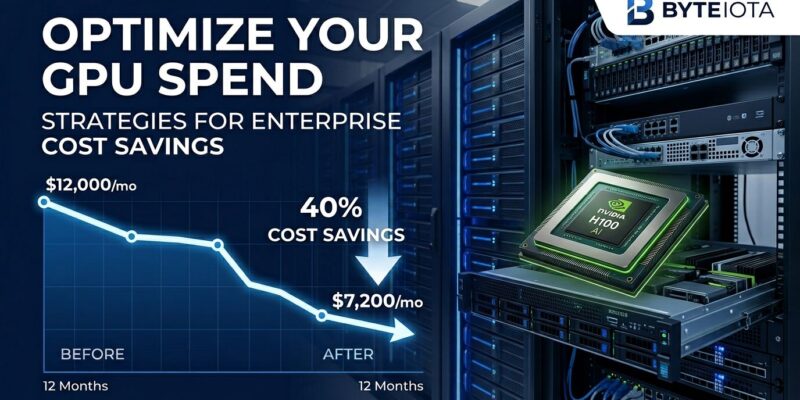
Enterprise AI costs are spiraling out of control in 2026. Foundation model training runs into millions of dollars per run, GPU clusters consume megawatts of power, and organizations waste 30-50% of their cloud spending on over-provisioned resources. However, TSMC price hikes pushed GPU costs 50% higher this year, and data centers now burn through 4% of US electricity. Yet enterprises adopting specific optimization strategies cut GPU bills by 70-90% without sacrificing AI capabilities. Here’s how they do it.
Spot Instances: 70-90% Savings
GPU spot instances deliver the single biggest cost reduction available today. By accepting potential interruptions, you pay 70-90% less than on-demand pricing. Moreover, Pinterest proved the model works at scale: their 200-GPU training infrastructure runs 80% on spot instances, checkpointing every 15 minutes to S3, saving $4.8 million annually—a 72% cost reduction for production AI workloads.
The economics are stark. An H100 on-demand costs $2.99-$9.80/hour depending on provider. Meanwhile, spot instances run $1.50-$2.10/hour for the same hardware. AWS SageMaker reports customers hitting 90% savings with managed spot training.
The catch: spot capacity gets reclaimed when demand spikes, with just 2 minutes warning. Therefore, the solution is checkpoint discipline. Save model state every 15-30 minutes to persistent storage like S3 or GCS. When AWS reclaims your instance, the job resumes from the last checkpoint automatically. Furthermore, PyTorch Lightning includes built-in spot support with configurable checkpoint frequencies.
Use spot instances aggressively for training workloads where checkpoint/resume is viable. However, avoid them for production inference serving with latency requirements—interruptions are unacceptable when users wait for responses.
GPU Pooling: 82% Reduction
Alibaba Cloud’s Aegaeon system reduced GPU requirements by 82% during a 3-month beta test, serving dozens of large language models with just 213 GPUs instead of the 1,192 traditional deployment required. Moreover, the results, published in a peer-reviewed ACM SOSP 2025 paper, beat competing solutions by 1.5× to 9× in throughput benchmarks.
The innovation is token-level autoscaling. Traditional systems reserve GPU capacity per request—if your inference generates 500 tokens, the GPU sits allocated for the entire generation. In contrast, Aegaeon virtualizes GPU access at the token granularity, scheduling tiny slices of work across a shared pool. Multiple models pack onto single GPUs, and compute allocates dynamically as output generates rather than locking resources upfront.
This matters for inference workloads. Training typically saturates GPUs with batch processing, but inference runs bursty and unpredictable. Consequently, pooling extracts far more capacity from existing silicon—critical when GPU supply is constrained or costs are climbing.
Cloud providers will adopt these techniques. The 82% reduction isn’t Alibaba-specific magic; it’s smarter scheduling applicable to any multi-tenant serving environment.
TPU Alternatives: 4× Price/Performance
For large-scale LLM training, recommendation systems, and high-batch inference, Google TPUs deliver up to 4× better price/performance than NVIDIA GPUs. Furthermore, a 1,000-chip TPU cluster saves $98.5 million over 3 years compared to equivalent GPU infrastructure, assuming 80% utilization.
Google trained Gemini on TPUs. Similarly, Anthropic signed major deals for TPU capacity. The hardware works—but only for specific workloads.
TPUs optimize TensorFlow and JAX. If your stack runs PyTorch natively, or you need framework flexibility, GPUs remain the better choice. However, TPU v5e pricing starts at $0.32/core/hour with committed use discounts reaching 57% for 3-year terms. Compare that to H100 spot instances at $1.50-$2.10/hour, and the economics favor TPUs for workloads that fit.
The decision is strategic, not tactical. Migrating to TPUs requires infrastructure changes and framework evaluation. Nevertheless, for organizations running massive training jobs on TensorFlow, the 4× price advantage compounds quickly.
FinOps Practices: 20-35% Baseline
Before chasing advanced optimizations, get the basics right. Mature FinOps programs consistently deliver 20-35% cost reductions within the first year through visibility, right-sizing, and cost attribution. Importantly, these savings are foundational—spot instances and pooling multiply on top of a well-managed baseline.
GPU instances cost 5-10× standard compute, making them high-impact optimization targets. Organizations that actually track AI/ML costs jumped from 31% in 2024 to 63% in 2026. Visibility precedes optimization.
The core FinOps cycle is simple: establish real-time visibility into resource usage, identify safe optimizations, forecast spend based on data, and bake cost awareness into development workflows.
For GPU workloads, specific techniques include right-sizing GPU selection instead of defaulting to A100s or H100s, implementing approval workflows for expensive training runs, applying model quantization for 2× speedup and 50% cost reduction on inference, and caching common queries to eliminate 20-60% of redundant compute.
Monitoring tools matter. NVIDIA DCGM is the industry standard for GPU telemetry, exporting Prometheus metrics for utilization, memory, power, and temperature. Similarly, Kubecost tracks Kubernetes GPU costs in real-time. Platforms like Vantage and Flexera add AI workload attribution and cost-per-outcome tracking—not just infrastructure spend percentages, but cost per inference, per customer, per model.
Modern FinOps measures outcomes, not inputs.
Decision Framework for GPU Cost Optimization
The right optimization depends on workload type. For training, default to spot instances—70-90% savings with minimal complexity. For large-scale training at massive batch sizes, evaluate TPUs for 4× price/performance if your stack uses TensorFlow or JAX. Reserve on-demand capacity for mission-critical training with hard deadlines.
For inference, high-volume serving benefits from GPU pooling when available, potentially cutting requirements 82%. Variable load works well with serverless inference. Low-latency applications justify on-demand pricing but should still implement caching for 20-60% savings.
Don’t optimize blindly. Production serving with SLAs, real-time inference requirements, and regulatory constraints may justify premium pricing. The goal isn’t minimum spend—it’s maximum value per dollar.
Taking Action
Start with spot instances for training workloads. The 70-90% savings require only checkpoint discipline—save state every 15 minutes and configure auto-resume. Pinterest’s $4.8 million annual savings prove the model scales.
Implement FinOps monitoring next. NVIDIA DCGM plus Prometheus gives you GPU utilization visibility. Right-size instances based on actual usage data, not guesswork.
Then evaluate advanced strategies. If you run high-volume inference, watch for GPU pooling capabilities from cloud providers—82% reductions change infrastructure economics. If you’re training massive models on TensorFlow, run TPU cost comparisons. The 4× advantage compounds at scale.
GPU costs won’t decrease. TSMC raised prices, demand keeps climbing, and data centers consume more electricity every quarter. But the gap between wasteful and optimized spending is enormous. Organizations wasting 30-50% on over-provisioned resources are funding their competitors’ AI advantages.
Optimization isn’t optional anymore. It’s competitive survival.