University of Cambridge researchers published a breakthrough in Science Advances on April 22, 2026: a neuromorphic chip using modified hafnium oxide memristors that could slash AI hardware energy consumption by 70%. The device operates at switching currents roughly 1 million times lower than conventional chips while achieving hundreds of stable conductance levels required for in-memory computing. This addresses a critical bottleneck—AI data centers consumed 415 terawatt-hours globally in 2024 (1.5% of world electricity), projected to hit 1,050 TWh by 2026, making AI infrastructure the 5th largest energy consumer globally, between Japan and Russia.
Seventy percent energy reduction sounds revolutionary—but there’s a catch. The Cambridge device requires manufacturing temperatures around 700°C, incompatible with standard semiconductor fabrication. Meanwhile, commercial neuromorphic chips from Intel and IBM are entering the market in 2026 with proven deployments, yet industry consensus remains clear: neuromorphic computing hasn’t found its killer app and can’t simply replace existing AI infrastructure.
How Neuromorphic Computing Differs from GPUs
Traditional AI runs on von Neumann architecture—separate CPU and memory forcing constant data movement between processing and storage. Neuromorphic chips combine memory and processing in the same location using memristors, nanoelectronic devices that remember their resistance state and function as artificial synapses. Cambridge’s breakthrough uses modified hafnium oxide with added strontium and titanium to create ultra-stable memristors with switching currents below 10 nanoamps—1 million times lower than conventional devices.
Instead of clock-driven continuous computation, neuromorphic systems use spiking neural networks where neurons “fire” only when electrical stimulus reaches a threshold. This event-driven processing mimics how biological brains work: neurons communicate through discrete spikes, not constant signals. The Cambridge device demonstrated hundreds of stable conductance levels (analog computing, not just binary 0/1) and remained stable through tens of thousands of switching cycles.
Consequently, the energy savings aren’t from faster traditional computing—they’re from eliminating the architectural inefficiency of shuttling data between separate memory and processing units. By storing and processing in the same location, neuromorphic chips avoid the power-hungry memory bottleneck that plagues GPU and TPU architectures.
Lab Breakthrough Doesn’t Mean Production Deployment
Cambridge’s 70% energy reduction is lab-stage research that won’t reach production for 5-10 years. The device requires process temperatures around 700°C, well above the 400-450°C standard for semiconductor fabrication. Manufacturing challenges include CMOS compatibility, production scalability, and maintaining device consistency at nanoscale.
However, commercial neuromorphic chips are here now. Intel’s Loihi 3 launched commercially in 2026 with 8 million neurons, 64 billion synapses, and 1.2W peak power—1,000 times more efficient than GPUs for real-time robotics tasks. In demonstrations, a quadruped inspection robot equipped with Loihi 3 operates 72 hours on battery versus 8 hours with a GPU, detecting pipeline micro-cracks at 5cm resolution while walking at 1 m/s.
IBM’s NorthPole, also entering production in 2026, achieves 72.7x higher energy efficiency for LLM inference and 25x better efficiency for image recognition compared to high-end GPUs. The architecture co-locates memory and compute units across 256 cores, targeting vision-heavy enterprise and defense applications. Mercedes-Benz and BMW are integrating neuromorphic vision systems for sub-millisecond autonomous braking responses.
Nevertheless, the industry hasn’t identified neuromorphic computing’s killer application. These chips excel at narrow use cases—edge AI, robotics, sensor fusion—but can’t replace GPU infrastructure for training large models. The software ecosystem remains immature compared to PyTorch and TensorFlow, and training spiking neural networks presents challenges that haven’t been fully solved.
Competing Approaches to AI Energy Efficiency
AI energy efficiency has multiple competing solutions with no clear winner. Google’s TPU 8 split into specialized chips—TPU 8t for training, TPU 8i for inference—optimizes within traditional von Neumann architecture. Nvidia focuses on GPU optimization and massive-scale parallelism. Neuromorphic takes a fundamentally different approach by eliminating the memory bottleneck entirely.
Each architecture has strengths. GPUs dominate training with mature tooling and massive parallel compute. TPUs excel at cloud-scale inference for transformer models and dense matrix operations. Neuromorphic chips win at battery-powered edge deployments, delivering 20-30x better performance-per-watt for inference tasks and sub-100ms latency for real-time applications.
The trade-offs are real. Neuromorphic gives up training ease, accuracy on dense tasks, and software ecosystem maturity in exchange for extreme energy efficiency. For infrastructure teams, the future looks hybrid: cloud GPU training feeding neuromorphic edge inference, not one architecture replacing the other.
Training Spiking Neural Networks Remains Unsolved
Spiking neural networks powering neuromorphic chips face significant training challenges. Spike-based activation is non-differentiable, breaking traditional backpropagation algorithms that work for conventional neural networks. Accuracy still lags behind standard deep neural networks on large-scale tasks, despite dramatic energy advantages.
Current approaches train models on cloud GPUs using conventional frameworks, then convert and deploy to neuromorphic chips for inference. Intel’s Lava SDK and IBM’s proprietary tools offer limited capabilities compared to the mature PyTorch and TensorFlow ecosystems developers rely on. Research continues on spike-timing dependent plasticity (STDP) and surrogate gradient methods, but production-ready training solutions remain years away.
Moreover, computational costs for simulating realistic spiking neural network models exceed traditional artificial neural networks during training. While neuromorphic chips deliver 99.5% energy reduction for inference, the accuracy-efficiency trade-off means developers sacrifice performance on dense vision and language tasks. For 99% of developers working on LLMs, computer vision, or cloud AI, neuromorphic computing is irrelevant in 2026.
What Developers Should Actually Do
Don’t learn neuromorphic programming unless you work in industrial robotics, autonomous vehicles, or medical device edge AI. The skill investment doesn’t pay off for general software development, LLM training, or cloud-based applications. Neuromorphic chips target narrow domains where battery life, real-time latency, and energy efficiency outweigh accuracy demands.
Infrastructure teams monitoring AI costs should track Intel Loihi 3 and IBM NorthPole deployments through 2026-2027 as proof points. Current applications include warehouse robotics (72-hour battery operation), autonomous vehicle braking (sub-millisecond response), and medical neuroprosthetics with sensory feedback. These aren’t general-purpose platforms—they’re specialized tools for specific problems.
The realistic timeline for broader adoption spans 2027-2029 for consumer devices like AR glasses and smartphones, assuming the industry identifies a killer application. For now, the smart approach is hybrid: continue using GPUs and TPUs for training and cloud inference while watching neuromorphic edge deployments. Don’t bet your career on neuromorphic computing unless you’re already deep in embedded systems or robotics.
Key Takeaways
- Cambridge’s 70% energy reduction is real technical progress, but lab breakthroughs face a 5-10 year timeline to production deployment. Manufacturing at 700°C temperatures presents CMOS compatibility challenges that won’t be solved quickly.
- Commercial neuromorphic chips (Intel Loihi 3, IBM NorthPole) are available now for narrow use cases like robotics and edge AI, delivering 1,000x efficiency gains for real-time inference. However, they can’t replace GPUs for training or general AI infrastructure.
- Neuromorphic computing won’t solve AI’s energy crisis alone—it’s one approach among multiple competing architectures. Google’s TPU specialization, Nvidia’s GPU optimization, and neuromorphic in-memory computing will likely coexist in hybrid deployments.
- Training spiking neural networks remains unsolved. Non-differentiable spikes break traditional backpropagation, forcing hybrid approaches (GPU training, neuromorphic inference) with accuracy-efficiency trade-offs that limit applicability.
- Most developers can ignore neuromorphic in 2026. Exceptions are specialists in industrial robotics, autonomous vehicles, and medical device edge AI. Watch 2027-2029 for potential consumer adoption if a killer app emerges.
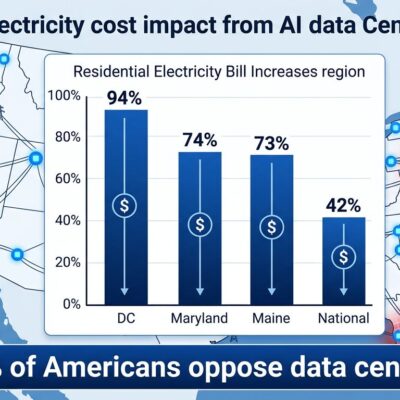
Data centers powering AI consumed $25 billion in environmental damage costs in 2024, with projections showing AI infrastructure becoming the world’s 5th largest energy consumer by late 2026. Architectural innovation matters, but expecting neuromorphic chips to quickly replace established GPU and TPU infrastructure misses the complexity of production deployment, software ecosystem maturity, and finding applications where extreme energy efficiency justifies accuracy trade-offs.