
A self-hosted 8-billion-parameter model just matched frontier APIs on multi-step agentic workflows — not by being smarter, but by having a better reliability layer around it. Forge, an open-source Python framework by developer Antoine Zambelli, hit the Hacker News front page today with 574 points and 200+ comments after its results were published at CAIS 2026. The finding: add the right guardrails, and a model costing $0.0003 per million tokens in electricity performs as well as a $2/million-token cloud API on the metric that actually matters in production — workflow completion rate.
The Problem Nobody Talks About Enough
Multi-step agentic workflows have a math problem. Even at 95% per-step accuracy, a 5-step workflow only completes 77% of the time. A 10-step workflow drops to 60%. A 20-step workflow: 36%. These are not hypothetical numbers — they are the compounding reality that anyone shipping AI agents to production hits eventually. The standard response has been to throw more expensive models at it. Forge challenges whether that is the right instinct.
The Benchmark That Changes the Framing
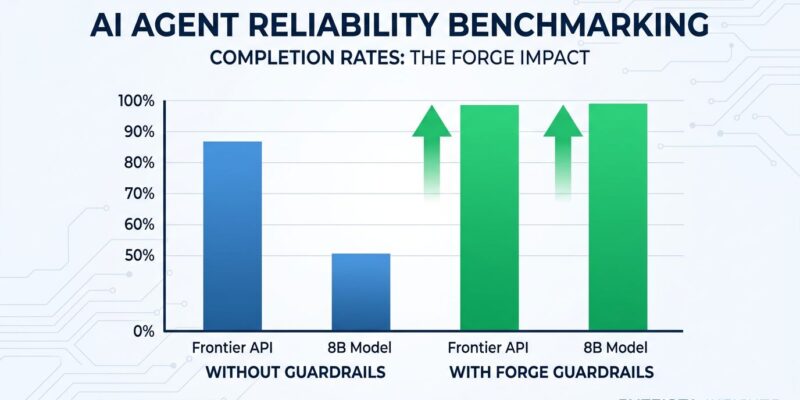
Here is the result that landed Forge on the HN front page. Tested across 50+ model-and-backend configurations using 9 agentic scenarios run 50 times each:
- Frontier API without guardrails: 49–87% completion
- 8B local model without Forge: ~53% completion
- 8B local model with Forge: 99% completion
- Frontier API with Forge: ~99% completion
Frontier models without guardrails lose to small models with guardrails. Not by a little — by up to 50 percentage points. The implication is uncomfortable if you have been paying frontier API prices for “production-grade reliability”: the reliability was not coming from the model. It was coming from luck and short workflows. Forge also found that 8B models outperformed 14B variants from the same model family across multiple configurations. Bigger is not the variable that matters here.
Five Layers of Practical Engineering
Forge does not touch model weights. It wraps the inference loop with five layers that turn a flaky tool-caller into something production-ready:
- Retry nudges — Instead of restarting a failed workflow, Forge sends a corrective prompt to guide the model back on track. This single layer accounts for a 24–49 percentage point improvement.
- Rescue parsing — Malformed tool calls (bad JSON, wrong field types) get automatically corrected instead of throwing exceptions.
- Step enforcement — Required workflow steps run in required order. Models cannot skip steps or call tools out of sequence.
- Error recovery — Forge tracks cumulative failure state and adjusts strategy. Without this, frontier models scored 0% on error recovery scenarios in the benchmark.
- Context compaction — VRAM-aware token budget management with tiered compaction strategies. Hardware limits get detected automatically.
The Python API is straightforward. You define tools as Pydantic models, wire up a WorkflowRunner with a backend client and context manager, and run async workflows. Forge supports Ollama, llama-server, Llamafile, and the Anthropic API as backends. The proxy mode (python -m forge.proxy) drops in as an OpenAI-compatible endpoint — no code changes required in existing systems.
The Backend Detail That Surprised Everyone
The most technically interesting finding was not the headline accuracy number — it was the backend variance. The same Mistral-Nemo 12B model weights produced 7% accuracy on one llama-server configuration and 83% on Llamafile. Same model. Different serving stack. That 76-point swing has real implications: many teams running self-hosted LLMs are getting poor results not because the model is bad, but because the serving configuration is wrong. Forge’s recommended setup — Ministral-3 8B Instruct Q8 on llama-server with the --jinja flag for native function calling — scores 86.5% across its 26-scenario eval suite, 76% on the hardest tier.
When the Math Actually Works Out
The cost argument for self-hosting has existed for a while. An RTX 4090 running Ministral-3 8B costs roughly $0.0003 per million tokens in electricity; GPT-4.1 API costs $2 per million tokens — about 6,000 times more. But self-hosting only pencils out at scale: roughly 11 billion tokens per month before the fixed infrastructure cost makes it cheaper than cloud APIs for most setups. Teams below that threshold still probably stay on cloud APIs. What Forge changes is not the cost math — it is the reliability argument. The last serious objection to self-hosted agents in production was “they are not reliable enough.” That objection just got weaker.
The Caveats Worth Taking Seriously
The HN thread pushed back on a few things, and the pushback is fair. Forge’s guardrails cannot catch semantic errors — a model that produces valid JSON but makes the wrong decision is outside the framework’s scope. Latency under retry conditions was not fully characterized in the benchmark. And the evaluation harness is, by Zambelli’s own acknowledgment, potentially biased toward the guardrail design. These are real limitations, not dealbreakers. For teams already running or evaluating self-hosted agents, the framework is on GitHub, MIT-licensed, and installs with pip install forge-guardrails.


