A new arXiv paper published this month gives AI coding tool skeptics the hard data they’ve been waiting for. Researchers evaluated 10 language models across 8 web frameworks on 100 backend code generation tasks — and found that capable agents lose an average of 30 percentage points in correctness as real-world architectural constraints accumulate. They call it “constraint decay,” and it explains something developers have sensed for two years without being able to prove: these tools work beautifully until your codebase gets serious.
What Constraint Decay Means for LLM Agents
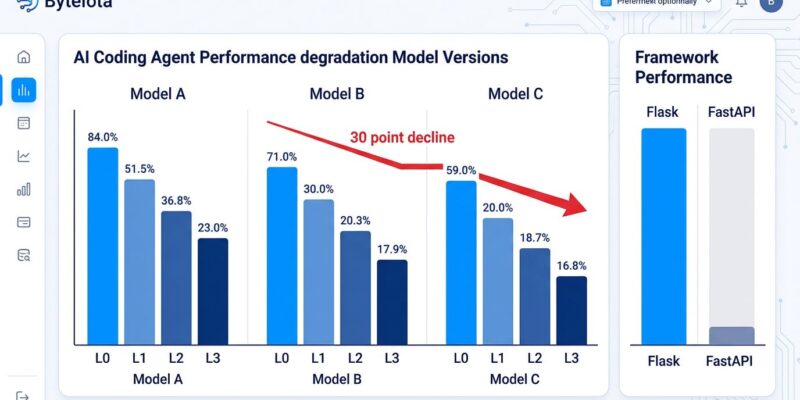
The research team structured their benchmark in four constraint levels: L0 (framework only), L1 (plus Clean Architecture), L2 (plus a database specification), and L3 (plus an ORM layer). Each level represents requirements that are completely standard in any real production backend. None of these are exotic. If you’re shipping a Django or FastAPI app with SQLAlchemy and a database schema, you’re working at L3 — the fully constrained tier where performance falls off a cliff.
At L0, top-performing models score above 80% assertion pass rates. By L3, the same models drop to between 23% and 47%. The worst performer, OpenHands running Qwen3-Coder-Next, lost 45 percentage points — a 62% relative decline from its unconstrained baseline. For context, that model would ace most coding benchmarks. Benchmarks, of course, are not production backends.
The individual constraint penalties reveal where the damage concentrates. According to the full paper (arXiv 2605.06445), database specification alone costs agents 19.3 percentage points. SQLite requirements add another 14.3 points. Clean Architecture patterns add 9.1. ORMs — often blamed first — are surprisingly mild in isolation (−1.5 pp for SQLAlchemy), but they compound everything else. The database constraint is the killer, and you cannot ship a production web service without one.
Why FastAPI and Django Hurt AI Coding Agent Performance Most
The framework performance split is sharp. Flask, Express, and Koa cluster around 49–51% average pass rates. FastAPI and Django sit at 24–25%. Hono bottoms out at 18.5%. That’s a 25-point gap between the best and worst performers using identical models and identical task requirements. The difference isn’t documentation quality or ecosystem size — it’s implicit conventions.
Convention-heavy frameworks punish agents because their implicit rules are never stated in the prompt. Django’s auto-discovery assumes you know where apps live, how settings resolve, and how migrations connect to models. FastAPI’s type-hint-driven validation expects specific Pydantic schema patterns and dependency injection conventions. Agents trained on code corpora can approximate these patterns — but under full constraint pressure, the approximations break down. The irony is that the same conventions that make Django and FastAPI productive for experienced developers are invisible traps for models generating code from scratch.
Related: Google CodeMender: The AI Agent That Patches Your Code Before You File a Ticket
The Failure Mode You Won’t Catch in Code Review
The most dangerous finding isn’t the performance numbers — it’s the failure distribution. Of 194 failed runs analyzed, 70.6% were logic errors: the server started, the code compiled, and the application returned wrong results. Only 12.4% were startup failures — the obvious kind. Data-layer defects, including wrong query logic and ORM runtime violations, account for roughly 45% of all failures.
This failure pattern explains precisely why the 96% of developers who don’t fully trust AI-generated code aren’t being paranoid. Constraint decay isn’t triggering visible crashes — it’s producing code that behaves incorrectly under specific database conditions, specific query shapes, specific ORM configurations. A VentureBeat survey found 43% of AI-generated code changes require debugging in production even after passing QA. Constraint decay is where those bugs are hiding: in the data layer, surfacing only under real conditions.
Teams reviewing AI code with a focus on syntax correctness will miss this entirely. The code looks right. The ORM call looks plausible. The query looks valid. The error shows up in logs at 2 AM when a specific JOIN condition hits an edge case that wasn’t covered by the agent’s training distribution.
How to Use AI Coding Agents Safely on Production Backends
The research doesn’t say AI coding tools are useless — it maps exactly where they fail. Agents at L0 and L1 are reliable for scaffolding, boilerplate, and unconstrained generation. However, the moment you’re working with a real database schema, an existing ORM configuration, or framework-specific conventions (especially Django or FastAPI), you’re in territory where agent correctness drops by half or more. That’s precisely where human review earns its cost.
The paper’s recommended mitigations are structural, not prompt-based: retrieval-augmented framework documentation (RAG over your actual framework and ORM docs), constraint-oriented planning (extract and state all constraints explicitly before code generation begins), and targeted pre-training on convention-heavy codebases. Notably absent from the recommendations: better prompting, bigger context windows, or switching models. The constraint decay problem appears to be architectural — a function of how current agents process implicit structural requirements, not a matter of instruction clarity.
Moreover, a parallel paper on constraint drift in multi-agent systems makes the situation slightly more sobering: in multi-agent pipelines, constraints don’t just decay at the generation stage — they degrade as they pass through memory, delegation, and tool use. If you’re running agent pipelines on production backend code, the reliability floor is lower than single-agent numbers suggest.
Key Takeaways
- AI coding agents lose an average of 30 percentage points in correctness when moving from unconstrained (L0) to fully constrained (L3) backend tasks — the level every production app operates at by default.
- Database specification is the single largest constraint penalty (−19.3 pp), and it is unavoidable in production systems.
- FastAPI and Django perform 25 points worse than Flask and Express because their implicit, convention-heavy configuration is invisible to agents generating code without context of those conventions.
- 70% of failures are silent logic errors, not crashes — data-layer bugs that only surface under real query conditions, not in syntax checks or basic test runs.
- Use agents confidently for greenfield scaffolding; validate data-layer and ORM code rigorously before production deployment, regardless of model or tool.