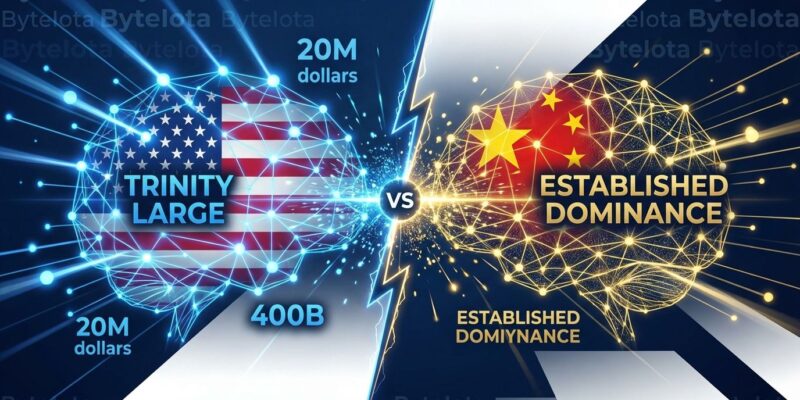
Arcee AI, a 39-person Miami startup, announced Trinity Large yesterday—a 400-billion parameter open-source model trained in 33 days for $20 million. This is the first competitive US open-source frontier model that matches Meta’s Llama 4 Maverick on benchmarks, directly challenging Chinese dominance in open AI. While Chinese models grew from 1.2% to 30% global market share in just one year, American labs struggled to keep pace. Trinity Large changes that equation.
US Strikes Back: The Open-Source AI Race
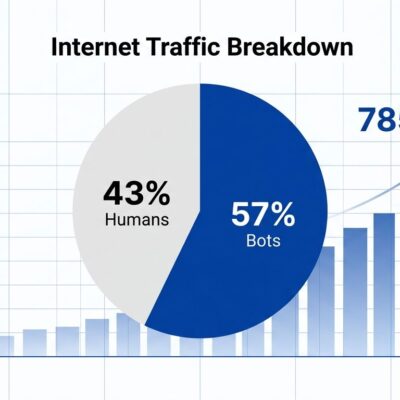
Chinese open-source AI models captured 30% of global usage by 2025, up from 1.2% in late 2024—a 25x surge in twelve months. Alibaba’s Qwen alone surpassed 700 million downloads on Hugging Face by January 2026, making it the world’s most-used open-source AI system. DeepSeek, Qwen, Moonshot AI’s Kimi, and Zhipu AI’s GLM—collectively dubbed the “Four Open-Source Masters”—dominate globally.
American companies including OpenAI, Google, Microsoft, and Nvidia all released open models in response. However, analysis from Stanford HAI warns that “none have been as good as the top Chinese models.” Trinity Large is the first to genuinely compete at frontier scale. For US enterprises worried about Chinese model dependencies, this isn’t just about bragging rights—it’s about AI sovereignty. Regulated industries and government contractors now have a domestic alternative that matches Chinese performance.
Related: DeepSeek MODEL1 Leak: 30% Memory Cut Challenges OpenAI
How Arcee Built a Frontier Model for $20M
Trinity Large uses sparse mixture-of-experts (MoE) architecture with 256 experts, activating only 4 per token. That’s 13 billion active parameters out of 400 billion total—a 1.56% utilization rate per token. Trained on 2,048 Nvidia B300 GPUs over 33 days using 17 trillion tokens, it achieves 2-3x faster inference than comparable models. Furthermore, Arcee introduced SMEBU (Soft-clamped Momentum Expert Bias Updates), a novel load balancing strategy that optimizes expert utilization during training.
The three-variant release strategy sets Trinity apart. Trinity Large Preview is chat-ready for immediate production use. Meanwhile, Trinity Large Base provides the full 17-trillion-token pretrained foundation model for fine-tuning. TrueBase—an early 10-trillion-token checkpoint without instruction tuning—gives researchers something rare: a genuine “true base” model to study foundational capabilities. Most labs only release instruction-tuned versions.
Performance benchmarks show Trinity Large Preview “roughly in line with Llama-4-Maverick’s Instruct model across standard academic benchmarks,” according to the official technical report. The base model “holds its own and in some cases slightly beats Llama on coding and math tests.” Meanwhile, 2-3x faster inference than DeepSeek-V3 translates directly to lower production costs for enterprises deploying at scale.
But Is This Real Progress?
Hacker News commenters are skeptical. “Training models which score much better seems to be hitting a brick wall,” one noted, questioning whether benchmark improvements reflect genuine capability gains. Consequently, critics point to Trinity’s extreme sparsity—only 4 of 256 experts active means the model is “undertrained and undersized in terms of active parameters” compared to competitors. With just 1.56% of experts firing per token, coverage gaps are inevitable.
The $20 million price tag raises questions too. As one HN commenter observed, “claimed costs obscure total expenditure”—the figure doesn’t include failed experiments or full R&D investment. Moreover, synthetic data comprises 47% of Trinity’s 17 trillion training tokens. While Gartner predicts synthetic data will reach 75% of AI training by 2026, quality concerns persist. Poorly designed synthetic datasets can distort real-world patterns or introduce biases.
This skepticism matters. Enterprises evaluating Trinity need to test it on real workloads, not trust benchmarks alone. Benchmark gaming is a documented problem—models can optimize for test scores without improving actual problem-solving. The community’s critical eye forces honest evaluation beyond marketing claims.
What This Means for Developers and Enterprises
Trinity Large is available now. OpenRouter offers free API access through February 2026. Hugging Face hosts all three variants for self-hosting. The Apache 2.0 license permits unrestricted commercial use. For developers, this means spinning up Trinity on OpenRouter takes minutes. For enterprises, it’s a US-trained alternative that addresses sovereignty requirements without sacrificing performance.
The 512k native context length enables applications like full codebase analysis, legal document review, and extended conversation memory. Researchers gain rare access to TrueBase—a foundation model checkpoint without instruction bias. Additionally, with 2-3x faster inference, production deployments cost less to run than comparable dense models.
DeepSeek’s next major model is rumored for February 2026, intensifying competition. Trinity Large proves US labs can match Chinese efficiency and performance. However, the race is far from over. Chinese models continue advancing, and Trinity’s smaller variants don’t match DeepSeek-R1’s benchmarks at similar scales. The question isn’t whether Trinity is competitive—it is. The question is whether US investment will sustain this momentum.
Key Takeaways
- Trinity Large is the first competitive US open-source frontier model, matching Meta’s Llama 4 Maverick and challenging Chinese AI dominance after a year of 25x market share growth
- Trained for $20M in 33 days using sparse MoE architecture (256 experts, 4 active per token), Trinity achieves 2-3x faster inference than comparable models like DeepSeek-V3
- Community skepticism about benchmark reliability, extreme sparsity trade-offs (only 1.56% expert utilization), and 47% synthetic training data demands real-world testing beyond test scores
- Available now on OpenRouter (free through February 2026) and Hugging Face with Apache 2.0 licensing, providing US enterprises a domestic alternative for AI sovereignty compliance
- The open-source AI race intensifies as DeepSeek’s next model looms for February 2026—Trinity proves US labs can compete, but sustained investment will determine whether they can lead