
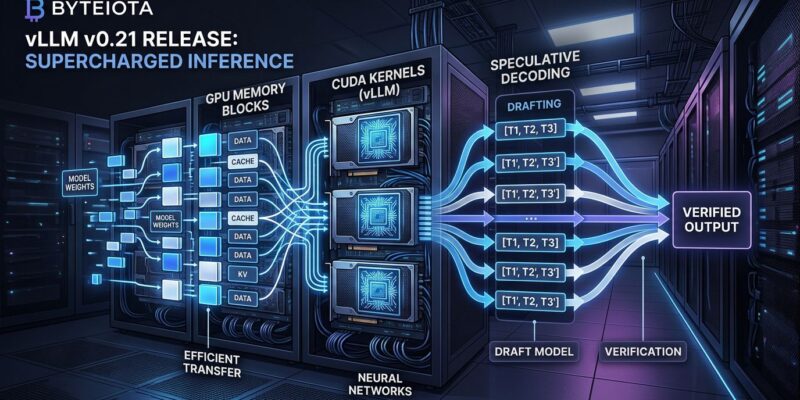
vLLM v0.21.0 dropped on May 15, and for teams running reasoning models in production, two of its three headlining features are genuinely worth stopping for. The third is Blackwell-specific. And there’s a known regression that will ruin your week if you upgrade Qwen deployments without checking first.
Speculative Decoding Finally Respects Thinking Budgets
This is the change that matters most for anyone serving DeepSeek-R1, Kimi-K25, or similar reasoning models. Speculative decoding — using a small draft model to predict tokens in parallel, then verifying with the main model — typically delivers 1.5 to 2x throughput improvements. The problem was that reasoning models operate under a ‘thinking budget’: a hard token ceiling on their internal chain-of-thought. Earlier vLLM versions ignored that ceiling during spec decode, meaning the draft model could blow past the budget and force expensive corrections or produce wrong outputs. You had to choose between speculative decoding and correct budget enforcement.
v0.21.0 fixes this. Spec decode now enforces thinking budget constraints end-to-end. If you’ve been holding off on enabling speculative decoding for your reasoning model deployments because of this behavior, it’s time to try again.
vllm serve deepseek-ai/DeepSeek-R1 \
--speculative-model deepseek-ai/DeepSeek-R1-Draft \
--num-speculative-tokens 5 \
--enable-reasoning \
--reasoning-parser deepseek_r1EAGLE speculative decoding support also extends to Mistral and Gemma4 MTP in this release, broadening the set of models that benefit. See the reasoning outputs documentation for the full list of supported parsers.
KV Offload Integrates with the Hybrid Memory Allocator
GPU VRAM is the ceiling that most production LLM deployments bump against first. KV cache offloading — moving key-value pairs to CPU DRAM when GPU memory is tight — has been in vLLM for a while, but it didn’t coordinate well with the Hybrid Memory Allocator (HMA) introduced for models with non-standard attention layers (Mamba, sliding window, cross-attention). In 0.21.0, the two systems are fully integrated.
HMA groups model layers by attention type into KV Cache Groups, allowing layers in the same group to share block IDs without wasting memory. The offloading subsystem now operates through this grouping structure, which means hybrid architecture models — Mamba-Transformer hybrids, for example — can offload KV cache efficiently. Teams serving long contexts (128K tokens and above), multi-turn conversations with persistent history, or multiple models on shared GPU pools should see more stable memory utilization. The HMA architecture documentation covers the grouping design in detail.
TOKENSPEED_MLA on Blackwell
DeepSeek-R1 and Kimi-K25 use Multi-head Latent Attention (MLA), a compressed KV cache architecture that requires a dedicated attention kernel. vLLM 0.21.0 adds a TOKENSPEED_MLA backend purpose-built for MLA prefill and decode on NVIDIA Blackwell (GB200, B200). If your deployment is already on Blackwell hardware running these models, the backend is auto-detected — no configuration change required. It’s a direct performance optimization that addresses part of the gap that has made SGLang the preferred framework for DeepSeek workloads.
Stop: Check This Before You Upgrade
vLLM 0.21 breaks Qwen’s Multi-Token Prediction. Users running Qwen 3.6 27B are reporting the MTP prediction rate drops to 0% on every request. If you use Qwen models with MTP enabled, do not upgrade to 0.21.0. Pin to 0.20.x until 0.21.1 is confirmed.
Three Breaking Changes to Handle First
vLLM now requires a C++20-compatible compiler — a PyTorch 2.10.0 dependency requirement. Ubuntu 20.04 with its default GCC 9.4.0 will fail to build. Ubuntu 22.04 with GCC 12+ works. Fix it with:
sudo apt-get install gcc-12 g++-12
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-12 100Two more breaking changes: Python 3.12 is now the minimum supported version, and Transformers v4 APIs are deprecated. If your deployment integrates custom models against Transformers v4 internals, update those before pulling 0.21.0.
Upgrade
Once compiler, Python, and Transformers requirements are satisfied:
pip install vllm==0.21.0Docker users get a bonus: the official 0.21.0 image is approximately 2.5 GB smaller than 0.20.x. FlashInfer cubin downloads are now deferred rather than baked in at image build time.
docker pull vllm/vllm-openai:v0.21.0What’s Coming
The Q2 2026 roadmap targets prefill-decode disaggregation via the NixlConnector — high-performance KV cache transfer between separate prefill and decode instances using the NIXL library. This is the infrastructure for running specialized processes for each inference phase, a pattern cloud providers have validated at scale. Expect it to stabilize in the 0.22 to 0.23 range.


