
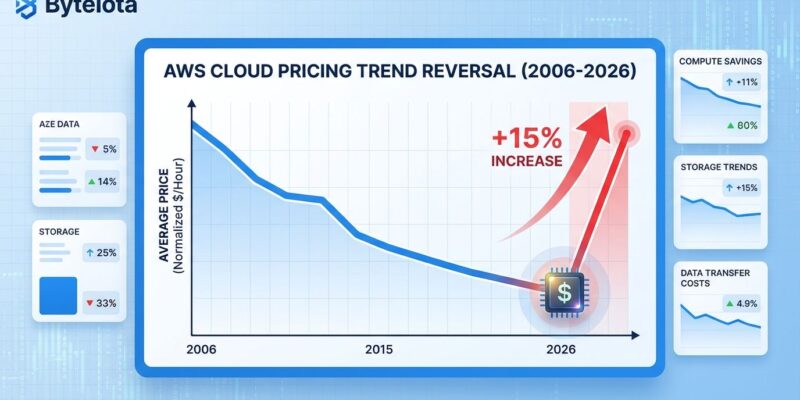
On January 4, 2026, AWS raised EC2 Capacity Block prices for ML workloads by 15% over a weekend without advance customer notification—the first time in AWS’s 20-year history the company has increased prices instead of lowering them. The p5e.48xlarge instance (eight NVIDIA H200 GPUs) jumped from $34.61 to $39.80 per hour across most regions, with the next pricing review scheduled for April 2026. For two decades, AWS conditioned customers to expect continuously declining prices, justifying cloud migration costs and vendor lock-in with the promise that operational costs would decrease over time. That foundational assumption just broke.
As cloud cost expert Corey Quinn put it: “AWS has spent two decades conditioning customers to expect prices only ever go down. That expectation is now broken. The precedent is set. That’s the part that matters. Once the door is open, it doesn’t close.”
GPU Shortage and Infrastructure Cost Crisis Driving Cloud Price Increases
AWS’s price hike is a symptom of a broader infrastructure cost crisis unfolding across the cloud industry. NVIDIA H200 GPU shortages are acute—Chinese tech giants alone ordered 2 million units against available stock of just 700,000. TSMC is prioritizing production of newer Blackwell and Rubin architectures over H200, severely limiting output capacity. Demand for H200 units outstrips supply by roughly 3:1.
Memory costs are compounding the problem. DRAM prices surged 158% for DDR4 and 307% for DDR5 since September 2025, according to memory analyst firm TrendForce. The driver? Manufacturers prioritized HBM (High Bandwidth Memory) production for AI accelerators over conventional server memory, creating a supply squeeze for standard infrastructure.
Energy costs aren’t helping. Data center power expenses account for 40-60% of operational budgets—roughly $7.4 million annually for large-scale operations. In the PJM power market (stretching from Illinois to North Carolina), pricing spiked from $34 per megawatt-day in 2023 to $329 in 2026—an 868% increase. Extra demand from new data centers added $9.3 billion to capacity costs for 2025-2026 alone, according to Bloomberg.
These cost drivers are structural and industry-wide. All cloud providers—AWS, Google Cloud, Azure—buy from the same OEMs (TSMC, NVIDIA, memory manufacturers) and face identical pressures. If you think this is AWS-specific, you’re not paying attention.
Related: DRAM Shortage 2026: 70% Price Surge, No Relief Until 2028
OVH Forecast: 5-10% Increases Across All Providers by Mid-2026
OVH Cloud is the only provider being transparent about what’s ahead. CEO Octave Klaba publicly forecast 5-10% price increases taking effect between April and September 2026, driven by hardware cost inflation of 15-25% for servers (due to RAM and NVMe drive price increases from AI hardware demand). AWS, Azure, and Google Cloud haven’t announced anything yet, but they’re buying from the same OEMs facing identical cost pressures.
AWS moved first because EC2 Capacity Blocks pricing is most flexible—dynamic rates with quarterly reviews. On-Demand and Savings Plans pricing likely follows in Q2-Q3 2026 once the precedent is normalized. Google Cloud and Azure will implement similar increases to protect margins. They have no choice given shared cost drivers.
Memory-intensive services face steeper increases than general compute due to higher DRAM ratios. Enterprises should budget for 10-15% cloud cost increases in 2026-2027, not assume static pricing.
FinOps Adoption Hits 75% as Cost Control Becomes Critical
FinOps automation will become standard practice for 75% of enterprises by 2026 (up from 46% growth in 2025), driven by the recognition that cloud waste—28-35% of total spend—is no longer acceptable. Organizations implementing structured FinOps programs achieve 25-30% cost reductions, with top performers realizing 10-20x ROI. Capital One saved over $100 million. McDonald’s cut $20 million. These aren’t marketing case studies—they’re documented results driving adoption.
The math shifted when cloud providers started raising prices. For 20 years, enterprises could tolerate waste because baseline costs declined annually. That buffer disappeared. When AWS can raise prices 15% on a Saturday, FinOps shifts from cost optimization to business continuity. Continuous monitoring isn’t a nice-to-have—it’s insurance against pricing volatility.
Cloud waste follows predictable patterns: idle resources (10-15% of monthly invoices), over-provisioned compute (10-12% waste), and orphaned storage artifacts (3-6% avoidable spend). FinOps automation tools like ProsperOps and IBM Turbonomic handle the grunt work—tracking commitments, optimizing rates, right-sizing compute—freeing engineering teams to focus on architecture-level efficiency.
Related: FinOps Automation ROI: 75% Adoption, 10-20x Returns
The “cloud saves money” assumption is being challenged. With prices now increasing instead of decreasing, the case for cloud migration needs revalidation workload by workload. FinOps provides the data to make those decisions rationally rather than emotionally.
Cloud Repatriation and Multi-Cloud as Risk Mitigation
Cloud repatriation is accelerating through 2026, with 83% of enterprise CIOs planning to repatriate at least some workloads from public cloud to on-premises or private clouds (IDC). This isn’t wholesale cloud abandonment—only 8% are considering full exit. It’s strategic sophistication. Enterprises are optimizing workload placement based on economics and operational requirements.
The math is compelling for predictable, high-utilization AI workloads. Buying eight H200 GPUs costs $240,000-$320,000 upfront. Amortized over three years, that’s $15-20 per hour. AWS charges $39.80 per hour post-hike—roughly 2x more expensive for continuous use. But for variable demand, cloud remains optimal. You can’t buy half a GPU cluster for two weeks.
Hybrid architectures are emerging as the default: run predictable baselines on-prem where costs amortize favorably, burst to cloud for peaks and experimentation. Multi-cloud strategies provide cost arbitrage opportunities—benchmark AWS vs GCP vs Azure weekly and shift workloads based on pricing. Kubernetes makes this viable if you design for portability upfront.
Single-provider lock-in now carries pricing risk. Enterprise Discount Programs don’t protect you—percentage discounts stay fixed while absolute costs rise. If your GPU spend was $100,000 per month with a 15% discount ($85,000), it’s now $115,000 with the same discount ($97,750). You’re still paying $12,750 more monthly.
What Enterprises Should Do
The strategic response has four components. First, implement FinOps automation now. Tools like ProsperOps and Turbonomic provide continuous cost monitoring and optimization, catching mid-quarter price changes before they crater budgets. Quarterly reviews miss surprises like AWS’s Saturday hike.
Second, lock in long-term Savings Plans before On-Demand prices rise in Q2-Q3 2026. Multi-year commitments carry execution risk, but they hedge against pricing volatility. The trade-off depends on your growth trajectory and workload predictability.
Third, design for multi-cloud portability using Kubernetes and containerization. This isn’t about running everywhere simultaneously—it’s about maintaining negotiating leverage. When you can switch providers with reasonable effort, you’re not captive to unilateral pricing decisions. Portability is insurance.
Fourth, revisit cloud vs on-prem TCO for AI workloads exceeding 70% utilization. For continuous, predictable training runs, owned hardware amortizes to 50-60% of cloud costs over three years. For bursty inference or experimentation, cloud remains superior. The future isn’t binary—it’s hybrid architectures where each workload runs where it delivers the most value.
Key Takeaways
- AWS broke its 20-year “prices only go down” precedent with a 15% GPU price hike on January 4, 2026—the first increase in company history, signaling a fundamental shift in cloud economics as infrastructure costs (GPU shortage, DRAM surge, energy spike) compress margins industry-wide.
- OVH Cloud forecasts 5-10% price increases across all providers by mid-2026, driven by hardware cost inflation of 15-25%—AWS moved first due to flexible Capacity Blocks pricing, but Google Cloud and Azure face identical cost pressures and will follow to protect margins.
- FinOps adoption is hitting 75% of enterprises by 2026 as cloud waste (28-35% of spend) becomes unacceptable and pricing volatility demands continuous monitoring—organizations implementing structured programs achieve 25-30% cost reductions and 10-20x ROI.
- Cloud repatriation is accelerating strategically, with 83% of CIOs planning workload moves to optimize placement—on-prem costs 50-60% less for high-utilization AI workloads (>70% usage), while cloud remains optimal for variable demand and experimentation.
- Enterprises need four-part response: implement FinOps automation for real-time cost tracking, lock in Savings Plans before On-Demand prices rise, design for multi-cloud portability to avoid lock-in pricing power, and revisit cloud vs on-prem TCO workload by workload.
The precedent is set. Cloud prices can now rise, not just fall. Enterprises that adapt strategically—with FinOps automation, multi-cloud optionality, and hybrid architectures—will navigate the shift successfully. Those assuming the old pricing model continues risk budget shocks they can’t absorb mid-quarter.









[…] Read the source […]