every Deep Learning task is the dataset used for training. A good dataset can give excellent results, whereas a noisy dataset could create a model worse than a random “True/ False” program. Moreover, it is necessary to work with common datasets for analysis as it is easier to compare the results of the existing models on them.
For fine-tuning our models, we’ll be using the following datasets.
LFW (Labelled Faces in the Wild):

LFW – LFW Face Database: Main (umass.edu) is a widely used image dataset for Face Verification tasks. Multiple models have reported their SOTA accuracies on this dataset. Moreover, we can find framework support for LFW built-in. This makes it an ideal choice of the dataset for fine-tuning and evaluation of our unmasked set.
LFW information:
- 13233 images – faces collected from the internet
- 5749 people with 1680 people having two or more than 2 images
The aligned faces for LFW were generated using Deep Funneling.
MLFW (Masked Labelled Faces in the Wild):

MLFW – Masked LFW (MLFW) Database (whdeng.cn) is a synthetic dataset generated by applying data augmentation techniques on CALFW dataset. The dataset aims to provide a base ground for comparison of how the Face Recognition/ Face Verification models perform after the introduction of masks. A few of the cases covered by the augmentation are as follows:
- A person wearing masks in different orientations
- A person wearing masks of different colors
- Multiple persons wearing similar masks
Since both datasets consist of similar images, it is easier to evaluate the performance of the models.
MLFW information:
- 12000 images
- 2996 people with 2984 people having two or more than 2 images
To keep fairness among the models, the dataset faces are recognized/ extracted using MTCNN.
Note: MLFW images come pre-aligned as well.
We’ll be combining both datasets as our final dataset. Both datasets consist of “pairs” of images where a positive pair represents that the images belong to the same person and a negative pair represents that the images belong to different persons. We’ll make a balanced train-test split using these pairs. The train split will be used to fine-tune the models and the test will be used for evaluation.
Models for Masked Face Verification
Google FaceNet
FaceNet: A Unified Embedding for Face Recognition and Clustering, aims at generating face embeddings for a given face that can be extracted to simplify the tasks of face recognition, verification and clustering. It computes the facial features and converts them in a Euclidean space which makes it very easy to find similarities between two images. This approach is rather impressive for the tasks of Face Verification as it directly compares 2 images and decides whether they belong to the same person or not.
There are multiple pre-trained models. The most common ones are given below with their LFW accuracies.
Source: davidsandberg/facenet: Face recognition using Tensorflow (github.com)
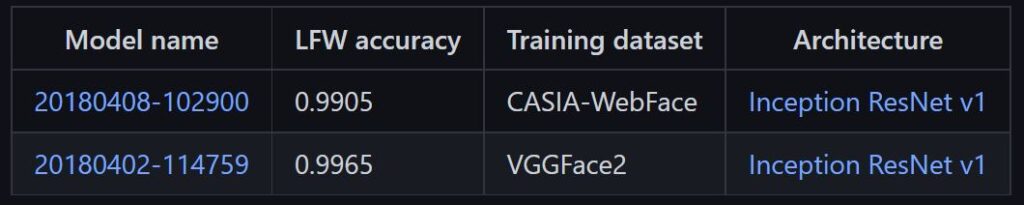
Dlib
Dlib is one of the earlier models to be widely used for Face Recognition. Based on Landmark detection techniques, Dlib attempts to map 68 points, representing a face in a given image. Dlib model is inspired by ResNet-34. Initially, dlib was built for C++, but given its efficiency and performance, it was later wrapped for python as a C++ toolkit.
Accuracy on LFW: 98.4%
VGGFace2
VGGFace2 refers to a set of models trained on the dataset created by a group named VGG (Visual Geometry Group). VGGFace dataset is a large dataset of faces with over 9000 identities and 3.31 million images. The major model used is a ResNet-50 trained on VGGFace dataset. Since it is widely available and allows fine-tuning of the models, we select this as one of our models for comparison
Accuracy on LFW: 99.50%
Source: Training using the VGGFace2 dataset – davidsandberg/facenet Wiki (github-wiki-see.page)
ArcFace
While all the models focus on improving the network and the dataset for training, ArcFace attempts for an improvement in the loss function for the CNN. In the paper, we see the authors making use of Additive Angular Margin Loss instead of regular loss. This helps capture the geospatial discriminative features from the face due to their geometry. ArcFace has been one of the best SOTA models for a while and have shown great performance.
Accuracy on LFW: 99.80%
Source: chenggongliang/arcface (github.com)
Implementation
To keep this blog within the scope of analysis only, we do not cover the implementation here. However, you may find the implementation in the Google Colab link below
Google Colab Link: Masked Face Verification
The implementation can be broken into the following parts:
- Data Preprocessing: Merging the LFW and MLFW datasets and their corresponding pairs to create a train/ test split
- Aggregated Verification: Running verification task by aggregating it over top 3 images per class
- Evaluation: Once the verification is complete, we then run evaluation on our test split
In the future, we might post another blog focusing on the implementation. Subscribe to the newsletter to get updates on our upcoming posts!
Evaluation of Masked Face Verification
To evaluate our models, we run the models on our test dataset to find the following metrics:
- Performance / Accuracy: How good the models perform given the constraint of a generalized model.
- Size of the Model: These models are generally deployed on mobile devices with fewer resources or in embedded systems. Hence, the models must be light in weight.
- Inference Time: How long does the model take to detect the person with acceptable accuracy. We will be measuring inference time for 10000 images and average it to get the results.
- Training / Retraining Time: Having faster training times allows new users to register on the go and thus improves the scalability of the models. This is the time taken to reach X% (INSERT X HERE) accuracy on the validation set.
Firstly, we use the base models to see how well they perform with our new dataset. This can give us a solid baseline to compare the improvement of our fine-tuned model.
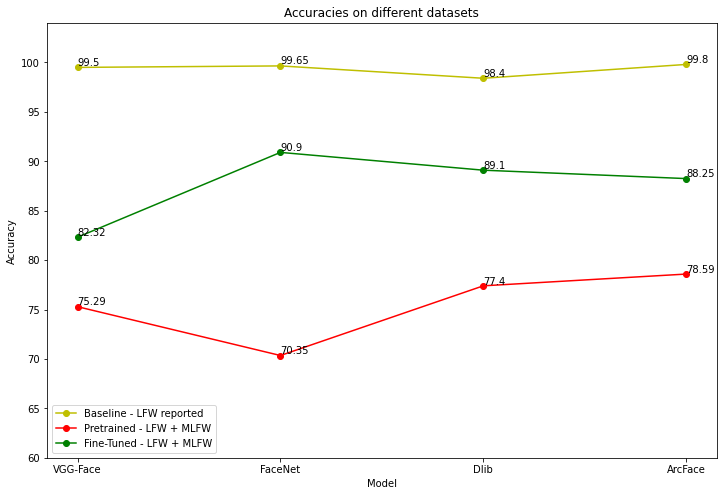
Now, using the above metrics we have our results for before and after fine-tuning:
Accuracy:
| LFW (pre-trained) | LFW + MLFW (pre-trained) | LFW + MLFW (fine-tuned) | |
| VGG-Face | 99.50% | 75.29% | 82.32% |
| FaceNet | 99.65% | 70.35% | 90.90% |
| Dlib | 98.40% | 77.40% | 89.13% |
| ArcFace | 99.80% | 78.59% | 88.25% |
NOTE: The following graph is plotted using VAGUE values for Pretrained and Fine-tuned (green and red lines). This will be updated once the final results come from the trained models.
Evaluation Metrics:
| Model Size | Inference Time – baseline (in sec) | Inference Time -aggregated (in sec) | |
| VGG-Face | 566 | 0.1535 | 1.384 |
| FaceNet | 90 | 0.118 | 0.975 |
| Dlib | 20 | 0.043 | 0.279 |
| ArcFace | 133 | 0.129 | 0.853 |
Insert Evaluation Bar Graph (this will be added once results are in)
These metrics are independent of the dataset, although they were measured for the fine-tuned model using the combined LFW + MLFW dataset.
Solution
With the experimentation and the evaluation results above, we see how a pre-trained model can be used with aggregation to work with Masked faces as well. One suggested approach to incorporate the models in daily applications is as follows:
- When a user uploads/ adds his train image, apply a synthetic mask on the face.
- Later, modify the original face with noise and reapply another mask.
- This gives us 4 images: 2 masked, 2 unmasked
- Use these images as train set for aggregated verification of masked/ unmasked face
Conclusion
Given the uncertainty on COVID will end, it is clear that we would be using masks in our day to day lives for a while. This requires a need for further development in building Face Embeddings that can detect not only masked faces but unmasked faces as well.
While we did manage to get a good accuracy, we see a very high increase in inference time with our approach of Aggregated Verification. This makes it less likely to be used for applications that demand for quick inference like mobile devices. However, for applications that may not require such high-speed verification, it is possible to integrate Masked Face Verification in our daily usage.
After reviewing all the recent work going in the field, and doing our own analysis, we can say that while Masked Face Verification can be achieved through various methods, we still need to find a robust solution that is also light in weight.
A working web demo for the current Masked Face Verification can be found in our next blog.
Similar Reads
- Face Recognition using Python, OpenCV and One-Shot Learning | byteiota
- Train An Object Detection Model using Tensorflow on Colab | byteiota
References
- Efficient Masked Face Recognition Method during the COVID-19 Pandemic
- Google FaceNet – davidsandberg/facenet: Face recognition using Tensorflow (github.com)
- Facebook DeepFace – serengil/deepface: A Lightweight Face Recognition and Facial Attribute Analysis (Age, Gender, Emotion and Race) Library for Python (github.com)
- Dlib – C
- king09a.pdf (jmlr.org)
- [1710.08092] VGGFace2: A dataset for recognising faces across pose and age (arxiv.org)
- OpenFace (cmusatyalab.github.io) – cmusatyalab/openface: Face recognition with deep neural networks. (github.com)
- [1801.07698] ArcFace: Additive Angular Margin Loss for Deep Face Recognition (arxiv.org) – chenggongliang/arcface (github.com)
- ipazc/mtcnn: MTCNN face detection implementation for TensorFlow, as a PIP package. (github.com)
- LFW Face Database: Main (umass.edu)
- LFW Aligned images: Gary B. Huang, Marwan Mattar, Honglak Lee, and Erik Learned-Miller. Learning to Align from Scratch. Advances in Neural Information Processing Systems (NIPS), 2012.
- Chengrui Wang and Han Fang and Yaoyao Zhong and Weihong Deng, MLFW: A Database for Face Recognition on Masked Faces, arXiv preprint arXiv:2108.07189.
- Featured Image: Facial Recognition Software Trying to Catch Up With Face Masks (interestingengineering.com)









