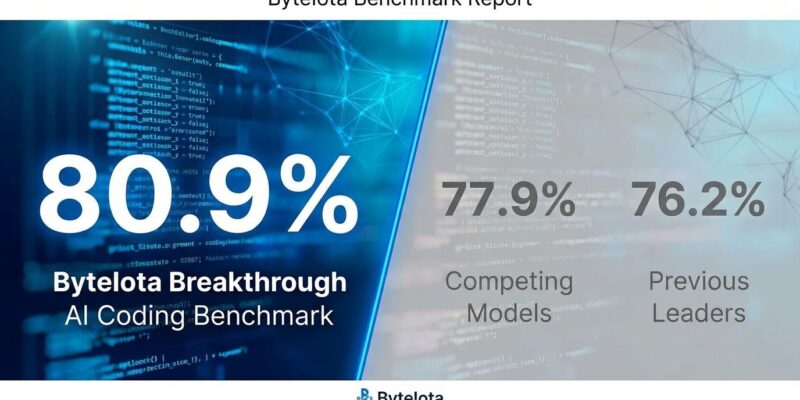
Anthropic’s Claude Opus 4.5 became the first AI model to break 80% on SWE-bench Verified, scoring 80.9% and outperforming GPT-5.1 (77.9%) and Gemini 3 Pro (76.2%). But here’s the real story: Anthropic slashed prices by 66% to $5/$25 per million tokens. The combination of best-in-class performance with dramatically lower costs might matter more than the benchmark itself.
What SWE-Bench Actually Measures
Before celebrating “human-level” coding, context matters. SWE-bench Verified tests AI models on 500 real GitHub issues from 12 Python repositories. Models receive a codebase and issue description, then generate a patch that must pass the repository’s tests without breaking anything.
The catch? About 90% of these tasks are fixes that experienced engineers complete in under an hour. SWE-bench tests whether AI can make simple codebase edits—navigating files, understanding function interactions, adhering to conventions. It doesn’t measure complex system design, architectural decisions, or the messy judgment calls that define senior engineering work.
So when Claude Opus 4.5 hits 80.9%, it’s genuinely impressive for routine bug fixes. But that 19.1% failure rate on one-hour tasks should temper any “developers are obsolete” hot takes.
The Economics Are the Real Breakthrough
Claude Opus models have always been powerful, but prohibitively expensive. Opus 4.1 cost $15/$75 per million tokens. Opus 4.5 drops that to $5/$25—a 66% reduction while simultaneously improving performance. Add prompt caching (90% savings) and batch processing (50% savings), and you’re looking at one of the best performance-per-dollar ratios in AI coding.
Windsurf’s CEO captured it well: “Opus models have always been SOTA but cost prohibitive. Claude Opus 4.5 is now at a price point where it can be your go-to model for most tasks.”
That’s the inflection point. When cutting-edge AI becomes economically viable for everyday use, adoption accelerates. Developers who couldn’t justify Opus 4.1’s cost for routine work can now deploy Opus 4.5 across their entire workflow.
Real-World Performance Beyond Benchmarks
Developer testing confirms the benchmarks translate to practice. Replit reported a 0% error rate on their internal code editing benchmark, down from 9% on Sonnet 4. Early testers described it as “the first model where I can vibe code an app end-to-end without getting into the details.”
The efficiency gains extend beyond the price cut. At medium effort mode, Opus 4.5 matches Sonnet 4.5’s performance while using 76% fewer tokens. That’s compounding cost savings—lower base price plus dramatically reduced token consumption.
But real-world use exposes limitations too. One technical review found that while Claude 4.5 “demonstrated the strongest architectural reasoning and long-horizon thinking,” outputs “usually required additional effort to integrate and stabilize.” It’s exceptional for strategy and design, less polished for production deployment.
The AI Coding Wars Heat Up
Claude Opus 4.5 dropped into an intense competitive window. GPT-5.1 launched November 12, Gemini 3 followed November 18, and Opus 4.5 arrived November 24. Each has distinct strengths beyond SWE-bench scores.
Gemini 3 Pro dominates algorithmic programming with a Grandmaster-tier Codeforces rating and leads on speed and cost for prototyping. GPT-5.1 Codex excels at multi-language consistency (88% on Aider Polyglot) and production reliability. Claude Opus 4.5 wins on real-world bug resolution and architectural reasoning.
There’s no single “best” model. The choice depends on whether you prioritize raw code quality (Claude), production dependability (GPT-5.1), or speed and multimodal capabilities (Gemini 3).
The timing aligns with AWS re:Invent’s focus on autonomous AI agents. CEO Matt Garman emphasized that “AI assistants are starting to give way to AI agents that can perform tasks and automate on your behalf.” AWS’s Kiro agent can write code autonomously for days. Claude Opus 4.5 fits this trajectory—Anthropic claims it handles “30+ hours of continuous multi-step work” in internal evaluations.
Augmentation, Not Replacement
So does 80% on SWE-bench mean AI replaces developers? The industry consensus is clear: transformation, not replacement. AI excels at boilerplate code, testing, debugging, and maintenance. Humans remain essential for architecture, innovation, strategic decisions, and the judgment calls that determine whether code should be written at all.
The job market reflects this. Employment for software developers is projected to grow 17.9% between 2023 and 2033. But McKinsey estimates 7.5 million development-related roles could be affected by automation. The reality? AI won’t replace you—but someone using AI might.
The 20% failure rate on SWE-bench’s simple tasks proves the point. If AI can’t reliably handle one-hour bug fixes without human oversight, it’s nowhere near replacing the full spectrum of software engineering work. Integration challenges, edge cases, and production stability still require experienced engineers.
What This Means Going Forward
Claude Opus 4.5’s 80% SWE-bench score is a milestone, but the economic shift is more consequential. When best-in-class AI coding becomes affordable for everyday use, it stops being a specialized tool and becomes infrastructure. Developers who learn to leverage these tools effectively will outpace those who don’t.
The competitive landscape suggests rapid iteration ahead. If models can improve from 76% to 80% in weeks while cutting costs by two-thirds, where does this trajectory lead? The answer determines whether we’re witnessing the early stages of autonomous coding agents or just better autocomplete.
For now, the smart play is augmentation. Use AI for what it handles well—boilerplate, simple fixes, rapid prototyping. Keep humans in the loop for architecture, integration, and anything where that 20% failure rate matters. And expect the 80% to climb.