This week, Hacker News is debating whether tokenmaxxing is dead. Over the last 90 days, the question answered itself. Meta shut down its internal AI token leaderboard within days of launching it. Uber burned through its entire 2026 AI budget in four months and capped employees at $1,500 per tool per month. Amazon issued internal guidance telling engineers to stop using AI “just to use AI.” Tokenmaxxing — treating token consumption as a productivity metric — is the AI era’s “lines of code” mistake, and companies are now paying the bill.
From Leaderboards to Caps
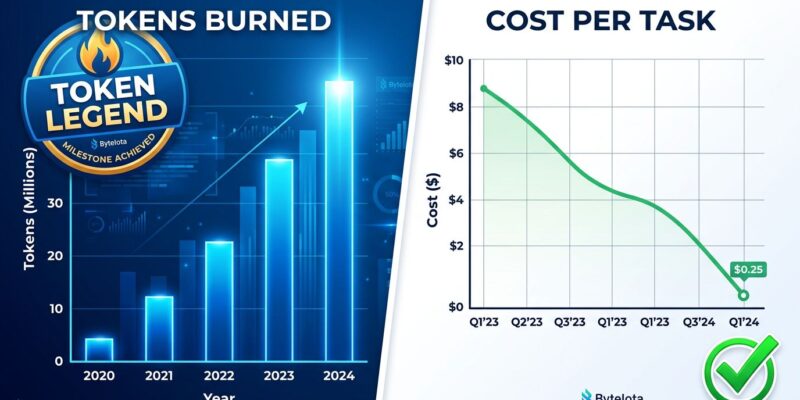
In April 2026, a Meta employee built “Claudeonomics” — an internal leaderboard tracking token consumption across 85,000 staff. Employees earned badges like “Token Legend” and “Session Immortal.” The top user was burning 281 billion tokens per month. The entire company collectively ran through roughly 60 trillion tokens in 30 days. Meta shut it down within days, citing data leakage — but the perverse incentives were the real problem.
Uber’s timeline was less dramatic but more expensive. By April, the company had exhausted its entire planned 2026 AI coding budget. Individual engineers were generating $500 to $2,000 monthly in token costs from agentic coding tools like Cursor and Claude Code. The company responded with a hard $1,500-per-tool monthly cap and a real-time dashboard so employees could track their own spend. Uber’s COO was publicly questioning whether AI tool spend was worth it — a stunning reversal for one of 2025’s most aggressive AI adopters. Meanwhile, Amazon issued internal guidance in May to “not use AI just to use AI,” and Salesforce was projecting a $300 million Anthropic bill while shopping for model routing solutions.
Per-developer token consumption rose 18.6x in nine months. Companies were already 3x over their full-year budgets by April. This was predictable the moment “tokens burned” became a proxy for “AI adoption progress.” You cannot gamify a cost metric and be surprised when costs explode.
The Data Was Never on Its Side
Here is the uncomfortable math behind tokenmaxxing: heavy AI users are roughly 2x more productive than their peers — but they spend 10x the tokens. That ratio is not AI ROI; it is AI waste. A 2x productivity gain for a 10x cost increase would be rejected for any other tool procurement decision. The fact that it was tolerated for months reflects how much the pressure to demonstrate “AI adoption” distorted judgment across engineering organizations.
The quality data is worse. In high-AI-adoption engineering environments, bugs increased 54% and code churn surged 861% over baseline. Accenture found meaningful chunks of enterprise AI budgets going toward basic tasks — converting PDFs to slides, routine administrative work — with minimal return. As Justice Kwak, Accenture’s agentic AI strategy lead, put it: “Spend is becoming very unpredictable; and leadership are still asking whether they’re getting value.”
More tokens does not mean more quality. It means more input to an LLM, which produces more output that someone then has to evaluate, accept or reject, and clean up. When agents run in loops or explore dead ends without stopping conditions, they consume tokens without producing anything. The measurement failure was treating the consumption of an input as equivalent to the production of an output. The correct metric is cost per accepted task — merged PRs, resolved tickets, shipped features per dollar of AI spend.
Context Engineering Is the Real Skill
The teams that avoided the tokenmaxxing trap were doing something different: treating the context window as a scarce, curated resource rather than a clipboard for everything. This discipline now has a name — context engineering — and its results are significant. Enterprise teams implementing it cut token costs 60 to 90 percent without losing output quality. The techniques are not exotic.
Compaction summarizes conversations near context window limits rather than letting them balloon. Anthropic reports an 84% token reduction in complex multi-turn evaluations using this approach. Model routing — defaulting routine tasks to cheaper model tiers and escalating only when queries actually need frontier capability — achieves more than 85% cost reduction while preserving around 95% of output quality. Sub-agent architectures return 1,000 to 2,000-token distilled summaries to orchestrators rather than full context, cutting waste while maintaining task coherence. For more on routing in practice, see LLM Model Routing in 2026: Cut AI Costs 70% With Smart Model Selection.
GitHub Copilot’s shift to usage-based billing in June 2026 is forcing this reckoning for teams that had not started it voluntarily. When developers see actual token costs per task for the first time, the pressure to optimize shifts from abstract budget discussions to concrete engineering choices. That visibility is the prerequisite for discipline. For context on what the billing change means in practice, see GitHub Copilot AI Credits: What the Token Billing Switch Costs You.
Token Discipline: What Comes Next
Vendors are moving toward outcome-based pricing to align incentives correctly. Pega Infinity 26 charges per completed case. Intercom Fin charges $0.99 per resolved conversation. HubSpot and Zendesk have similar models. When vendors only make money when the AI actually resolves something, they have a direct incentive to minimize wasted tokens and build more efficient agents. Enterprise survey data from Futurum in the first half of 2026 shows consumption-based and outcome-based pricing together now exceed 50% of buyer preference, while per-seat pricing has fallen to roughly 20%.
The FinOps discipline transformed cloud cost management — initial adoption, then an economic wall, then methodical practice matching infrastructure to actual workload needs. AI tokens are following the same curve. The companies that hit the wall in 2026 are now building the frameworks — per-task cost tracking, model routing layers, context compaction pipelines — that the rest will copy over the next 18 months. Tokenmaxxing is over. Token discipline is the work.
Key Takeaways
- Tokenmaxxing — using token consumption as a productivity metric — produced the same dysfunction as “lines of code” did in an earlier era. Meta, Uber, Amazon, and Salesforce all hit the wall in the first half of 2026.
- The correct AI productivity metric is cost per accepted task: merged PRs, resolved tickets, shipped features per dollar of AI spend — not raw token volume.
- Context engineering — compaction, model routing, sub-agent isolation, just-in-time retrieval — cuts token costs 60 to 90% without reducing output quality. This is the differentiating skill for 2026 and beyond.
- Outcome-based pricing (per resolution, per case) is emerging as the market structure that aligns vendor and buyer incentives. Expect it to dominate enterprise AI contracts within two years.