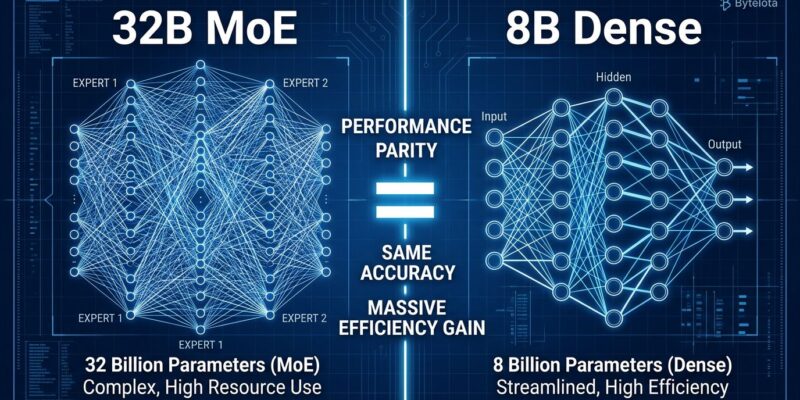
IBM released Granite 4.1 yesterday (April 29, 2026), and the standout achievement isn’t the model size—it’s the efficiency. The 8B parameter dense model matches or exceeds IBM’s previous 32B Mixture-of-Experts model across key benchmarks, including beating it on tool calling (68.3 vs 64.7 on BFCL V3). This challenges the “bigger models are better” assumption dominating AI development, with major implications for enterprise deployment costs.
Training Quality Beats Architectural Tricks
Granite 4.1 8B’s performance comes from training methodology, not parameter count inflation. IBM used a 5-phase training strategy across 15 trillion tokens, progressively shifting from broad web-scale data to curated technical, scientific, and mathematical content. The final phase extended context windows to 512K tokens without degrading short-context performance.
Post-training involved 4.1 million curated samples and multi-stage reinforcement learning, with each phase targeting distinct capabilities: instruction adherence, conversation quality, factual accuracy, and mathematical reasoning. Moreover, this staged approach delivered what larger, more complex architectures couldn’t: competitive performance in a simpler, denser package.
The Dense vs MoE Trade-off Everyone Ignores
Here’s the part most enterprise teams miss: Mixture-of-Experts models promise efficiency by activating only a subset of parameters—say, 9B active out of 32B total. However, they still require ALL parameters loaded into memory simultaneously. The gating network needs access to every expert to route inputs correctly.
Dense models eliminate this paradox. Granite 4.1 8B offers predictable latency, stable token usage, and no extended reasoning chains. For enterprises choosing between architectures, dense models deliver simpler deployment, easier fine-tuning, and better fit for edge environments—all without sacrificing performance against MoE alternatives.
Performance Where It Counts
Granite 4.1 8B matches or beats IBM’s 32B MoE across 10+ benchmarks. On BFCL V3 (tool calling), the 8B scores 68.3 versus the 32B’s 64.7—a clean win for the smaller model. Furthermore, it hits 92.5 on GSM8K (grade-school math) and 69.0 on ArenaHard, consistently matching the larger architecture.
Context matters here: this is IBM’s 8B beating IBM’s 32B, not competing with GPT-5.5 or Claude Opus 4.7. Consequently, Granite 4.1 isn’t a frontier model. It’s an efficiency achievement that proves dense architectures paired with better training can rival MoE complexity within a model family.
Developer Reality Check
Hacker News developers weren’t buying the hype wholesale (166 points, 94 comments). The top comment cut straight: “Compared to other model families, Granite 4.1 8B sucks. The only benchmark it does well at compared to other models is non-hallucination and instruction following.”
The consensus: Qwen 3.5/3.6 remains the preferred choice for coding tasks, “pushing way above its weight” and “scoring above sonnet in coding benchmarks” while staying locally runnable. Nevertheless, Granite 4.1’s strengths lie elsewhere—instruction-following, edge deployment, non-hallucination, and table/semantic extraction through its Vision model.
One developer summed up the benchmark debate well: “The only valid opinion on whether it works for you is not benchmark, it’s an informed opinion from ‘using it in anger.'” Granite 4.1 8B succeeds where it aims to: enterprise deployment with governance, not frontier-level reasoning.
What This Means for Enterprise AI
IBM released all Granite 4.1 models under Apache 2.0 licensing, including 3B, 8B, and 30B variants covering language, vision, speech, embeddings, and Guardian safety models. This isn’t just open source—it’s enterprise-grade AI with ISO certification, cryptographic signatures, and full transparency disclosures.
The 8B model works with vLLM and Transformers out of box and is available via IBM’s API for evaluation before local deployment. In addition, for enterprises balancing performance, costs, and governance, Granite 4.1 offers a viable path: competitive instruction-following and tool-calling without long reasoning chains, predictable latency, and stable operational costs.
The Bigger Pattern
Granite 4.1 8B signals a shift from “bigger is better” to “smarter is better.” Training methodology—staged data quality progression, multi-phase RL targeting specific capabilities—now matters more than architecture complexity or raw parameter count. Subsequently, dense models are competitive again, and enterprises get efficiency without sacrificing performance.
This isn’t about Granite beating GPT-5.5. It’s about proving that careful training can rival architectural tricks, that 8B can match 32B, and that the path to enterprise AI doesn’t require proprietary licensing or complex MoE systems. Sometimes the smarter approach wins over the bigger one.