Day 2 of the Databricks Data + AI Summit 2026 landed today, and if you expected flashy demos and vague roadmap promises, you were in the wrong room. The announcements that came out of Moscone Center this morning are almost entirely about making production boring — managed memory, spend governance, SQL-native document parsing. For the 30,000-plus attendees and the developers watching from home, this is the signal: agentic AI infrastructure is maturing faster than most people expected.
Agent Bricks: No Longer a Preview
Databricks launched Agent Bricks at last year’s summit as a framework for building production-grade AI agents. A year later, the numbers are hard to argue with: 100,000-plus agents built on the platform, processing over one quadrillion tokens annually. The enterprise adoption list includes AstraZeneca, 7-Eleven, Fox Corporation, and Block — a cross-industry spread that isn’t the usual suspects from one vertical.
The Day 2 GA announcements for Agent Bricks include Custom Agents on Apps (support for any agent framework — LangGraph, OpenAI Agents SDK, or your own), a Supervisor Agent for orchestrating multi-agent pipelines, and Document Intelligence for structured data extraction from unstructured documents.
The framing that Databricks keeps returning to is worth repeating: “The core agent loop is just 1% of the work. The other 99% is token capacity, deployment, security, evaluation, monitoring, context, sharing.” Anyone who has shipped an agent past a Jupyter notebook knows this is true. The LLM call is the easy part.
Managed Agent Memory: The DX Win You Actually Wanted
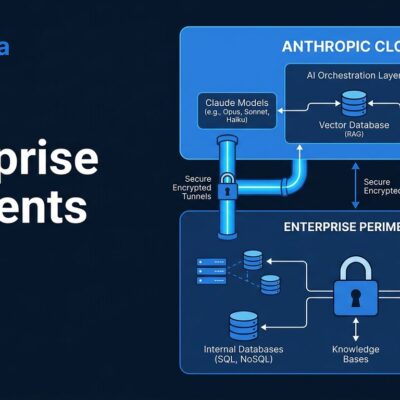
The most immediately useful announcement for working developers is managed memory for agents. Previously, building a stateful agent meant spinning up your own Postgres instance, managing connection pools, handling authentication between your app and the database, and writing checkpoint logic yourself. It was the kind of infrastructure work that had nothing to do with what the agent was actually supposed to do.
Databricks is now handling all of that under the hood, powered by Lakebase — their serverless Postgres product that launched earlier this month. Memory comes in two tiers: short-term (within-session, using thread IDs and checkpointers) and long-term (cross-session and cross-agent). It integrates natively with LangGraph checkpointers and the OpenAI Agents SDK, and Databricks handles the auth between your app and Lakebase automatically.
This is what “managed” is supposed to mean. One API call instead of a database setup checklist.
Unity AI Gateway: Spend Caps Are Now Infrastructure
Earlier this month, ByteIota covered the story of an AI agent that racked up $6,531 in AWS charges overnight. That story resonated because it is not an edge case — it is what happens when you put agents in production without guardrails. Databricks is addressing this directly with new features in Unity AI Gateway.
The headline feature is hard spend caps: Unity AI Gateway can auto-stop requests when a budget threshold is exceeded, at the granularity of user, team, tool, or use case. Alongside that are smart routing (route to the most cost-effective model that meets quality requirements), fallback models (auto-route around rate limits), and runtime policy enforcement at the gateway layer rather than just at the data layer. The governance scope covers models, MCP services, agents, and skills — not just data access.
Runaway agent costs are a documented, real problem. Treating spend governance as infrastructure — something enforced at the platform level rather than per-application — is the right call.
Document Intelligence: SQL-Native Doc Parsing
Document Intelligence is now GA, and the SQL-native interface is what makes it interesting. Three new functions — ai_parse_document, ai_extract, and ai_classify — let you parse PDFs, scanned images, and handwritten documents directly from SQL without switching to a separate Python pipeline. The functions preserve document structure including nested tables, sections, and headers.
SELECT ai_parse_document(content) as parsed,
ai_extract(ai_parse_document(content), 'invoice_number', 'total_amount', 'vendor') as fields
FROM raw_documents
WHERE document_type = 'invoice'Data engineers who live in SQL and Databricks do not want to context-switch into a separate pipeline to handle invoices, contracts, or forms. This closes that gap. Databricks claims highest quality and lowest cost versus frontier LLMs and specialized document AI providers — a strong claim worth testing against your own document types. See the ai_parse_document documentation for the full function reference.
The Bottom Line: A Reasonable Bet, with Conditions
Databricks is making a specific platform bet: that enterprise AI agents should live where enterprise data already lives. The announcements from Day 2 — managed memory powered by Lakebase, spend governance in Unity AI Gateway, document parsing in SQL — all reinforce the same thesis. If you are already deep in the Databricks stack, this is a coherent and compelling set of additions.
The tension is for everyone else. These features are good. But each one deepens the dependency on a single vendor for what is quickly becoming critical path infrastructure. Managed memory, cost governance, model routing — these are not nice-to-haves. If Databricks is in your critical path for all of them, that is a concentration risk worth thinking through before you commit.
The platform play might be the right answer for most large enterprises. Whether it is the right answer for your organization depends on how much of your stack you are comfortable centralizing. The Agent Bricks Day 2 changelog is worth reading if you are evaluating the platform, and TechTimes’ summit coverage has additional context on catalog federation and Lakewatch.