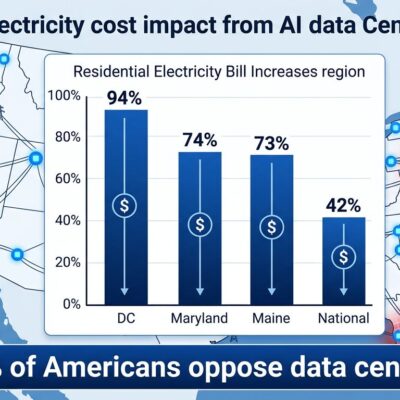
OpenAI stopped evaluating models against SWE-bench Verified on February 23, 2026, after discovering at least 59.4% of failed test cases were flawed and every frontier model showed training data contamination. The performance gap proves it: top models score 70-80% on Verified but only 23-58% on SWE-bench Pro. That’s not capability variation—it’s evidence the benchmark measured memorization, not coding skill.
The Benchmark Collapsed Under Its Own Flaws
SWE-bench Verified launched in August 2024 as a human-validated subset of 500 Python tasks from real GitHub issues. It became the gold standard for comparing AI coding assistants, influencing vendor marketing and enterprise decisions. But OpenAI’s audit revealed two fatal problems.
First, 59.4% of audited problems contain flawed test cases that reject correct solutions. When the majority of your benchmark penalizes right answers, you’re measuring which models accidentally align with broken assumptions, not actual capability.
Second, every frontier model—GPT-5.2, Claude Opus 4.5, Gemini 3—showed contamination. Models trained on GitHub data after June 2024 had seen the 500 Verified tasks during training, including solutions. They weren’t solving through reasoning; they were recalling memorized patches.
The Performance Gap Proves the Problem
March 2026 leaderboards showed Claude Opus 4.5 at 80.9% on Verified, while the same generation scores around 23% on SWE-bench Pro. Kimi K2.6, which topped Pro at 58.6%, would theoretically exceed 100% on Verified if the scaling held.
The gap exists because the benchmarks measure different things. Verified’s 500 tasks include 161 problems requiring one or two line modifications—trivial fixes inflated by contaminated training data. Pro’s 1,865 tasks average 107 lines across 4.1 files, minimum 10-line changes, with over 100 tasks demanding 100+ line modifications. It tests multi-file reasoning on enterprise-grade complexity.
Companies made AI tool choices based on Verified scores—decisions informed by a benchmark where 59% of tests were defective and 100% of top models had seen the answers.
Data Contamination Is an Industry-Wide Crisis
SWE-bench Verified isn’t isolated. Retrieval-based audits found over 45% overlap on QA benchmarks, GPT-4 infers masked MMLU answers 57% of the time, and models score up to 10% higher on GSM8K versus alternative problems. When researchers tested Mixtral 8x22B, Phi-3-Mini, Llama-3-8B, and Gemma 7B, they found widespread contamination.
This happens because foundation models train on massive datasets where GitHub is a primary source—but also where benchmark tasks originate. There’s no practical mechanism to prevent public repositories from appearing in training data.
It’s the AI equivalent of students getting exam questions in advance. Scores rise, but capability doesn’t improve, and we can’t distinguish progress from memorization.
Developers Already Don’t Trust AI Code
The SonarSource 2026 State of Code survey found 96% of developers don’t fully trust AI-generated code, yet only 48% always verify before committing. Usage tells a different story: 84% use AI tools (up from 76% in 2024), but trust dropped from 40% to 29%.
Teams spend 24% of their work week checking and validating AI output, with 38% saying reviewing AI code takes more effort than reviewing human code. Flawed benchmarks amplify this trust crisis—when the evaluation standard itself is broken, leaderboard claims become noise.
SWE-bench Pro Resists Contamination, Measures Complexity
OpenAI now recommends SWE-bench Pro. Scale built it with contamination resistance: strong copyleft licenses (GPL) discourage commercial training inclusion, and a held-out private set remains undisclosed. Tasks come from 11 public repositories plus commercial codebases from real startups.
More importantly, Pro eliminates trivial tasks. The dramatically lower scores (23% for most frontier models) aren’t measurement failure—they’re accurate reflection of current AI coding limitations.
The tradeoff is transparency versus contamination. Private held-out sets prevent leakage but make results harder to reproduce. GPL licensing helps but doesn’t stop training on public forks. There’s no perfect solution—just better-informed compromises.
Test AI Tools on Your Own Codebase, Not Leaderboards
Benchmark scores are directionally useful, but they’re not purchasing decisions. Even widely-adopted, human-validated benchmarks can measure the wrong thing for years before someone audits them.
Evaluate AI coding tools on your actual repositories, with your team’s workflows, solving your specific problems. Real-world performance in your environment matters more than leaderboard position. The 59% failure rate OpenAI found should make us skeptical of all automated evaluation—human judgment and real-world testing remain the most reliable signals.