An 8-person engineering team just published something rare in January 2026: a migration story going the wrong direction. Instead of moving to Kubernetes like everyone else, they ditched it for Docker Compose — and saved 60 hours a week managing infrastructure. Their reasoning? Kubernetes solved problems they didn’t have.
The numbers tell the story. Six months of engineering time went into migrating to and managing Kubernetes. Deploy frequency dropped 60 percent. Infrastructure costs jumped 5x. Then they spent 12 hours over three days migrating back to Docker Compose, and everything worked on the first try. Fourteen months later, they’re serving 28,000 users on Docker Compose with zero regrets.
This isn’t an isolated case of incompetence. It’s a symptom of an industry-wide problem: resume-driven development pushing teams toward complexity they don’t need.
The Resume-Driven Development Tax
Most teams adopt Kubernetes for prestige, not necessity. It looks impressive on resumes. It follows industry trends. It signals sophistication. But it rarely solves the actual problems small and mid-sized teams face.
Resume-driven development is the practice of choosing technologies to enhance your CV rather than solve business problems. It’s pervasive in DevOps. Teams adopt Kubernetes, microservices, and service meshes because that’s what Netflix and Google use — ignoring the fact that they don’t have Netflix’s problems.
The engineering team’s retrospective is brutally honest: “We’d built a dependency on one person’s specialized knowledge. And that knowledge had nothing to do with our actual product.” This is the hidden cost of adopting complex tools without genuine need. That specialized Kubernetes knowledge doesn’t help you ship features, acquire customers, or fix bugs. It just keeps your infrastructure from collapsing.
A Civo survey found that 54 percent of cloud developers say Kubernetes complexity slows down their organization. That’s not a minority struggling to keep up — it’s the majority being held back by tools that are supposed to help them.
The YAML Debt Nobody Talks About
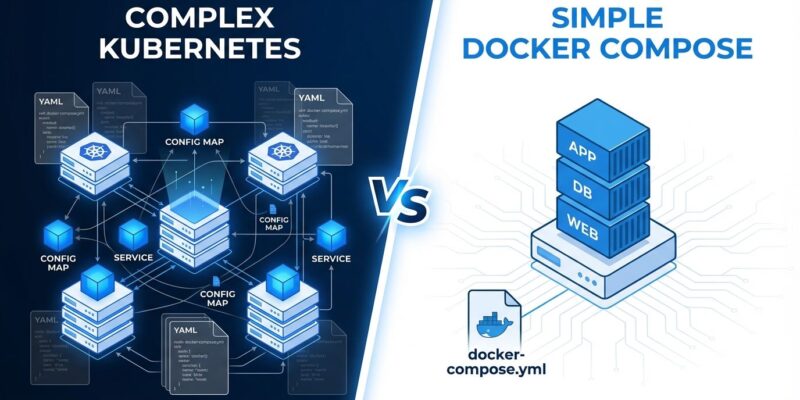
Kubernetes complexity manifests as what engineers call “YAML debt” — hundreds of lines of error-prone configuration files that require constant maintenance and debugging. Simple applications balloon into configuration nightmares.
A basic Kubernetes deployment requires YAML files for pods, services, deployments, ingress controllers, config maps, and secrets. Mixing spaces and tabs breaks things. Misplacing a single indent causes cryptic failures. Managing environment-specific configs across dev, test, staging, and production becomes a full-time job.
Then there’s configuration drift — the difference between your defined infrastructure state and the actual runtime state. Manual changes override infrastructure-as-code. Helm chart versions get out of sync. Container images don’t roll out completely. Debugging distributed systems is already hard. Add layers of YAML abstractions and it becomes nearly impossible.
The operational tax is measurable: days spent tweaking manifests instead of shipping features. The team that migrated back to Docker Compose called it perfectly: “Every piece of complexity in your stack is a tax you pay every time you deploy, debug, and onboard a new engineer.”
Docker Compose at 28,000 Users: The Reality Check
The migrated team started with 18,000 users on Docker Compose. Conventional wisdom says they’d hit scaling walls and be forced back to Kubernetes. Instead, they’re now at 28,000 users, still running Docker Compose, and it’s still working fine.
This challenges a core assumption in the industry: that Kubernetes becomes mandatory at certain scale thresholds. The reality is more nuanced. Most applications can serve millions of requests per month on a single well-configured server. Vertical scaling — adding more CPU and RAM to one machine — is sufficient for the vast majority of use cases.
Docker Compose’s simplicity is its superpower. The entire team understands it. There’s no specialized knowledge bottleneck. Deployments work consistently across all environments. As the team put it: “Everyone on the team understands it. And ‘everyone understands it’ is worth more than any fancy feature.”
Hacker News commenters debated the story, with some arguing Docker Compose is viable even for 100,000 users. The point isn’t that Docker Compose scales infinitely — it doesn’t. The point is that Kubernetes is overkill for far more systems than the industry admits.
When Kubernetes Actually Makes Sense
Kubernetes isn’t always wrong. However, it solves specific problems that most teams don’t have.
You genuinely need Kubernetes if you’re managing thousands of containers across distributed hosts. If you need true auto-scaling based on traffic patterns. If multi-region deployments with complex failover are critical to your business. If zero-downtime deployments are non-negotiable. If you have a dedicated DevOps team with Kubernetes expertise.
Docker Compose is enough if you’re running on a single host or just a few. If your team is under 50 engineers. If you can tolerate brief deployment downtime (most users won’t notice 30 seconds). If your traffic is under 100,000 users as a starting threshold. If nobody on your team has specialized Kubernetes knowledge.
The migrated team’s philosophy should be the default: “We won’t adopt complexity until we hit actual problems that require it — not theoretical ones.” That’s the more senior engineering choice, even though it sounds less sophisticated on paper.
Choose Tools for Problems, Not Resumes
The Kubernetes-for-everything trend is part of a broader pattern of over-engineering in DevOps. Consequently, teams adopt microservices when monoliths work. Service meshes when simple networking suffices. Complex CI/CD pipelines when shell scripts would do.
Industry hype cycles push solutions before problems exist. FOMO drives adoption. Complexity compounds. Moreover, teams end up with infrastructure more complex than their actual business, spending more time maintaining their deployment pipeline than building products customers want.
There’s a counter-trend emerging. Some teams are migrating back from microservices to monoliths. Others are embracing “boring technology” — SQLite, Docker Compose, simple stacks that solve real problems without operational overhead.
Choosing simpler tools isn’t a failure of ambition. Furthermore, it’s often the more pragmatic and experienced engineering choice. The goal isn’t to use the most impressive technology. It’s to ship valuable software efficiently.
The hard lesson: Most companies adopted Kubernetes to solve problems they don’t have. Docker Compose is good enough for 90 percent of systems. The industry over-indexed on Google-scale infrastructure when most teams just need to acquire customers and stay alive.
Choose tools for your actual problems, not your ideal resume.
Key Takeaways
- Engineering team saved 60 hours/week by migrating FROM Kubernetes TO Docker Compose in January 2026
- Resume-driven development drives Kubernetes adoption more than genuine technical need
- YAML debt and configuration drift create measurable operational taxes on teams
- Docker Compose successfully serves 28,000+ users, challenging scale assumptions
- Kubernetes makes sense for thousands of containers, multi-region needs, true auto-scaling requirements
- Choose complexity only when solving actual problems, not theoretical ones