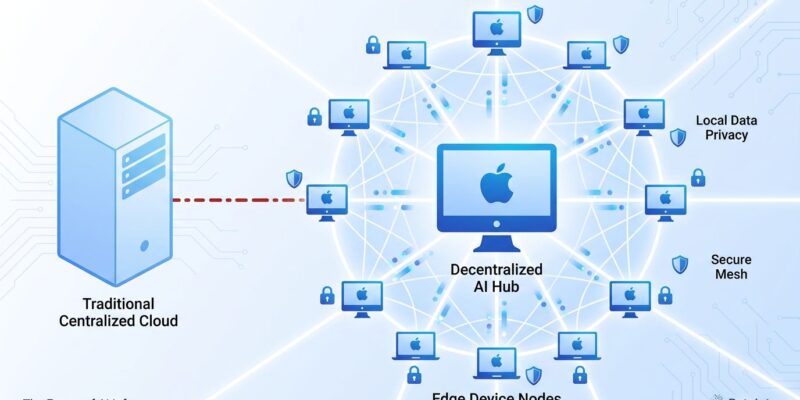
Eigen Labs launched Darkbloom yesterday (April 15, 2026), a decentralized AI inference network routing requests through idle Apple Silicon Macs at 50-70% lower cost than Azure OpenAI and AWS Bedrock. The platform offers hardware-backed privacy via Apple’s Secure Enclave, OpenAI-compatible APIs for drop-in migration, and pays Mac owners 95% of inference revenue—potentially $800-1,100 monthly for a Mac Studio running 18 hours daily. With over 100 million idle Macs sitting unused most of the day, Darkbloom challenges the centralized AI infrastructure model (OpenAI data centers, Anthropic clusters) by monetizing consumer hardware instead of building new data centers.
Timing matters. Enterprise AI costs are exploding—Uber blew through its entire $3.4 billion AI budget in just four months on Claude Code adoption. Developers need cheaper alternatives that don’t sacrifice reliability or privacy. Darkbloom’s answer: leverage idle consumer hardware with cryptographic privacy guarantees stronger than “we promise not to look” policies from cloud vendors.
Related: Uber AI Budget Blown: Claude Code Costs Hit $3.4B in 2026
The Economics: 93% Cheaper Than OpenAI, Zero Platform Fees
Darkbloom’s pricing undercuts centralized providers dramatically. OpenAI charges $5 per million input tokens and $15 per million output tokens for GPT-4o. Azure adds 15-40% overhead on top of that for support plans, network fees, and storage. AWS Bedrock’s Claude Opus costs $15 input and $75 output per million tokens. Darkbloom’s Qwen3.5 27B? $0.13 input, $1.04 output—a 93% reduction compared to GPT-4o.
The platform charges zero fees. Mac operators retain 95% of token revenue (5% covers network costs). A Mac Studio M3 Ultra with 192GB RAM, running 18 hours daily, projects $900-1,200 monthly revenue. Electricity costs roughly $11/month at Apple Silicon’s 30-watt power draw. Consequently, net profit comes to $890-1,190, roughly 90% margin. That’s competitive with GPU cloud providers (Vast.ai, RunPod) but with simpler setup and hardware you already own.
For developers, the math is straightforward: cut inference costs by half or more without rewriting code. Moreover, for Mac owners with Pro, Studio, or Max hardware collecting dust overnight, it’s passive income from compute capacity that would otherwise sit idle.
Privacy Architecture: Hardware Proves What Cloud Vendors Only Promise
Darkbloom’s four-layer security architecture tackles the fundamental trust problem of decentralized inference: node operators have root access and physical hardware custody. How do you prevent them from reading user prompts or model outputs? Eliminate every software path to observe data.
End-to-end encryption happens on the user’s device before transmission. Decryption keys exist only in Apple’s Secure Enclave—tamper-resistant hardware with attestation chains traceable to Apple’s root certificate authority. Furthermore, hardened runtime blocks debugger attachment (PT_DENY_ATTACH kernel flag) and memory inspection APIs. The inference engine runs in-process with no subprocess, no local server, no IPC. Every response is cryptographically signed by the specific machine with published attestation chains verifying security posture.
According to Darkbloom’s GitHub documentation: “The core technical challenge is that the machine owner has root access and physical custody—they should not be able to see user prompts or model responses.” Hardware attestation isn’t marketing—it’s cryptographic proof the operator can’t observe your data. That’s stronger than centralized providers’ “trust us” policies. Therefore, for compliance-sensitive applications (healthcare, legal, finance), hardware-backed guarantees matter.
OpenAI API Compatibility: Change One Line, Cut Costs 70%
Migration friction kills adoption. Darkbloom solves this with OpenAI-compatible APIs—developers change the base URL and nothing else. Same client libraries, same request format, same streaming support. Additionally, the platform handles inference requests up to 239B parameter models, image generation via FLUX.2 on Metal, and speech-to-text through Cohere Transcribe.
Here’s the entire migration:
# Before (OpenAI)
import openai
client = openai.OpenAI(api_key="sk-...")
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello"}]
)
# After (Darkbloom) - only base URL changes
import openai
client = openai.OpenAI(
base_url="https://api.darkbloom.dev/v1",
api_key="dbk-..."
)
response = client.chat.completions.create(
model="qwen3.5-27b",
messages=[{"role": "user", "content": "Hello"}]
)Test Darkbloom on non-critical workloads, compare performance and reliability, roll back instantly by changing the base URL back. In contrast to Ollama or llama.cpp, which require different APIs and local setup complexity, Darkbloom offers no vendor lock-in, no code rewrite, no migration project.
Apple Silicon Performance: Consumer Hardware Beats Data Center GPUs
Apple Silicon isn’t just “good enough”—it’s competitive with data center GPUs. An M3 Ultra achieves 2,320 tokens per second on Qwen3-30B 4bit, beating an RTX 3090 at 2,157 tokens/second. Mac Mini M4 Pro delivers 20-30 tok/s on 8B-13B models, fast enough for comfortable interactive use. Meanwhile, a $3,000 Mac runs 60B parameter models at 30 watts versus hundreds of watts for rack-mounted GPUs.
Recent optimizations accelerate performance further. Ollama 0.19 (March 2026) introduced MLX backend support for 2x faster inference on Apple Silicon. Additionally, the M5 Max delivers 614 GB/s unified memory bandwidth, up from the M4 Max’s 546 GB/s. Over 100 million idle Macs represent massive untapped compute capacity—Darkbloom’s technical bet is that consumer hardware at scale competes with purpose-built data centers.
Reality Check: Research Preview, Not Production Ready
Despite professional presentation, Darkbloom is a research preview. The network has 21 machines as of April 16, 2026—the day after launch. No production SLA, no uptime guarantees, unaudited security architecture. Eigen Labs explicitly warns: “Darkbloom is under active development and has not been audited and should be used only for testing purposes and not in production.”
Operator revenue projections ($800-1,100/month) are theoretical until real demand materializes. With 21 nodes and unknown request volume, actual earnings remain speculative. Moreover, the coordinator is centralized despite “decentralized” framing—a single point of failure and control. Network effects favor incumbents: OpenAI and Anthropic have massive leads in brand trust, model quality, enterprise sales, and global infrastructure.
Appropriate expectations matter. Test Darkbloom on low-volume, non-critical inference before migrating production traffic. Mac owners should view operator income as experimental passive revenue, not replacement income. The project’s value lies in challenging centralized AI economics and exploring whether consumer hardware can supplement (or eventually compete with) data center buildouts.
Key Takeaways
- Darkbloom offers 50-70% cost savings versus centralized AI providers (Azure, AWS, OpenAI) through decentralized inference on idle Apple Silicon Macs
- Hardware-backed privacy via Apple Secure Enclave provides cryptographic proof operators can’t observe user data—stronger than cloud vendors’ trust-based policies
- OpenAI API compatibility enables testing with minimal code changes (just swap base URL), reducing migration friction and vendor lock-in
- Research preview status means not production-ready: 21 machines, no SLA, unaudited security, theoretical operator revenue
- Mac owners with Pro/Studio/Max hardware can potentially earn $800-1,100/month from idle compute capacity (18 hours daily at ~90% profit margin)