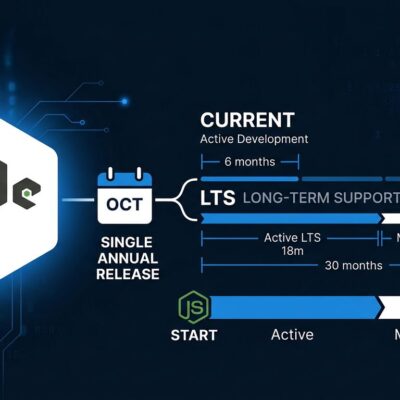
AWS Graviton5 is generally available. The fifth-generation Arm chip powering the new M9g and M9gd EC2 instances delivers 35% faster web applications, 35% faster ML inference, and 30% faster databases — at a lower hourly rate than equivalent x86 instances. If you’re still running Graviton4, an older Graviton generation, or x86, there is real performance and real money sitting uncollected. Here’s what changed under the hood and how to move.
The Numbers Behind the Headline
AWS claims 25% better overall compute compared to Graviton4, but the workload-specific numbers are what you actually care about:
- 35% faster for web applications
- 35% faster for machine learning inference
- 30% faster for databases
- 15% higher network bandwidth on average
- 20% higher EBS bandwidth on average
- 2x higher network bandwidth on the largest instance sizes
SAP reported 35–60% improvements on OLTP queries after moving to Graviton5. Atlassian saw a 30% Jira speedup with 20% lower latency. These are not cherry-picked synthetic benchmarks.
The three architectural changes driving those gains: 192 cores (double Graviton4’s count) with 33% lower inter-core latency; a 5x larger L3 cache (roughly 192MB vs. 38MB); and DDR5-8800 memory, the fastest DRAM in any cloud instance available today. The chip is built on TSMC’s 3nm process and runs at 3.3 GHz.
The Formally Verified Hypervisor
Most launch posts skip this part. Graviton5 ships with the Nitro Isolation Engine, which makes AWS the first cloud provider to formally verify its hypervisor. That phrase gets thrown around loosely, so here’s what it actually means.
AWS wrote 330,000 lines of machine-checked proofs in Isabelle/HOL (an interactive theorem prover) that mathematically demonstrate four properties: guest VMs cannot read or modify each other’s memory; AWS operators cannot access guest VM data; and the hypervisor contains no buffer overflows, null pointer dereferences, or out-of-bounds access violations.
This is not testing. Testing finds bugs that exist in the paths you test. Formal verification proves properties hold for all possible inputs and states. For teams running multi-tenant SaaS, healthcare data, or agentic AI workloads where one agent’s context must not bleed into another session, “we proved it” is a meaningfully different guarantee than “we tested it.”
Migration: Mostly a Terraform Variable
If you’re already on Graviton, the migration is a single line change:
instance_type = "m9g.xlarge" # previously: m7g.xlarge or m8g.xlargeGraviton processors are backward-compatible within the arm64 family. Python, Node.js, Java, Rust, and Go run unchanged. The increased L3 cache is transparent to running code.
The real risk is native compiled extensions. If your application bundles any C extensions, compiled binaries, or Docker images that were built for a specific architecture, you need to audit them. Run file /path/to/binary to inspect architecture. Most popular packages now ship arm64 builds, but any extension that does not will fail.
Coming from x86 (m5, m6i, m7i)? Same process, but with a more thorough binary audit. Docker images built for amd64 will refuse to run on arm64 unless you rebuild them. Use multi-arch builds:
docker buildx build --platform linux/arm64,linux/amd64 -t myapp:latest .AWS maintains a Graviton Getting Started guide on GitHub that documents compiler flags, instruction-set differences, and language-specific considerations for Python, Node.js, Java, .NET, Rust, PostgreSQL, and MySQL.
Who Should Prioritize This Now
ML inference teams get the largest absolute gain. Graviton5’s 5x L3 cache means inference batches spend less time waiting on memory fetches, and 192 cores let you run significantly more concurrent inference processes before hitting a CPU ceiling.
Web application servers running stateless request handlers are the easiest migration and see immediate 35% gains. An API server on m8g.xlarge upgrades to m9g.xlarge at roughly the same cost with meaningfully better throughput.
Agentic AI workloads are AWS’s stated priority target. Agent orchestration, tool call routing, and context management are CPU-bound in ways GPU-heavy inference pipelines are not. Meta has committed to deploying tens of millions of Graviton5 cores for its agentic AI infrastructure. Uber and Snowflake are also running Graviton for agent workloads.
Storage-intensive workloads should look at the M9gd variant. It offers up to 11.4 TB of NVMe SSD local storage with 30% higher IOPS than the previous generation — relevant for Kafka brokers, log aggregators, or on-instance database caches where EBS latency is a bottleneck.
The Cost Case
Graviton instances run roughly 20% cheaper per hour than equivalent Intel x86 instances. Add a 25-35% performance advantage, and the price-performance gap versus x86 approaches 40%. For teams paying meaningful AWS bills, this is not a minor optimization — it’s the kind of change that shows up in quarterly financials.
M9g and M9gd instances are generally available now in major AWS regions. The upgrade path from any existing Graviton instance is a Terraform variable and a rolling restart.