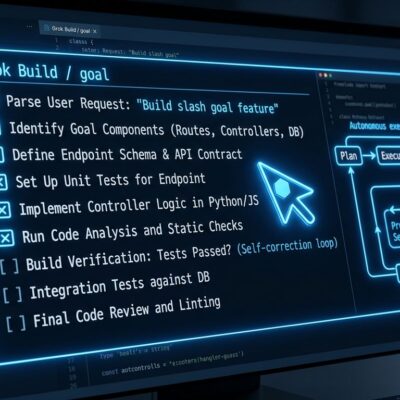
On April 27, 2026, Alec Radford—creator of GPT, GPT-2, CLIP, and Whisper—released his first major project since leaving OpenAI: Talkie, a 13-billion-parameter vintage language model trained exclusively on text published before 1931. The model has never seen the internet, computers, DNA structure, nuclear weapons, or transistors. Yet researchers are testing whether it can reason about these modern concepts anyway. If a 1930s AI can understand 2026 ideas using only pre-1931 knowledge, it would provide experimental evidence that LLMs truly generalize and reason—not just memorize and regurgitate training data. This directly challenges the “stochastic parrot” criticism that has dogged AI since 2021.
The Experiment: 260 Billion Tokens of Pre-1931 Knowledge
Talkie isn’t a gimmick. When the person who literally invented the GPT paradigm releases something, the AI research community pays attention. Radford’s papers have been cited over 190,000 times. Sam Altman called him “a genius at the level of Einstein.” He achieved all this without a PhD—just a Bachelor’s degree and relentless focus on fundamental AI research.
The experiment is straightforward: train a 13B parameter model on 260 billion tokens of English text from books, newspapers, scientific journals, patents, and case law—all published before December 31, 1930. Release it as open source (Apache 2.0 license) on Hugging Face in two variants: a base model and an instruction-tuned chat version.
Then test whether it can reason about concepts that didn’t exist in 1930. Can it write Python code when given examples, despite never encountering digital computers? Can it grasp DNA structure, discovered in 1953? Nuclear weapons, first tested in 1945? Internet protocols, invented in the 1960s-80s?
Early results are mixed but intriguing. The model managed simple one-line Python programs and minor code modifications. It demonstrated understanding of inverse functions through single-character edits to a rotation cipher. However, it underperforms modern models on standard benchmarks, and data contamination issues mean it knows some post-1930 events—FDR’s presidency, WWII details, Churchill facts that don’t match a 1930 cutoff.
Why This Matters: The Stochastic Parrot Debate
In 2021, Emily M. Bender, Timnit Gebru, and colleagues published “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” The paper argued that LLMs are “stitching together sequences of linguistic forms according to probabilistic information about how they combine, but without any reference to meaning.” They’re limited by training data, just stochastically repeating dataset contents. They don’t understand if output is incorrect or inappropriate.
The term “stochastic parrot” became the 2023 AI-related Word of the Year. It captures a fundamental anxiety: are LLMs intelligent, or just very sophisticated autocomplete?
The defense came from AI luminaries. Geoffrey Hinton countered: “To predict the next word accurately, you have to understand the sentence.” A 2024 Scientific American investigation described state-of-the-art models solving novel tier-4 mathematics problems and producing coherent proofs—indicating reasoning abilities beyond memorization. Evidence suggests frontier AI systems build structured internal representations, “world models” that abstract concepts rather than just storing text patterns.
Talkie provides experimental data for this philosophical debate. If a model trained only on 1930s knowledge can reason about modern concepts, it can’t have memorized what it never saw. That would prove genuine generalization. If it fails, it supports the “stochastic parrot” view. Either way, we move from philosophy to experimental evidence.
Radford and his collaborators describe vintage LLMs as “contamination-free by construction,” enabling experiments impossible with modern web-trained systems. Standard benchmarks are compromised because test data leaks into training sets. A 1930s model sidesteps this entirely.
Honest Limitations: What Doesn’t Work
The researchers are refreshingly candid about problems. Data contamination remains an issue despite anachronism detection efforts. The model demonstrates awareness of events after its intended cutoff. One Hacker News commenter noted it “seems to be using more info from pre-1900 rather than 1930” and observed the model lacks awareness of the Great Depression—a defining 1930 event.
Another critical assessment captured the accuracy problem: “The first sentence or two has info you might get from Google. Then it riffs on that, drifting off into plausible nonsense.” A developer warned: “Don’t ask this thing questions to which you do not know the answer. You will pollute your brain.”
Performance gaps exist beyond contamination. Poor optical character recognition of historical documents and subject matter distribution differences in historical texts degrade benchmark scores. And there’s representation bias: historical texts were “dominated by” certain groups. Voiceless populations—women, minorities, non-Western cultures—remain largely absent.
These limitations don’t invalidate the experiment. They’re part of honest science. This is a research tool testing fundamental questions about AI reasoning, not a production system competing with ChatGPT. The Hacker News discussion (345 points, 116 comments) reflects that understanding—enthusiastic about novelty and experimental approach, critical about execution, interested in research applications.
What This Opens Up for AI Research
Radford’s team plans to release a GPT-3-level vintage model by summer 2026, potentially expanding to over one trillion tokens of historical text for eventual GPT-3.5-level capabilities.
Beyond scaling, this approach enables new research directions. A 2024 PNAS study suggested historical LLMs could simulate responses of past populations, testing the historical generalizability of psychological phenomena. Can we study pre-modern decision-making, social motives, cooperation patterns using vintage models as time capsules?
Hacker News users proposed ambitious experiments: train models on narrow time windows to observe “psychoses,” test whether pre-1915 models could independently derive general relativity, use vintage models to predict post-1930 scientific developments, create personal “time capsule” models from archived emails and chats.
The broader implication isn’t about Talkie specifically. It’s about moving AI research beyond pure scaling toward more rigorous experimental methodology. Knowledge cutoffs, vintage training data, contamination-free benchmarks—these are tools for testing fundamental questions empirically rather than philosophically.
Key Takeaways
- Talkie is a 13B parameter model trained on 260 billion tokens of pre-1931 English text, released open source (Apache 2.0) by GPT creator Alec Radford and collaborators.
- The experiment tests whether LLMs genuinely reason or just memorize by removing modern knowledge from training data—if a 1930s model can understand 2026 concepts, it proves generalization beyond pattern-matching.
- Early results are mixed: manages simple Python code and inverse function understanding, but suffers from data contamination (knows some post-1930 events) and accuracy issues (drifts into plausible nonsense).
- This provides experimental evidence in the “stochastic parrot” debate about whether LLMs understand meaning or just statistically mimic text patterns.
- Access both models on Hugging Face: the base model and instruction-tuned chat variant for researchers exploring historical NLP, temporal generalization, and contamination-free benchmarking.