
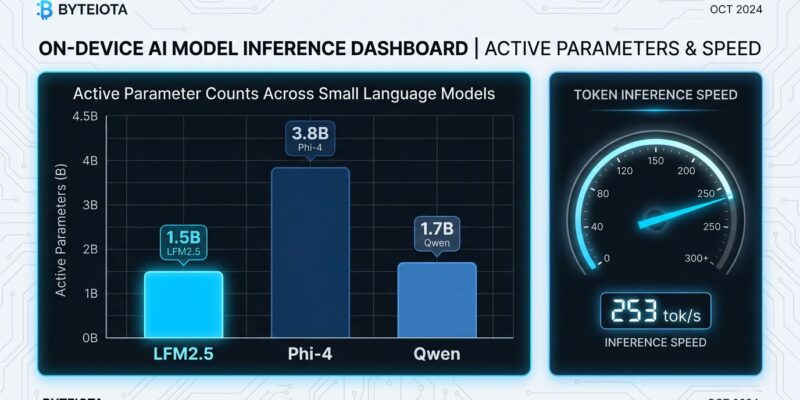
Liquid AI released LFM2.5-8B-A1B on May 28 — a model with 8.3 billion parameters that only activates around 1.5 billion of them during inference. That distinction is the entire story. It means you get reasoning capability closer to an 8B dense model while paying the compute cost of a 1.5B one. On an Apple M5 Max, it hits 253 tokens per second. On an iPhone, around 30. Memory footprint with quantization: under 6GB.
On-device AI just got a much more credible argument.
What “A1B” Actually Means
The name gives it away: A1B stands for “approximately 1B active parameters.” LFM2.5-8B-A1B is a Mixture-of-Experts (MoE) model with 24 layers — 18 gated convolution blocks and 6 Group Query Attention layers. At inference time, a router decides which expert sub-networks to activate for each token. Most tokens trigger only a subset of the model’s total capacity.
The tradeoff people immediately raise is valid: you still need to store all 8.3B parameters in memory. The counterargument is that 8.3B quantized to Q4 comes in around 5-6GB — which fits on a modern MacBook Pro, an AMD Ryzen AI laptop, and high-end Android devices. The compute cost stays at 1.5B-scale. That is the battery and latency story that makes on-device deployment viable.
The Benchmarks That Actually Changed
Comparing LFM2.5-8B-A1B to its predecessor LFM2-8B-A1B makes the engineering progress clear:
- Non-hallucination rate: 7.46% → 63.47% — the model went from barely reliable to genuinely trustworthy on knowledge-bounded queries
- MATH500: 74.80 → 88.76 — real reasoning improvement, not just instruction-tuning noise
- IFEval (instruction following): 79.44 → 91.84
- Tau² Telecom (agentic workflows): 13.60 → 88.07 — the most dramatic jump, and the most relevant for developers building agents
Training data scaled from 12 trillion to 38 trillion tokens. Context window went from 32K to 128K. Those are not incremental tweaks — the team rebuilt the model at scale and the numbers show it.
The hallucination improvement comes from a targeted RL stage using avg@k-based rewards that teach the model to abstain on out-of-knowledge queries rather than confabulate. It does not solve hallucination entirely, but it makes the failure mode far less dangerous in production.
Running It: Frameworks and Code
LFM2.5-8B-A1B ships with day-one support for llama.cpp (GGUF format), MLX for Apple Silicon, vLLM and SGLang for GPU serving, and ONNX for cross-platform deployment. The Hugging Face model page has all checkpoints. The transformers path is the simplest starting point:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"LiquidAI/LFM2.5-8B-A1B",
device_map="auto",
dtype="bfloat16",
)
tokenizer = AutoTokenizer.from_pretrained("LiquidAI/LFM2.5-8B-A1B")
input_ids = tokenizer.apply_chat_template(
[{"role": "user", "content": "Summarize this document: ..."}],
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
output = model.generate(
input_ids,
temperature=0.3,
min_p=0.15,
repetition_penalty=1.05,
max_new_tokens=512,
)One generation parameter worth noting: temperature=0.3 is lower than you might set for other models. LFM2.5-8B-A1B is a reasoning-focused model that generates chain-of-thought before its final answer. Lower temperature keeps the reasoning trace coherent rather than wandering.
Where It Fits (and Where It Doesn’t)
This model works well for agentic tasks, RAG pipelines, data extraction, multi-turn conversation, and narrow vertical fine-tuning. The 128K context window at this size class is genuinely uncommon — most comparable on-device models cap at 32K or less. Liquid AI’s open-source LocalCowork demo runs 67 tools across 13 MCP servers entirely offline, showing what a capable on-device agent can look like today.
Where it falls short: heavy code generation and knowledge-intensive QA without retrieval augmentation. It is text-only — no vision or audio. The chain-of-thought output adds tokens to every response, which affects latency at low concurrency. If your primary use case is coding assistance, Phi-4 Mini or Qwen2.5 Coder remain better options.
In the broader on-device field: LFM2.5-8B-A1B beats Qwen3-1.7B on most benchmarks despite similar active parameter counts. It competes with Gemma-4-E2B on instruction following while offering significantly more context. Against Phi-4 Mini, the tradeoff is context and agent capability versus raw coding speed. The full LFM2 technical report has the architecture details for anyone who wants to go deeper.
Why MoE Is Finally Working at the Edge
Over 60% of frontier model releases since early 2025 use MoE architectures. The technique has proven itself at cloud scale — Deepseek, Mixtral, Qwen3, Gemma 4 all use it. The open question has been whether MoE translates to the edge, where memory and compute constraints are real.
The historical blocker: models like Mixtral-8x7B required roughly 46GB of storage for what amounts to 14GB of compute work per inference. The storage-to-compute mismatch made edge deployment impractical. LFM2.5-8B-A1B sidesteps this because its total footprint is small enough — 5-6GB quantized — to fit in consumer device memory. When the whole model fits in RAM, you stop paying the MoE storage tax.
The multilingual gains are a secondary story worth noting: the doubled vocabulary brings significant tokenization efficiency improvements for non-Latin scripts — Hindi at +120%, Thai at +238%, Vietnamese at +118%. Fewer tokens per sentence means faster inference and lower cost at the same output quality. That matters for anyone building global applications.
On-device AI agents capable of handling real workflows without a cloud call are not a 2028 problem. They are a 2026 problem. Models like LFM2.5-8B-A1B are the reason that timeline keeps moving forward.












