OpenAI released GPT-5.2-Codex on December 19, 2025, calling it “the most advanced agentic coding model yet.” But here’s what actually matters: This isn’t another incremental benchmark bump. GPT-5.2-Codex introduces context compaction—a mechanism that lets the model work autonomously for 24+ hours on refactors, migrations, and feature builds without losing track. It scored 56.4% on SWE-Bench Pro, the highest recorded. The question isn’t whether this is impressive. It’s whether benchmarks translate to real-world value—and whether developers actually get faster, or just feel like they do.
Context Compaction: The Actual Innovation
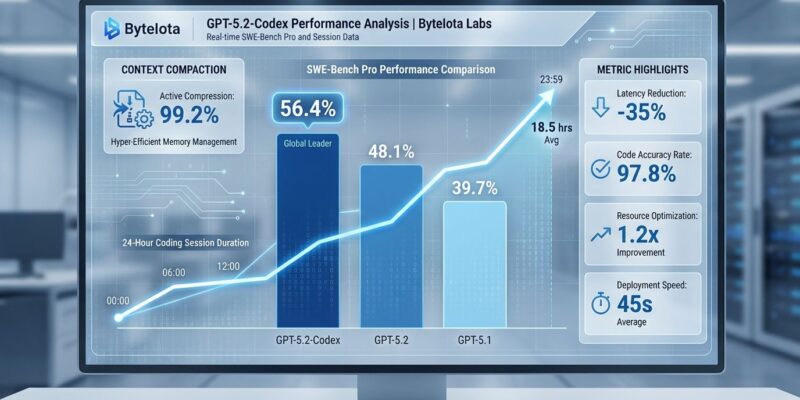
Forget the benchmark scores for a minute. The real story is context compaction. GPT-5.2-Codex is the first model natively trained to operate across multiple context windows through server-side compression that preserves task-relevant information while slashing token costs. When it approaches its context limit, it automatically compacts the session and keeps going.
This solves the fundamental problem with agentic coding: context loss. Previous models would forget what they were doing after a few hours or hit token limits mid-refactor. GPT-5.2-Codex can work for 24+ hours straight—handling data model refactors that touch dozens of files, code migrations that need every reference updated correctly, multi-day features with sustained task understanding. Rakuten reportedly ran a 7-hour autonomous refactoring session without human intervention.
That’s an engineering achievement. Context compaction isn’t marketing fluff. It addresses a real constraint.
56.4% on SWE-Bench Pro: So What?
Now the benchmarks. GPT-5.2-Codex scored 56.4% on SWE-Bench Pro, beating GPT-5.2 (55.6%) and GPT-5.1 (50.8%). On SWE-bench Verified—the real-world bug fixing benchmark—GPT-5.2 hit 80.0%, trailing Claude Opus 4.5’s 80.9% by less than a percentage point.
But here’s the problem with benchmarks: They optimize for benchmarks, not real workflows. A rigorous METR study released this year found that experienced open-source developers using AI tools took 19% longer to complete tasks than without AI. Before starting, those same developers predicted AI would save them 24% of their time. After finishing, they estimated it saved 20%. Reality? They got slower.
The perception-reality gap is massive. Industry stats claim 65% of developers use AI tools weekly and save 30-60% of their time. GitHub says Copilot users complete tasks 81% faster. But when you run a randomized controlled trial with experienced developers, they slow down. Benchmarks don’t capture that.
The Security Story Nobody’s Covering
Here’s what almost no one is talking about: GPT-5.2-Codex has “stronger cybersecurity capabilities than any model we’ve released,” according to OpenAI. It performs well on professional Capture-the-Flag challenges and can handle fuzzing, test environment setup, and attack surface analysis.
That same reasoning used to patch bugs can autonomously find exploits. OpenAI calls this “dual-use risk.” Internal safety evaluations flagged the rapid advancement of offensive capabilities. The model doesn’t reach “High” risk under OpenAI’s Preparedness Framework yet, but the gap is closing.
OpenAI’s mitigation: invite-only “trusted access” for vetted security professionals, gradual rollout with safeguards, and collaboration with the security community. The goal is defensive impact without enabling misuse.
But the fact remains: We’re building models that can autonomously discover vulnerabilities. That’s a bigger story than productivity gains—especially when those productivity gains might not exist.
From Code Producer to Creative Director
The industry frames this as role evolution: Developers are shifting from “code producers” to “creative directors of code,” orchestrating AI agents instead of writing implementations. Stack Overflow’s 2025 survey found 65% of developers use AI tools weekly. Eighty percent of new GitHub developers used Copilot in their first week. Forty-one percent of all code written in 2025 is AI-generated.
And employment? A Stanford study found software developer employment among 22-25 year olds dropped 20% between 2022 and 2025—exactly coinciding with AI coding tool adoption.
Is “orchestration” actually better than implementation? Or are we rebranding job destruction as career progression?
The Multi-Model Era
GitHub Copilot now offers both GPT-5.2 (generally available December 17) and Claude Opus 4.5 (generally available December 18). Developers are using both—Claude Opus 4.5 for architectural design and risk analysis, GPT-5.2-Codex for long-running implementation work. Cursor acquired Graphite for AI code review. Windsurf, Zed, and Aider are all competing for market share.
No single model wins. Developers bounce between tools when one gets stuck. The platform wars are heating up, and the integration battles matter more than benchmark leaderboards.
What This Actually Means
Context compaction is real innovation. It solves a genuine engineering problem and enables workflows that weren’t possible before. That part deserves credit.
But the productivity narrative is oversold. Rigorous studies show experienced developers getting slower, not faster. The benchmarks look great until you measure what actually happens in real development workflows.
And the security dual-use risks—autonomous vulnerability discovery—are underreported compared to the hype around coding speed. The employment impact is undeniable: 20% fewer junior developers in three years.
GPT-5.2-Codex is a technical achievement. Context compaction matters. But the gap between benchmark performance and real-world value is wider than OpenAI wants you to believe. And the consequences—security, employment, what “developer” even means—are bigger than the marketing pitch.