
Chinese AI firm DeepSeek released DeepSeek V4 on April 24, 2026 with a technical breakthrough that challenges assumptions about long-context AI costs. The new model processes 1 million tokens while using only 10% of the memory required by DeepSeek V3.2—a 90% reduction achieved through a Hybrid Attention Architecture that combines two complementary compression techniques. Moreover, performance rivals GPT-5.5 and Claude Opus 4.7, yet DeepSeek V4 costs 6-7x less per API call. Open-source weights dropped on Hugging Face the same day under MIT license.
The Memory Bottleneck Problem
Standard transformer attention mechanisms scale quadratically with sequence length. Consequently, when you double your context from 500K to 1M tokens, memory consumption quadruples. This O(n²) scaling made long-context models prohibitively expensive, limiting real-world applications like processing entire codebases or analyzing lengthy legal documents in a single inference pass.
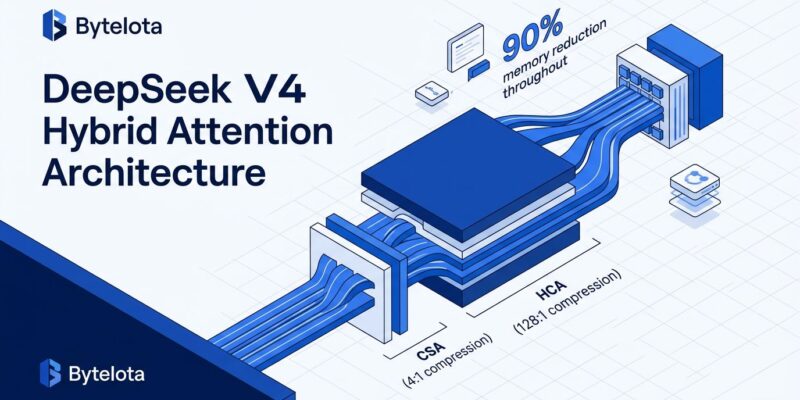
DeepSeek V4 breaks this constraint with Hybrid Attention, which interleaves Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) across transformer layers. CSA applies 4:1 compression to the key-value cache, then runs sparse attention over the top-512 selected entries. Meanwhile, HCA goes further with 128:1 compression ratios—reducing the KV cache to less than 1% of its original size—then applies dense attention over the aggressively compressed sequence. Both mechanisms include a sliding window over the last 128 raw tokens to preserve local dependencies.
The engineering result: DeepSeek V4-Pro requires only 27% of the FLOPs and 10% of the KV cache memory compared to V3.2 when processing 1 million tokens. This is not a theoretical improvement. NVIDIA’s GB200 NVL72 hardware tests show sustained throughput above 150 tokens per second per user at that context length.
Two Models, Competitive Performance
DeepSeek shipped two variants. V4-Pro packs 1.6 trillion total parameters with 49 billion active per token using mixture-of-experts routing. V4-Flash trims that to 284 billion total and 13 billion active for faster inference at lower cost. Furthermore, both support the full 1 million token context window.
Benchmarks show V4-Pro beating GPT-5.4 on Codeforces competitive programming tasks with a rating of 3,206 versus 3,168. On SWE-Bench Verified (the practical coding benchmark), DeepSeek hits 91.2%—close behind Claude Opus 4.7’s 93.9%. Additionally, knowledge tasks like MMLU-Pro (87.5%) and GSM8K math (92.6%) place it roughly 3-6 months behind GPT-5.5 and Gemini-3.1-Pro, but that gap is narrowing fast. DeepSeek’s claim of “rivaling the world’s top closed-source models” holds up under scrutiny for coding workloads.
Price War Escalation
DeepSeek V4-Pro launched at $0.145 per million input tokens and $1.74 per million output tokens. However, on April 27, three days after release, DeepSeek slashed V4-Pro prices by 75% as part of what Bloomberg called a “Chinese price war” among domestic AI providers. Cached input tokens now cost $0.03 per million—a 90% discount on repeated context. V4-Flash pricing starts even lower at $0.14 input and $0.28 output per million tokens.
Compare that to GPT-5.5 and Claude Opus 4.7, which run approximately $1.02 per million input tokens and $10.44 per million output tokens. Therefore, processing 1 million tokens through DeepSeek V4-Pro costs around $2 versus $12 for OpenAI or Anthropic. That 6x cost advantage changes the economics of long-context applications—legal document analysis, research synthesis, and repository-level code review become viable at scale.
DeepSeek announced the price cuts are permanent. This is not a promotional discount. It is a structural cost advantage driven by the memory efficiency of Hybrid Attention.
Practical Developer Use Cases
The 1 million token context window unlocks applications that were previously impractical. A 300,000-line codebase fits entirely in context for DeepSeek V4, enabling repository-level refactoring, multi-file debugging, and architecture analysis without chunking or vector database lookups. Similarly, legal teams can process full contracts and case files in a single inference pass. Research workflows can synthesize insights across thousands of papers without round-trips to retrieval systems.
A survey of 85 DeepSeek developers using V4-Pro found 52% consider it ready to replace their primary coding model, with another 39% leaning toward adoption. Internal benchmarks on PyTorch, CUDA, Rust, and C++ codebases showed a 67% pass rate on complex refactoring tasks. Notably, deployment infrastructure already exists—vLLM, SGLang, and NVIDIA NIM published integration guides within 24 hours of the V4 release.
Open Source Strategy Continues
DeepSeek V4 weights are available on Hugging Face under MIT license—you can download, modify, and deploy commercially without restrictions. Four repositories cover V4-Pro, V4-Pro-Base, V4-Flash, and V4-Flash-Base variants. The technical paper with full architecture details ships alongside the weights.
This continues DeepSeek’s disruptive open-source playbook. In January 2025, DeepSeek V3 and R1 shocked the AI industry by demonstrating that a model built for under $6 million in two months on lower-tier NVIDIA chips could compete with frontier models costing hundreds of millions. The V3 release triggered a 17% single-day drop in NVIDIA’s stock price, erasing nearly $600 billion in market capitalization, and challenged the prevailing narrative that U.S. companies held an unassailable AI lead.
V4 is less shocking because the market expected it, but the efficiency leap is significant. Hybrid Attention proves that architectural innovation can deliver cost and performance gains that brute-force scaling cannot match. Consequently, OpenAI and Anthropic now face pressure to either match DeepSeek’s pricing or explain why their closed-source models justify a 6x premium.
Open Questions on Adoption
DeepSeek V4 launched five days ago. Production battle-testing is minimal. The compression techniques underpinning Hybrid Attention trade some accuracy for memory efficiency—whether that trade-off is acceptable depends on your use case. Enterprises comfortable with open-source AI will test DeepSeek aggressively for cost savings, but many will hesitate due to support concerns, regulatory requirements, or geopolitical risk (U.S. government agencies banned DeepSeek in early 2025 over data security).
Price competition will intensify. OpenAI and Anthropic cannot ignore a 6x cost gap indefinitely. Expect either matching price cuts or technical responses that justify their premium—better reasoning, multimodal capabilities, or enterprise features. Furthermore, DeepSeek’s move also pressures other Chinese AI labs (Alibaba, Baidu, Tencent) to cut prices or risk losing developer mindshare.
The efficiency race is now as important as the capabilities race. DeepSeek V4 shifts the conversation from “who has the biggest model” to “who delivers the best value per token.” That is a healthier dynamic for developers.






