
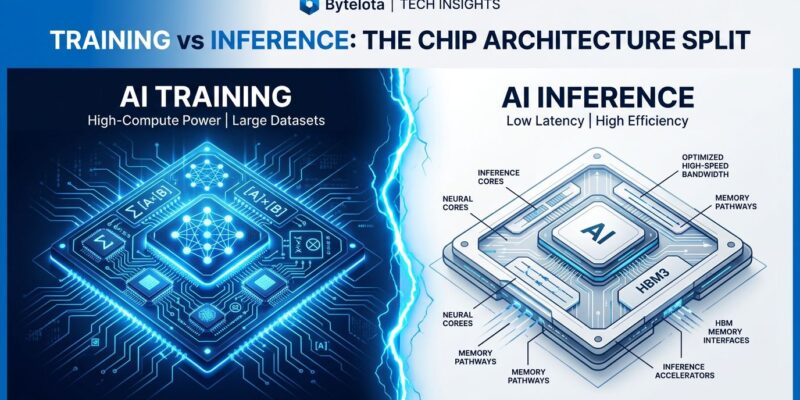
Google just killed the one-size-fits-all AI chip. At Google Cloud Next on April 22, the company announced its eighth-generation TPU split into two specialized accelerators: TPU 8t for training and TPU 8i for inference. After seven generations of unified chips, Google is betting that agentic AI workloads have made it impossible for a single piece of silicon to optimize for both.
The reasoning is simple: training is compute-bound while inference is memory-bound. Agentic systems—where multiple specialized agents collaborate in long reasoning loops—amplify this difference. Heavy KV cache pressure, all-to-all collectives, and cascading latency make inference optimization critical. Google’s solution? Stop trying to do both on the same chip.
Training and Inference Finally Diverge
TPU 8t is built for trillion-parameter training runs. It scales to 9,600 processors with 2 petabytes of shared memory, delivering 121 exaflops of FP4 compute. Performance per pod triples compared to the previous generation, and Google claims the chip compresses frontier model development “from months to weeks.” For teams pre-training large language models, that’s a 2.8x improvement in price-performance.
TPU 8i takes the opposite approach. Instead of raw compute, it prioritizes memory bandwidth and latency. Each chip packs 384 MB of on-chip SRAM—three times more than before—keeping the entire KV cache in silicon. A new Collectives Acceleration Engine offloads global operations, reducing on-chip latency by up to 5x. The result: 80% better performance-per-dollar for inference workloads, especially MoE models.
If you’re using the same hardware for training and inference, you’re wasting money. The workloads have diverged too far.
OpenAI Bets on Google Silicon
Here’s the bigger story: OpenAI is now using Google TPUs. For years, OpenAI was synonymous with Nvidia H100s, training GPT models on Microsoft-procured clusters. Their shift to Google Cloud represents the first visible crack in Nvidia’s dominance.
Nvidia still commands roughly 80% of the AI accelerator market, but that’s down from a peak of 87% in 2024. Silicon Analysts project it will decline further to 75% by the end of 2026. OpenAI isn’t alone—Anthropic’s Claude Opus 4.5 and Google’s Gemini 3 were both trained primarily on custom silicon, not Nvidia GPUs. Meta is reportedly in active negotiations for a multi-billion dollar TPU deal.
The shift is clearest in inference, where Nvidia’s moat is thinnest. Custom chips from Google, Amazon, Meta, and OpenAI are projected to account for 45% of the AI chip market by 2028, up from 37% in 2024. For developers, this means pricing competition and vendor choice. OpenAI secured a 30% discount from Nvidia simply by threatening to switch.
The Numbers: 3x Faster Training, 80% Cheaper Inference
Let’s make this concrete. If you’re training a 70-billion parameter model, TPU 8t cuts the timeline from two or three months to weeks. The 3x performance boost per pod isn’t just a benchmark—it’s the difference between iterating quickly and waiting for experiments to finish.
On the inference side, TPU 8i’s latency reduction matters exponentially in agentic systems. Consider a Claude-scale deployment where each user request triggers 10+ internal agent calls. Every millisecond of latency cascades across the system. TPU 8i’s 5x on-chip latency drop and 3x larger SRAM mean the KV cache stays on-chip, eliminating expensive memory fetches. The result: 80% lower cost and sub-millisecond agent interactions.
Google reports that 75% of all new code at the company is now AI-generated and approved by engineers, up from 50% last fall. Agentic workflows are replacing traditional development, and inference efficiency is the bottleneck.
Specialization Is the New Default
Google’s split mirrors a broader industry trend. AWS already separates Trainium (training) from Inferentia (inference). Custom silicon is proliferating because one-size-fits-all no longer works. Expect more specialization: edge inference chips, retrieval-augmented generation accelerators, fine-tuning processors.
The developer workflow is shifting. Instead of choosing a single GPU vendor, you’ll orchestrate chip types: train on TPU 8t, serve on TPU 8i, deploy edge models on custom silicon. Multi-cloud strategies become viable when tools are optimized for specific workloads.
For teams building agentic systems, this is critical. Inference isn’t just a deployment detail anymore—it’s the performance bottleneck. TPU 8i’s architecture shows where the industry is headed: memory bandwidth over raw compute, latency over throughput, specialization over generalization.
What This Means Going Forward
Google’s TPU 8 split isn’t just a product launch. It’s an architectural bet that the agentic era requires specialized silicon. Training and inference have diverged so far that no single chip can win at both. OpenAI’s adoption validates this thesis—if the makers of GPT trust Google’s silicon, the monopoly is officially over.
For developers, the implications are clear: more choice, better pricing, and infrastructure optimized for how AI actually runs in production. The one-size-fits-all chip is dead. Choose the right tool for the job.













