The vector database market is collapsing into PostgreSQL. Three major transactions in 2025 total $1.35 billion invested in PostgreSQL companies: Snowflake acquired Crunchy Data for $250 million in June, Databricks bought Neon for $1 billion in May, and Supabase raised $100 million at a $5 billion valuation in October. Performance benchmarks show PostgreSQL with pgvectorscale achieving 471 queries per second compared to Qdrant’s 41 QPS—11x faster—while costing 75% less than Pinecone. The industry consensus has shifted: vectors moved from being a database category to a data type.
The $1.35 Billion PostgreSQL Bet
When cloud giants invest $1.35 billion in PostgreSQL companies within six months, pay attention. Snowflake spent $250 million to acquire Crunchy Data in June 2025, gaining enterprise PostgreSQL expertise to launch Snowflake Postgres for AI workloads. Databricks followed with a $1 billion acquisition of Neon in May 2025, betting on serverless Postgres as the database for AI agents. According to Databricks, 80% of databases created on Neon were provisioned automatically by AI agents rather than humans.
Supabase, the PostgreSQL-based backend platform, raised $100 million at a $5 billion valuation in October 2025. The company now serves 4 million developers and 100,000 customers, including over half of the latest Y Combinator batch. These aren’t speculative bets on emerging technology. Cloud platforms are betting their AI strategies on PostgreSQL because it works.
The Benchmarks: 11x Faster, 75% Cheaper
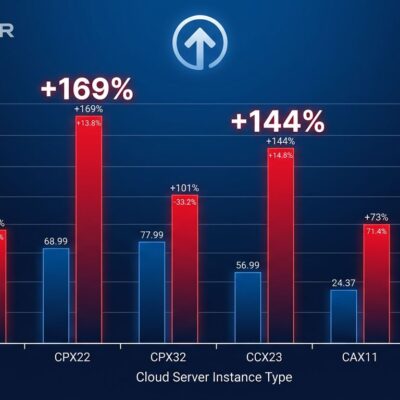
Conventional wisdom says specialized databases are always faster and worth the premium. The benchmarks prove otherwise. PostgreSQL with the pgvectorscale extension achieves 471 queries per second at 99% recall on 50 million vectors, compared to Qdrant’s 41 QPS—an 11x performance advantage. Independent tests also show pgvectorscale delivers 28x lower p95 latency than Pinecone’s s1 tier.
The cost comparison is even more striking. Self-hosting PostgreSQL on AWS EC2 for 50 million vectors costs approximately $835 per month. Pinecone charges $3,241 per month for the s1 tier or $3,889 per month for the p2 tier—a 75-79% markup for comparable or inferior performance. For moderate-scale workloads under 100 million vectors, PostgreSQL isn’t just “good enough”—it’s faster and costs four times less.
From Four Databases to One
Every additional database is expensive. Not just in licensing fees, but in operational complexity. The old architecture: PostgreSQL for relational data, Pinecone for vectors, Elasticsearch for search, TimescaleDB for time-series. That’s four separate systems to backup, monitor, patch, and troubleshoot. Four different query languages. Four on-call rotations at 3 AM.
Teams are consolidating to PostgreSQL with extensions. The new architecture: PostgreSQL with pgvectorscale for vectors, pg_trgm for search, and TimescaleDB as an extension for time-series data. One database. One backup strategy. One query language. Industry reports show 40-60% operational cost savings from consolidation, not counting the 75% reduction in vector database licensing fees.
PostgreSQL’s killer feature isn’t just cost or performance—it’s SQL joins. Dedicated vector databases can’t combine vector similarity with relational filters in a single query. Need to find similar documents a user has permission to access, filtered by date? PostgreSQL does it in one query. Pinecone requires multiple round trips and client-side filtering.
Vectors Aren’t a Category Anymore
VentureBeat’s 2026 data predictions stated it clearly: “Pre-2025, purpose-built vector databases were presented as the standard infrastructure, but by 2026, vectors have moved from being a database category to a data type.” Oracle, MongoDB, MySQL, and Snowflake all added native vector support in 2024-2025. Specialized vector databases aren’t competing with each other anymore—they’re competing with extensions to existing platforms.
This pattern repeats. PostgreSQL absorbed document databases through JSONB (competing with MongoDB), time-series through TimescaleDB (competing with InfluxDB), and geospatial through PostGIS. Now pgvectorscale is absorbing the vector database category. The timeline is consistent: specialized database categories have a 2-3 year window before PostgreSQL extensions mature to “good enough” performance at lower cost. Graph databases are next—Apache AGE already brings graph capabilities to PostgreSQL.
The consolidation isn’t just technical—it’s economic. Specialized databases face “extension death” when general-purpose platforms mature. For database startups, this means reaching massive scale (over 100 million vectors) or getting acquired before the extension ecosystem catches up. For developers, it means PostgreSQL with extensions is the safer long-term bet.
When PostgreSQL Isn’t Enough
PostgreSQL with pgvectorscale is recommended for under 50-100 million vectors. Beyond that threshold, dedicated vector databases like Pinecone, Qdrant, and Weaviate regain their performance advantage through horizontal scaling and distributed architectures optimized for billions of vectors.
However, most companies never reach this scale. A typical RAG application with 10-50 million documents falls well within PostgreSQL’s optimal range. The question isn’t “Can PostgreSQL scale to billions of vectors?” but “Do you actually need billions of vectors?” Don’t pay four times more for Pinecone’s billion-vector scalability when your production workload will never exceed 50 million.
Start with PostgreSQL. Migrate to a dedicated vector database only when you hit scale limits. Most companies won’t.
Key Takeaways
- PostgreSQL absorbed vector databases through pgvectorscale, delivering 11x faster performance than Qdrant and 75% cost savings versus Pinecone for workloads under 100 million vectors
- $1.35 billion invested by Snowflake, Databricks, and Supabase in PostgreSQL companies signals market consolidation around PostgreSQL as the foundational database for AI applications
- Operational savings of 40-60% come from consolidating four separate databases (PostgreSQL, Pinecone, Elasticsearch, TimescaleDB) into one PostgreSQL instance with extensions
- Industry consensus shifted from “vectors are a database category” to “vectors are a data type”—major vendors (Oracle, MongoDB, Snowflake) all added native vector support in 2024-2025
- Specialized database categories face “extension death” within 2-3 years when PostgreSQL extensions mature to competitive performance—document (JSONB), time-series (TimescaleDB), geospatial (PostGIS), and now vector (pgvectorscale) all followed this pattern