Google announced general availability of Gemini 3.1 Flash-Lite on May 7, 2026—at $0.25 per million input tokens, it’s now their cheapest production-ready AI model. That’s 75% cheaper than competitors while maintaining quality parity with Gemini 2.5 Flash. The timing isn’t coincidental: this launch comes just 12 days before Google I/O 2026, where bigger Gemini announcements are expected. This is Google’s opening move in a price war for the enterprise AI market.
The Price Breakthrough That Changes Everything
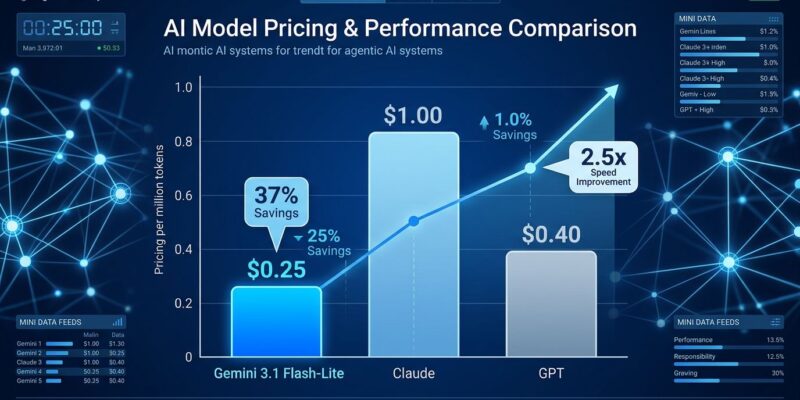
At $0.25 per million input tokens ($1.50 output), Flash-Lite undercuts nearly every comparable model. Claude Haiku 4.5 costs $1/$5. GPT-4.1 Nano sits at $0.10/$0.40, but it’s a lower quality tier. Only lesser-known providers like DeepSeek V4 ($0.14) and Xiaomi MiMo ($0.10) go cheaper.
Moreover, the pricing advantage compounds with optimization features. Prompt caching drops effective costs by 90% for repeated inputs. The batch API adds another 50% discount for asynchronous workloads. For high-volume deployments processing millions of requests daily, these numbers aren’t just competitive—they’re transformative.
Furthermore, this addresses the number one barrier to agentic AI adoption. Gartner predicts over 40% of agentic AI projects will fail by 2027 due to cost and governance issues. Flash-Lite’s predictable low pricing changes that calculus entirely.
Performance Without Compromise
Cheap models usually sacrifice quality. Flash-Lite doesn’t. It delivers 2.5× faster time to first token and 45% faster output generation compared to Gemini 2.5 Flash, while matching its performance across key capability areas. Sub-10 second completions with near-instant streaming make it viable for real-time applications like chatbots and live coding assistants.
Additionally, the technical specs back this up: 97% structured output compliance, 94% intent routing accuracy, and a 1 million token context window at standard pricing. You’re not losing developer features either—context caching, batch processing, thinking mode, and tool calling all ship standard.
Companies aren’t waiting to test this in production. OffDeal, an investment banking platform, uses Flash-Lite to power “Archie,” an AI agent that handles real-time research during Zoom calls with bankers. Their quote: “Only model capable of meeting response times needed for genuinely instant answers without forcing a tradeoff on quality.” Similarly, JetBrains integrated it into their IDE AI assistant, citing the “balance of high intelligence and minimal latency” for real-time developer support.
The I/O Strategy: Seeding Before the Big Play
Releasing a production-ready, aggressively priced model 12 days before your biggest developer event isn’t accidental. Google I/O runs May 19-20, 2026, and Polymarket puts the odds of a Gemini 3.2 or 4.0 release at 41%. Flash-Lite is the appetizer.
The strategy is clear: seed developer adoption with an unbeatable price-to-performance ratio, build ecosystem lock-in, then announce the flagship model at I/O to upsell teams already integrated with the Gemini stack. It’s textbook platform strategy—give away the razor, sell the blades.
Meanwhile, OpenAI and Anthropic are watching. Claude Haiku 4.5 at $1 per million tokens suddenly looks expensive. GPT-4.1 Nano is cheaper on paper but doesn’t match Flash-Lite’s quality tier. Consequently, the pressure is on competitors to either match Google’s pricing or differentiate on features, ecosystem, or support. Price wars rarely end well for anyone, but they’re great for developers.
Agentic AI Economics Just Shifted
The real story here isn’t just cheap tokens—it’s what becomes economically viable. Multi-agent systems that orchestrate dozens of LLM calls per task were prohibitively expensive at $3-5 per million tokens. At $0.25, those same systems drop from “too risky to deploy” to “let’s scale this.”
Agentic AI development already runs $20K-$300K depending on complexity, with 40-60% of enterprises underestimating total cost of ownership. However, the challenge isn’t just initial development—it’s the unpredictable runtime costs. One edge case can trigger retry chains costing 50× the normal execution path. Flash-Lite’s pricing makes those spikes manageable instead of catastrophic.
Therefore, high-volume use cases suddenly make financial sense: translation pipelines processing millions of documents, content moderation at scale, e-commerce catalog generation, and automated customer support handling thousands of concurrent conversations. What was cost-prohibitive last quarter is viable today.
What This Means for You
If you’re building AI-powered products, your deployment economics just changed. High-volume workloads that required careful cost management or tiered model strategies (cheap model first, escalate to expensive only when needed) can now run entirely on a single, fast, cheap tier.
If you’re locked into OpenAI or Anthropic, expect pricing pressure to force their hand. If you’re evaluating providers, Google just made a strong case for Vertex AI adoption.
And if you’re planning for Google I/O? Keep May 19-20 on your calendar. Flash-Lite is the opening act—the main event is still coming.