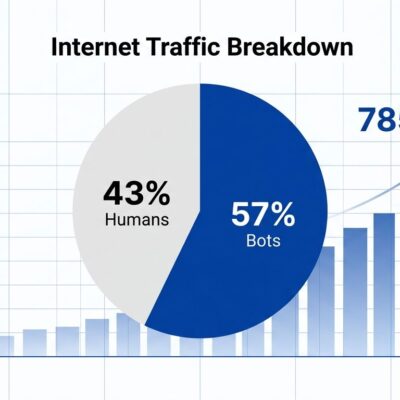
AI coding tools generate 42% of all code in 2026, and they’ve cut PR cycle times by 20%. Developers ship faster than ever. But here’s the uncomfortable truth buried in the 2026 benchmarks: production incidents jumped 23.5%, failure rates climbed 30%, and AI-generated code creates 1.7 times more issues than human-written code. The productivity paradox is real—teams are moving faster while building more fragile software.
The Paradox in Numbers
The speed gains are undeniable. Pull request cycle times dropped from 9.6 days to 2.4 days—a 75% reduction. Teams using AI tools merged 98% more PRs and completed 21% more tasks. Industry benchmarks show developers average 12 points per week on AI-assisted work versus 8 points without AI.
But the quality costs tell a different story. Production incidents increased 23.5% in 2026. Change failure rates climbed 30%. AI-generated code creates 1.7 times more issues than human code, with correctness problems 1.75x higher, maintainability issues 1.64x higher, and security flaws 1.57x higher.
The most troubling metric: 60% of AI faults are silent failures. They pass tests. They clear code review. They fail in production on edge cases no one anticipated. And here’s the kicker—75% of developers manually review AI-generated code, yet incidents still rose 23.5%. Review isn’t catching the problems.
The math reveals why: teams merged 98% more pull requests, but PR review time increased 91%. Developers ship twice as fast but spend twice as long reviewing. The bottleneck shifted from writing code to verifying it. That’s not productivity—that’s shuffling the deck chairs.
The Safe Zone vs the Danger Zone
Industry benchmarks in 2026 identify a sustainable range: 25-40% AI-generated code. Stay within this zone, and teams see genuine productivity gains without significant quality degradation. Cross 40%, and technical debt grows 30-41% within 90 days. Static analysis warnings spike 4.94x. Code complexity increases 3.28x.
Above 50% AI code share, you’re in the danger zone. Rework rates jump 20-25%. Review times balloon. Bug rates climb. The speed gains evaporate as teams spend more time fixing what shipped than they saved writing it.
Elite engineering teams push higher—60-75% AI code share—but only because they have the foundation to catch issues early. These are DORA high performers with robust CI/CD pipelines, comprehensive test coverage, and disciplined refactoring practices. They’re not breaking the rules; they’re proving that strong engineering fundamentals let you push AI harder.
For everyone else, the message is clear: measure your AI code percentage. Set alerts when you cross 40%. Don’t ban AI above that threshold—but enforce stronger quality gates. Run additional static analysis. Require more extensive testing. Increase review rigor. The threshold isn’t a hard limit; it’s a signal to adjust your guardrails.
The Real Cost Nobody Talks About
GitHub Copilot costs $20-60 per month. Cursor is $20. Claude Code starts at $20. Teams budget for seat licenses and think they’re done.
Then the token bills arrive.
Agentic AI coding tools burn $200-2,000 per engineer per month in token costs—on top of those seat licenses. A 30-developer team with 10 heavy AI users averages $309 per month per developer. During intensive refactoring sprints, that spikes to $800+. Token-based tools create unpredictable OpEx swings of $500-1,500 per developer monthly.
By late 2026, industry analysis shows 20-30% of total engineering operational expenses will flow to AI tooling. That’s not a rounding error. That’s a line item competing with cloud infrastructure and SaaS platforms.
And that’s just the direct costs. Factor in incident response—the time spent investigating, debugging, and fixing the 23.5% increase in production issues—and the ROI calculation gets murkier. Are you saving 4 hours per week per developer on coding, only to spend 6 hours responding to production incidents caused by AI code that passed review?
Token costs need monitoring, caps, and ROI measurement that includes downstream effects. Ninety percent of developers spend under $12 daily (roughly $360 monthly), but power users running complex agentic workflows blow past these averages. Budget for reality, not marketing materials.
What Elite Teams Do Differently
The teams seeing sustained AI gains were already high-performing before AI adoption. They had test-driven development, continuous integration, disciplined refactoring, and strong code review cultures. AI amplified their capabilities. For teams without that foundation, AI amplified their dysfunction.
Elite teams practice context engineering—structuring information so AI assistants produce better code. They use AGENTS.md files with architectural guardrails, maintain up-to-date specifications, and provide AI with clear constraints. They don’t throw AI at a messy codebase and hope for the best.
They also apply tiered rigor. Not all code is equal. Disposable prototypes get one quality bar. Production-critical systems get another. Elite teams adjust their AI usage and review processes based on risk, not blanket policies.
And they measure beyond velocity. They track bug rates in AI-generated code versus human code. They monitor change failure rates. They measure time spent in incident response. They know which AI tools produce the best results for which tasks. Senior engineers see 5x productivity gains versus juniors using the same AI tools—experience and judgment still matter.
You can’t AI your way out of poor engineering practices. Fix your foundation first. Then AI becomes a multiplier instead of a chaos accelerator.
2026: The Year of AI Quality
2025 was the year of AI speed. Every vendor marketed faster shipping, 10x productivity, and developer superpowers. Teams adopted AI everywhere, optimizing for velocity.
2026 is the year of AI quality. The industry hit the quality wall. Incident rates climbed. Technical debt ballooned. Teams realized that shipping faster doesn’t mean shipping better.
Governance is emerging. Engineering leaders now set AI code thresholds, not bans. They demand granular visibility—which commits involve AI, which tools produce the best code, how AI-generated code performs over time. They’re building quality gates specifically for AI code: additional static analysis, extended test coverage, stricter review requirements above certain AI percentage thresholds.
The paradox won’t solve itself. Faster PRs and more bugs is the default outcome without deliberate intervention. Teams need to measure AI code percentage, track downstream quality effects, set sustainable thresholds, and enforce quality gates when crossing them.
The data is clear: 42% of code is AI-generated, and the industry hasn’t figured out how to maintain quality at that scale. The teams that crack this—balancing speed and quality, measuring beyond velocity, governing AI deliberately—will pull ahead. The teams that keep chasing speed alone will drown in technical debt and incident response.
The paradox is real. The question is whether your team will acknowledge it before the quality costs overtake the speed gains.