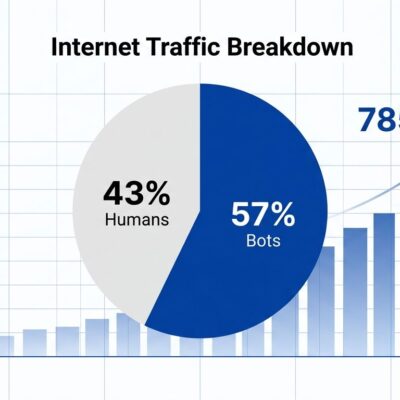
Developers using AI coding tools like Cursor and GitHub Copilot feel 24% faster but are actually 19% slower, according to research from METR (Feb-June 2025) analyzing experienced developers on familiar codebases. The perception-reality gap is 39 percentage points: developers predicted speedups, worked slower, then still believed they’d been faster afterward. New research examining 806 open-source repositories adopting Cursor confirms the pattern—transient velocity increase followed by persistent complexity increase. With 84% of developers now using AI tools but only 24% trusting them, the productivity paradox is real and costing teams far more than subscription fees.
The Numbers Don’t Lie
The arXiv study from November 2025 analyzed 806 open-source repositories adopting Cursor using state-of-the-art difference-in-differences causal estimation. The findings: short-term speed gains that vanish as static analysis warnings and code complexity stay elevated indefinitely. Faros AI’s analysis of 10,000+ developers quantifies the damage precisely. Teams see a 9% increase in bugs per developer, 154% larger pull request sizes, and 91% longer review times. The velocity gains in code generation get consumed—and exceeded—by quality problems downstream.
Stack Overflow’s 2025 survey of 49,000 developers reveals why. The top frustration: 66% cite AI code being “almost right, but not quite.” The second: 45% report debugging AI code consumes more time than code generation saves. Trust has collapsed alongside rising adoption. Only 3.1% “highly trust” AI tool accuracy, while 46% actively distrust it. Developers are using tools they don’t believe in because they feel faster—even when they’re measurably slower.
Comprehension Debt: The Hidden Cost
Addy Osmani coined “comprehension debt” in March 2026 to describe the gap between code that exists in your system and code any human genuinely understands. Unlike technical debt which announces itself through failures, comprehension debt accumulates silently. Tests pass. Code looks clean. But team members can’t explain design decisions or predict how changes will ripple through the system. Anthropic’s study found engineers using AI scored 17% lower on comprehension quizzes compared to those writing code manually—50% versus 67% accuracy—with the largest declines in debugging and conceptual understanding.
Real teams hit a “Week 7 wall.” After shipping AI-assisted code for weeks, they suddenly can’t make simple changes without breaking unexpected components. The root cause: nobody understands what the code actually does or why it was written that way. AI generates code far faster than humans can evaluate it, breaking the traditional review bottleneck that once forced comprehension. Organizations measure velocity and DORA metrics but can’t detect comprehension deficits. The incentives optimize for throughput while understanding erodes invisibly.
91% Longer Reviews, Infinitely Harder
PR review time increases 91% on high-adoption teams according to Faros AI’s research. But the cognitive burden is even worse than the time suggests. Apiiro’s 2024 research found PRs with AI code required 60% more reviewer comments on security issues. The security risks are staggering: AI-generated code introduced 322% more privilege escalation paths and 153% more design flaws compared to human-written code. The problem, as Cerbos documented: AI code is verbose, plausible-looking, and wrong in ways that require sustained deep attention to catch.
A developer who spent “10-12 hour days paired with Claude for months” described it bluntly on Hacker News: “The cognitive cost of reviewing AI output is significantly higher than reviewing human code. It’s verbose, plausible-looking, and wrong in ways that require sustained deep attention to catch.” Multiple developers report AI making subtle breaking changes—renamed parameters, return values suddenly wrapped in Promises—that pass tests but break downstream dependencies days later. Reviewers must reverse-engineer what code should do versus what it does, creating cognitive friction that doesn’t exist with intentional human code. This is where individual speed gains die: in the review queue.
When AI Works vs When It Fails
The architecture-execution distinction determines whether teams succeed or hit the Week 7 wall. When humans drive architecture decisions and use AI for execution—boilerplate generation, test scaffolding, documentation—complexity stays manageable. When AI drives both architecture and implementation, quality degrades significantly. Teams that let AI design systems end up with plausible-looking but fundamentally flawed architectures that become unmaintainable.
AI excels at repetitive, bounded tasks where developers report 30-50% speed gains. Boilerplate generation, CRUD operations, database migrations, test writing. The workflow that works: brainstorm detailed specifications with AI, outline step-by-step plans, compile comprehensive architecture documents, then generate code. Developers report success using autocomplete tools like Copilot and Cursor for daily feature work, then switching to reasoning models like Claude Opus 4.5 for genuinely hard problems requiring multi-file refactors or architectural changes.
The failures cluster around three scenarios: novel algorithms requiring deep reasoning, complex state management needing system context, and architecture decisions about future maintainability. AI also struggles on mature codebases—the METR study specifically tested experienced developers on familiar projects averaging 1.1 million lines and 10+ years old. In that context, AI’s lack of system understanding becomes fatal.
The Perception Gap Explained
Before starting tasks, developers predicted AI would make them 24% faster. Reality: 19% slower. After finishing, they still believed AI had sped them up by roughly 20%. The perception-reality gap persists even when confronted with timing data. This explains why adoption continues despite frustration: 75% of developers report feeling more productive according to Google’s 2024 DORA research, yet every 25% increase in AI adoption correlates with 1.5% delivery speed decline.
The disconnect exists at every level. Individual developers feel faster. Teams report shipping more. But Faros AI’s analysis of 1,255 teams shows organizations see no measurable improvement in delivery velocity or business outcomes across throughput, DORA metrics, and quality KPIs. The psychology is simple: developers count code generation time as “work” but discount review, debugging, and fixing subtle bugs as separate from the AI productivity equation. The tools save time writing code but cost more time ensuring that code actually works correctly.
What This Means for Teams
The productivity paradox isn’t solvable with better models alone—it’s fundamental to how AI coding tools work. Organizations need new practices built around this reality. Budget for 91% longer review times instead of assuming AI speed translates to team speed. Make quality assurance integral to AI workflows from day one: static analysis, security scanning, comprehensive testing. Measure comprehension debt alongside velocity metrics by testing whether engineers can explain design decisions and predict system behavior.
Practical changes that work: Use AI as a “grokking tool” for understanding codebases before generating code. Ask it to explain architectural patterns and design decisions, not just write implementations. Recognize that “the last 30% is the hard part”—edge case handling, architecture refinement, and thorough testing require human judgment. Accept that trading less typing time for more reading and debugging time isn’t actually a productivity gain.
The teams that acknowledge the tradeoffs and build practices around them will win. Those that ignore comprehension debt will eventually hit the Week 7 wall where nobody understands the codebase well enough to change it safely. AI tools aren’t going away, and they do enable ambitious projects that would be infeasible manually. But they’re tools requiring rigorous human oversight, not replacements for developer judgment.
Key Takeaways
- The productivity paradox is measurable and real: developers feel 24% faster but work 19% slower according to studies analyzing 806 repos and 10,000+ developers.
- Comprehension debt accumulates silently as AI generates code faster than humans can understand it, creating a gap between code that exists and code anyone genuinely understands.
- Review burden consumes speed gains: PR review time increases 91%, and AI code requires 60% more security comments with 322% more privilege escalation paths.
- Success requires human architecture plus AI execution—let AI drive both and quality degrades significantly until teams hit the Week 7 wall.
- Don’t rely on developer sentiment to measure AI tool ROI. Use hard data on actual delivery velocity, bug rates, review time, and team comprehension.