Everyone spent 2025 learning to build AI agents. The problem that arrived with 2026: nobody knew how to debug them when they broke. Agents don’t crash cleanly. They loop. They pick wrong tools. They make confident, completely wrong decisions — and your dashboards show green because latency and error rate look fine.
On May 12, Honeycomb launched three features specifically for this moment: Agent Timeline, Canvas Agent, and Canvas Skills. Together, they represent the first serious attempt from a production observability platform to treat AI agents as a fundamentally different kind of system — not a service with LLM calls bolted on, but a non-deterministic, multi-step reasoning process that needs its own debugging primitives.
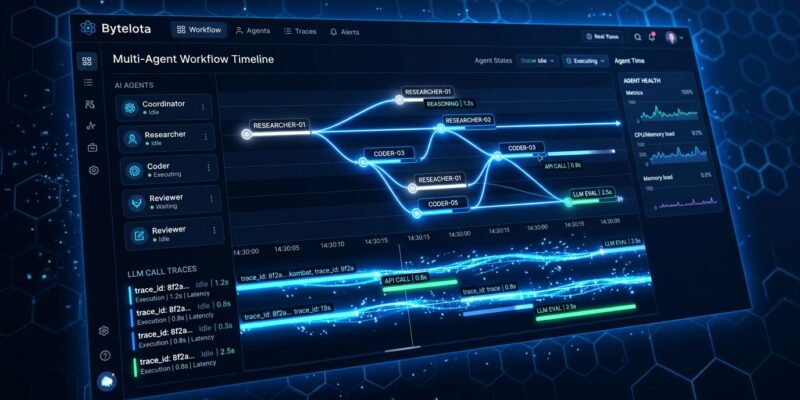
Agent Timeline: A Single View of What Your Agent Actually Did
The headline feature is Agent Timeline, currently in Early Access with general availability targeted for June 2026. The problem it solves is one that any engineer who has shipped an agent to production knows: when something goes wrong, figuring out what happened means piecing together logs across multiple traces manually. You see the wrong final output. You don’t see the decision three steps earlier that caused it.
Agent Timeline renders an entire multi-agent workflow as a single coherent view — every LLM call, tool invocation, agent handoff, and downstream system impact in chronological order. Click into any span and you see the full context: which model was called, what the prompt contained, how many tokens were consumed, what the tool returned, and how the agent decided to proceed. The decision path is reconstructable. Failures become legible.
This matters because of how agent failures actually propagate. A flawed retrieval in step two shapes reasoning in step five, which determines the wrong tool call in step eight. Traditional APM tools capture step eight as a latency spike or error count — they give you the symptom, not the cause. Agent Timeline gives you the cause.
Why Standard Observability Falls Short
Existing APM tools treat LLM calls like HTTP requests. They measure what they can measure: latency, token counts, error rates. That’s not wrong — those metrics are useful. But they miss the class of failures that make AI agents genuinely hard to operate in production.
When an agent fails, it rarely throws an exception. It enters a loop. It retrieves the wrong context and reasons confidently from it. It selects a tool that’s technically valid but semantically wrong for the situation. These failures surface as degraded output quality, unexpected cost, or subtly incorrect decisions — signals that don’t show up in any existing alerting rule.
The tools built for pure LLM tracing — LangSmith, Langfuse, Arize — go deeper on LLM-specific signals but lack full-stack context. Datadog’s LLM observability module is useful for cost and latency tracking but doesn’t have an agent-native timeline view. Honeycomb is trying to bridge the gap: general-purpose observability that now understands agent semantics.
Canvas Agent and Skills: Autonomous Investigation
Alongside Agent Timeline, Honeycomb rebuilt Canvas as a three-in-one workspace: collaborative investigation environment, plain-English chat interface, and autonomous agent. The most immediately useful capability is auto-investigations: when an alert fires or an SLO starts burning, the Canvas agent begins investigating before an engineer is paged. It gathers data, forms hypotheses, tests them, and proposes remediation steps — often surfacing a root cause summary by the time a human looks at it.
Canvas Skills extend this further. Teams can encode their best engineers’ debugging knowledge — their mental models for diagnosing Kafka consumer lag, their playbooks for investigating service degradation — into reusable autonomous routines. The next time a related incident fires, Skills run those playbooks automatically. Institutional knowledge becomes infrastructure.
The OpenTelemetry Foundation
One detail worth noting for developers deciding whether to invest here: Honeycomb’s agent observability is built on OpenTelemetry’s GenAI semantic conventions, which exited experimental status in early 2026. The gen_ai.* attribute namespace covers LLM spans, agent steps, tool calls, MCP calls, and token usage. Standard OTel instrumentation works. No proprietary SDK, no vendor lock-in on the data format.
Datadog and New Relic are also adopting these conventions — it’s becoming the standard layer for AI system telemetry. The difference is that Honeycomb built Agent Timeline on top of it, which no other general-purpose observability platform has done yet.
The MCP Integration
Honeycomb also has a hosted MCP server (GA since March 2026) that integrates with Claude Code, Cursor, and the AWS DevOps Agent. The practical use case: your AI coding agent can query your production observability data in natural language while you are writing code. Ask Cursor to investigate a burning SLO, and it will. This closes a loop that’s been awkward to close manually — the gap between writing code and understanding how it behaves in production.
Worth the Attention
Honeycomb’s Agent Observability launch is the most complete response from a production observability platform to the actual challenges of running AI agents at scale. Agent Timeline is the part to watch — it directly addresses the root-cause problem that makes agent debugging painful. It’s Early Access now, GA in June.
If you’re shipping agents to production, the Honeycomb announcement post has the technical details. O11yCon runs May 20-21 in San Francisco — expect more from Honeycomb this week.