
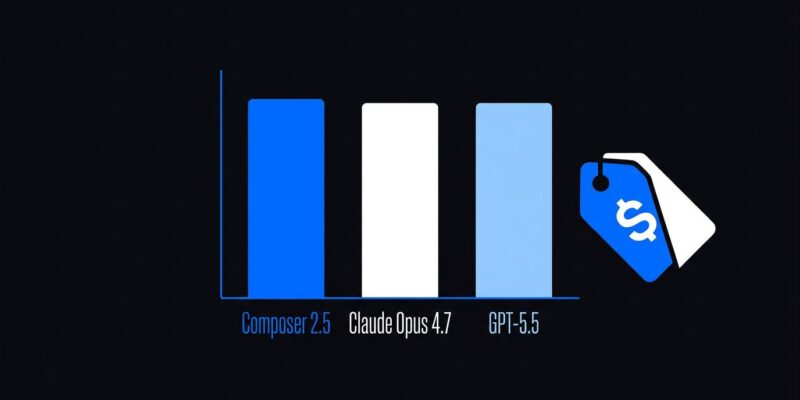
Cursor shipped Composer 2.5 on May 18. It scores 79.8% on SWE-Bench Multilingual — within one point of Claude Opus 4.7 (80.5%) and ahead of GPT-5.5 (79.1%). The Standard tier costs $0.50 per million input tokens. Claude Opus 4.7 costs roughly 30x more. That gap makes Composer 2.5 worth understanding in detail, but there’s one benchmark number most coverage skips over, and it matters if your workflow lives in the terminal.
What Cursor Did With Kimi K2.5
Composer 2.5 starts from the same place as Composer 2: Moonshot AI’s open-source Kimi K2.5 checkpoint. The difference is what Cursor did on top of it. Composer 2.5 was trained with 25 times more synthetic tasks than its predecessor, using a method Cursor calls targeted textual feedback — instead of outcome-only signals, the training provides feedback at the specific point in an agent trajectory where behavior could have improved. The pretraining also incorporates Sharded Muon with distributed orthogonalization and dual mesh HSDP, which Cursor says improves stability at scale.
The results are significant. SWE-Bench Multilingual moved from 73.7% to 79.8% — a six-point jump. CursorBench v3.1, which focuses on multi-file agent tasks inside Cursor, moved from 52.2% to 63.2%, an 11-point gain. Behaviorally, Cursor says Composer 2.5 handles longer tasks more reliably and calibrates effort better — harder to benchmark, but relevant when agents run for extended sessions.
The Benchmark Table You Actually Need
Most coverage leads with SWE-Bench Multilingual, where Composer 2.5 essentially matches Opus 4.7 and leads GPT-5.5. That’s accurate, but Terminal-Bench 2.0 tells a different story. On terminal-native tasks — shell scripting, infrastructure automation, system administration — GPT-5.5 scores 82.7%. Composer 2.5 scores 69.3%. That 13-point gap is documented, consistent across evaluations, and meaningful if your agent work involves anything close to a shell prompt.
The other caveat: CursorBench v3.1 is Cursor’s proprietary benchmark, designed around multi-file agentic coding in Cursor’s own environment — exactly where Composer 2.5 has been optimized. SWE-Bench Multilingual is the more independent signal. Both point to near-parity with Opus 4.7 on pure coding tasks, but don’t mistake near-parity on coding benchmarks for near-parity everywhere.
Pricing: Where the Math Gets Interesting
Composer 2.5 has two tiers. Standard is $0.50 per million input tokens and $2.50 per million output tokens. Fast — the default for interactive use — is $3.00 input and $15.00 output. Claude Opus 4.7 runs approximately $15 per million input and $75 per million output.
Standard is therefore about 1/30th of Opus 4.7 per token. Fast is roughly 1/5th. If you’re running Cursor 3’s Agents Window with multiple parallel sessions, Standard tier at scale changes the cost math dramatically. An agent workload that costs $300 per month on Opus 4.7 runs around $10 on Composer 2.5 Standard. For a full pricing breakdown by use case, Lushbinary’s developer guide covers the numbers in detail.
The practical split: use Fast for interactive coding where latency matters. Use Standard for background agent tasks — large refactors, documentation generation, test writing — where you can wait a few extra seconds and the savings compound across sessions.
When to Still Use Opus 4.7 or GPT-5.5
Composer 2.5 is not a universal replacement. There are three cases where you should switch.
Reach for Claude Opus 4.7 when the task demands deep architectural reasoning across very long contexts — Opus supports up to 1 million tokens and still leads on single-shot reliability for complex, high-stakes generation. If you’re doing one-shot architectural planning and you need the strongest available model, Opus remains the answer.
Reach for GPT-5.5 when your work is terminal-heavy. The 13-point Terminal-Bench gap is consistent across independent evaluations. Shell scripting, Kubernetes automation, infrastructure-as-code, and Codex CLI tasks are where GPT-5.5 maintains a documented edge that Composer 2.5 doesn’t close.
Reach for Composer 2.5 for everything else inside Cursor: everyday file edits, multi-file refactors, debugging sessions, and especially parallel agent workflows where Standard tier’s cost advantage at scale is substantial. DataCamp’s comparison guide and The New Stack’s analysis both support this breakdown.
One Distinction Worth Making
If you’ve been following the Kimi K2.6 news — Moonshot’s latest open-source release — Composer 2.5 is a different product. It uses the Kimi K2.5 checkpoint (released January 2026) as a foundation, but has been fine-tuned extensively by Cursor on proprietary training data. You can’t replicate Composer 2.5’s benchmark performance by running raw Kimi K2.5. The 11-point CursorBench gain over Composer 2 is Cursor’s training contribution, not Kimi K2.5’s out-of-the-box capability. For context on where Kimi K2.6 fits as a standalone open-source model, see our coverage of the Moonshot release.
Composer 2.5 is the default model in Cursor 3’s Agents Window as of the May 18 launch. If you’ve been running Composer 2 and haven’t changed settings, you’re already on 2.5 in interactive sessions. The upgrade is automatic — but the choice of Standard versus Fast, and when to switch models entirely, is yours to make.

