
GPT-5.6 Sol is government-restricted to roughly 20 organizations. Fable 5 got yanked globally with three days’ notice. If your production stack sends 100% of its AI traffic to a single frontier model, you’ve been watching these stories with a kind of personal dread. Model routing fixes the problem — and cuts your bill by 40-70% at the same time. In 2026, this is not an optimization you get around to eventually. It’s infrastructure.
The Problem with One Model
Most developers start by routing everything to the best model they can access. Pick GPT-5.5 or Claude Sonnet 4.6, wrap it in an API call, ship it. The problem surfaces at scale. GPT-5.5 output tokens cost $30 per million. DeepSeek V4 Pro costs $0.87 per million. That’s a 34x price gap. When you’re running summarization, classification, and extraction through a $30/M model, you’re not paying for quality — you’re paying for a sledgehammer to drive in thumb tacks.
The deeper problem is vendor dependency. The Fable 5 suspension and the GPT-5.6 government-gated rollout proved that frontier model access is not a utility. It can be cut off, restricted, or export-controlled with no warning. A single-provider stack is a single point of failure.
The Core Pattern: Default Handler + Escalation
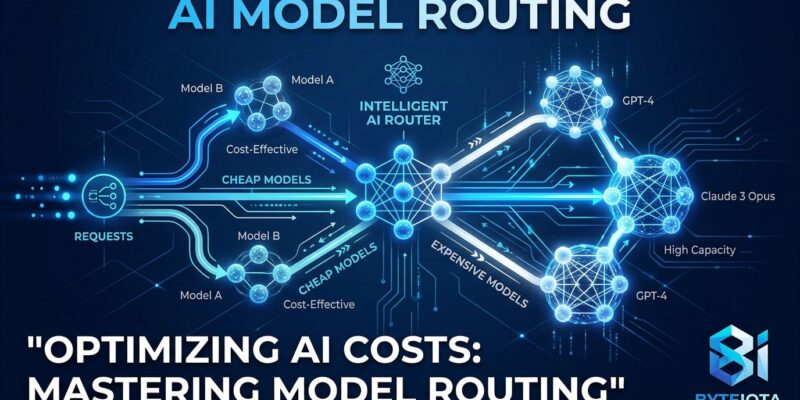
Model routing works by splitting your workload into two categories. Most tasks — summarization, classification, structured extraction, formatting, simple Q&A — don’t require frontier intelligence. They go to a cheap, capable default model. A smaller fraction of tasks — multi-step reasoning, complex code generation, nuanced judgment calls — escalate to a frontier model only when needed.
The research backs this up. The RouteLLM framework from Berkeley, Anyscale, and Canva (ICLR 2025) found that a trained router sent only 14% of queries to the strong model on MT Bench while retaining 95% of GPT-4 quality — an 85% cost reduction. That’s a peer-reviewed benchmark, not a vendor estimate.
Three Strategies, One Starting Point
There are three main routing approaches, ranked by implementation complexity. Start with the simplest one.
Rule-based routing is deterministic: you define which task types go where. Summarization, classification, extraction, translation, and formatting go to the cheap model. Multi-step reasoning, code generation, and math go to frontier. No ML required. Implement this in a day and it will immediately cut costs.
Cascading sends each query to the cheap model first. If the output confidence falls below a threshold — or if multiple outputs disagree — the query escalates. It produces better results than pure rule-based routing, but adds latency on escalation because you’re making two model calls. Add this once you have response quality data.
Complexity classifiers use a lightweight model (typically BERT-class) to predict which tier each query needs before it hits any LLM. The RouteLLM BERT classifier runs in under 10 milliseconds with no LLM inference required. Build this only after you have 500+ real queries with quality labels.
The 2026 Model Stack
For the default handler, DeepSeek V4 Pro is the obvious call for most workloads. At $0.435/M input and $0.870/M output (the permanent pricing since May 2026), it posts frontier-competitive agentic benchmark scores at a fraction of the cost. It supports a 1M token context window and is available as open weights for self-hosting.
The important hedge is GLM-5.2. Released June 13, 2026 under the MIT license, it’s available on OpenRouter at $1.00/M input, $4.00/M output. The MIT license cannot be affected by government export orders. Running DeepSeek as primary with GLM-5.2 as a geographic or policy fallback gives you a defense against exactly the kind of disruption that hit Fable 5 and GPT-5.6 Sol.
For the escalation tier, Claude Sonnet 4.6 ($3/M input, $15/M output) is the best default. Strong instruction following, 1M context window, reliable output structure. Use GPT-5.5 ($5/M input, $30/M output) if you have specific workloads where it outperforms on your benchmarks.
Implementation in 10 Lines
The fastest path to production is LiteLLM, which provides a single OpenAI-compatible API across 100+ providers with built-in fallback logic.
from litellm import completion
def route_and_complete(task_type: str, messages: list) -> str:
cheap_tasks = {"summarize", "classify", "extract", "format", "translate"}
if task_type in cheap_tasks:
model = "deepseek/deepseek-v4-pro"
else:
model = "anthropic/claude-sonnet-4-6"
response = completion(model=model, messages=messages)
return response.choices[0].message.contentIf you prefer zero infrastructure, OpenRouter gives you access to 300+ models with no setup. For teams that need compliance guardrails — PII redaction, jailbreak detection — Portkey open-sourced its gateway in March 2026 under Apache 2.0.
The Metric That Actually Matters
Most developers track cost reduction. The number that tells you whether routing is actually working is the escalation rate — what percentage of requests bubble up to the frontier tier.
For a well-structured production app, that number should be under 20%. If it’s above 30%, your task classification is off or your prompts are too ambiguous for the cheap model to handle. Track escalation rate per task type. You’ll find specific categories leaking unnecessarily to the expensive tier — that’s where the next optimization lives.
Before committing to an architecture, run an LLM-as-judge quality check on a sample of outputs from each tier. Confirm that quality on cheap-routed tasks is within acceptable tolerance — don’t assume it based on benchmark numbers alone.
The Math
A team spending $10,000/month on GPT-5.5 that routes 70% of traffic to DeepSeek V4 Pro drops to roughly $3,200 per month. That’s a 68% reduction with no change to output quality on structured tasks. Add GLM-5.2 as a fallback and you’ve also hedged against the next government-ordered disruption.
Start with rule-based routing. Pick your cheap model default. Deploy it. Once you’ve collected 500+ real queries with quality signals, build a classifier. The research is clear, the tooling is mature, and the cost gap is too large to ignore.













