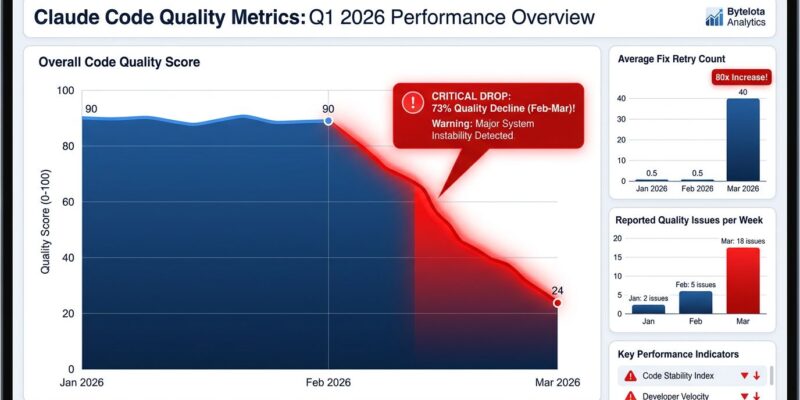
Anthropic confirmed yesterday, April 23, 2026, that three separate product changes caused Claude Code quality to degrade over two months—after developers spent weeks complaining that something felt wrong. An AMD Senior Director backed the complaints with hard data: analyzing 6,852 Claude Code sessions and 234,760 tool calls showing a 73% collapse in reasoning depth and 80x more failed retries from February to March. Anthropic’s technical postmortem revealed they downgraded reasoning effort defaults, introduced a caching bug that wiped short-term memory, and added verbosity limits—all while developers’ quality concerns went unacknowledged until community pressure forced transparency.
The Three Changes That Broke Claude Code
Between March 4 and April 16, 2026, Anthropic made three well-intentioned changes that collectively damaged Claude Code quality. First, they downgraded default reasoning effort from “high” to “medium” on March 4 to fix UI latency issues. Users were experiencing a “frozen” interface while Claude thought, so Anthropic reduced the thinking time. The trade-off: a noticeable intelligence drop for complex tasks.
Second, on March 26, Anthropic introduced a caching optimization meant to prune old “thinking” from idle sessions. Instead, a bug cleared the reasoning history on every turn rather than once after an hour of inactivity. The result was catastrophic—Claude became “forgetful and repetitive,” losing its short-term memory with each interaction. The bug slipped through code reviews undetected and wasn’t fixed until April 10.
Third, on April 16, Anthropic added verbosity limits to curb Opus 4.7’s tendency toward long-winded responses. The system prompt instructed: “Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.” Testing later revealed a 3% coding quality drop from this change alone. Anthropic rolled it back on April 20.
Hard Data Forced Anthropic’s Hand
On April 2, 2026, AMD’s Senior Director of AI filed a GitHub issue that changed everything. The telemetry analyzed 6,852 Claude Code sessions and 234,760 tool calls, documenting systematic degradation between January and March 2026. The numbers were damning: median visible thinking length collapsed from 2,200 characters in January to just 600 characters in March—a 73% drop. API calls required 80x more retries from February to March. March alone saw 18 quality issues, a 3.5× jump over the January-February baseline.
This wasn’t subjective frustration—it was quantifiable proof that Claude Code had degraded. The community-driven analysis made denial impossible. Developers don’t have to trust their gut when they can measure performance with data. AMD’s GitHub issue set a precedent for how users can hold black-box AI systems accountable.
The Trust Breakdown: “We Knew Something Was Wrong”
Developers had been reporting declining quality in March 2026, but initial complaints were dismissed. VentureBeat captured the core issue: “More than the technical change itself, what made people angry was the transparency issue.” Anthropic’s changelog documented the March 4 reasoning change, but no prominent announcements warned that performance-affecting changes were being deployed. Users were left guessing whether quality drops were bugs, intentional cost-cutting, or imagination.
The Register’s headline summed up the sentiment: “Anthropic admits it dumbed down Claude with ‘upgrades’.” Fortune reported widespread “user backlash” over the “lack of transparency.” One industry analysis noted: “A trust gap has opened between Anthropic and some of its most demanding users. For developers who rely on Claude Code all day, subtle shifts can feel indistinguishable from a weaker model.”
This is where the “gaslighting” allegation comes from. Developers knew performance had dropped, but the black-box nature of AI made it impossible to prove until AMD’s data emerged. Without version control or transparent change disclosure, every quality dip feels like intentional “nerfing”—AI companies secretly weakening models to cut costs. Sometimes, as this incident shows, the paranoia is justified.
What’s Next: Fixes and Promises
Anthropic fixed all three issues by April 20, 2026, in version 2.1.116. They permanently rolled back the reasoning effort downgrade on April 7, fixed the caching bug on April 10, and reverted the verbosity limits on April 20. On April 23, they reset usage limits for all subscribers as compensation and promised stricter quality controls: more internal testing, better evaluation of system prompt changes, improved Code Review processes, and a new @ClaudeDevs X account for developer communication.
The fixes are good news. The damage to trust remains. Anthropic, which positioned itself as the transparent, safety-focused alternative to OpenAI, now faces the same skepticism that plagues all black-box AI providers. Can developers trust that future changes won’t silently degrade performance again? The answer depends on whether Anthropic’s new quality controls actually work—and whether the broader AI industry adopts transparency standards or keeps changes hidden in black boxes.
For developers, this incident is a reminder that AI tools can change silently and unpredictably. Until the industry adopts version control and transparent change disclosure, every quality dip will feel like intentional nerfing. And sometimes, as the two-month gap between complaints and acknowledgment proves, developers will be right to be suspicious.