LLMs forget everything between sessions. Your carefully crafted chatbot asks users the same questions repeatedly. Your AI assistant can’t remember project context from yesterday. This isn’t a bug—it’s how LLMs work. Every conversation starts from scratch, forcing developers into complex workarounds or expensive vector database subscriptions.
Memori, an open-source LLM memory engine that hit GitHub trending this week with explosive 263-star daily growth, solves this with genuinely simple architecture: one line of code. Released in version 2.3.3 on November 22, Memori intercepts LLM calls to inject relevant context from standard SQL databases developers already own. No proprietary vector stores, no vendor lock-in, no monthly SaaS bills.
Why LLM Memory is Broken
LLMs don’t “remember” anything in the traditional sense. They reread your entire conversation history from the beginning for every single response. The context window—that fixed-size buffer where conversations must fit—acts like a notepad you keep erasing to make room for new content.
This stateless architecture creates real problems. Multi-session applications need custom memory layers. Developers build elaborate context injection systems, pay for expensive vector databases, or accept that their agents will forget. Most production solutions are over-engineered because the baseline is fundamentally broken.
How Memori’s Memory Engine Works
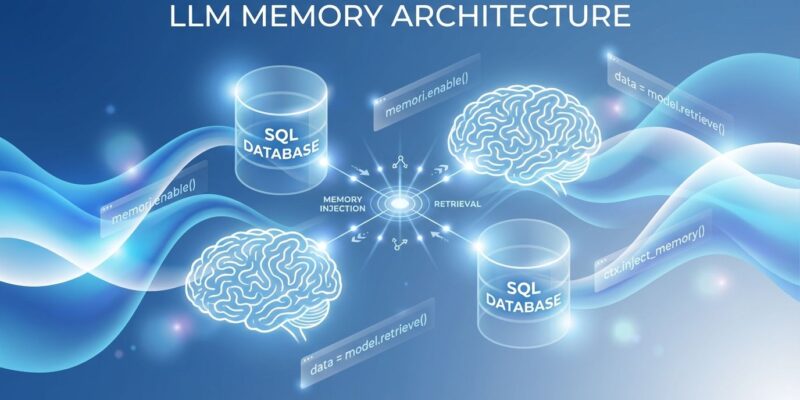
Memori runs a three-phase memory system that sits between your application and the LLM provider. The pre-call phase intercepts your request, queries a SQL database for relevant memories, and injects that context into your prompt. The post-call phase captures the LLM’s response, extracts entities and categorizes information (facts, preferences, skills, rules), then stores everything with full-text search indexing.
The real differentiator is the Conscious Agent—a background process that runs every six hours to analyze patterns and promote essential memories from long-term to short-term storage. This isn’t passive logging. It’s intelligent curation that decides what matters.
All of this happens in standard SQL databases: SQLite for development, PostgreSQL or MySQL for production. The architecture achieves 80-90% cost savings compared to vector database solutions while giving developers complete data ownership. Your memories export as portable SQLite files, not locked behind proprietary APIs.
Quick Start: Three Lines of Code
Install the SDK:
pip install memorisdkEnable memory for any LLM:
from memori import Memori
from openai import OpenAI
memori = Memori(conscious_ingest=True)
memori.enable()
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "I'm building a FastAPI project"}]
)That’s it. Now every LLM call automatically gains persistent memory. In a later session—different process, different day—the context persists:
# Later session (no manual context injection needed)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Help me add authentication"}]
)
# LLM automatically knows about the FastAPI projectThe system works with OpenAI, Anthropic, LangChain, and 100+ LLM providers through LiteLLM’s callback architecture. Switch providers without rewriting memory logic.
Production Configuration
For production deployments, swap SQLite for PostgreSQL and externalize configuration:
import os
from memori import Memori
memori = Memori(
database_connect=os.getenv("DATABASE_URL"),
conscious_ingest=True,
auto_ingest=True,
openai_api_key=os.getenv("OPENAI_API_KEY")
)
memori.enable()The conscious_ingest mode injects curated working memory once per session—predictable token usage. The auto_ingest mode dynamically retrieves memories per query—adaptive but higher token costs. Combined mode runs both for optimal flexibility.
When to Choose Memori Over Alternatives
The AI agent memory space has competing solutions with different philosophies. Mem0, backed by Y Combinator, offers a managed SaaS platform with 26% higher response accuracy and 91% lower latency than OpenAI’s built-in memory—but you’re paying for managed infrastructure and accepting vendor lock-in. Letta (formerly MemGPT) implements OS-style memory hierarchies with sophisticated RAM-to-disk patterns—powerful for research but complex to deploy. Zep delivers enterprise knowledge graphs with state-of-the-art benchmark results—ideal for organizations where memory infrastructure becomes a competitive moat.
Memori targets the developer who wants simplicity, cost control, and data ownership. If you’re prototyping an AI agent and need memory today without infrastructure complexity, Memori wins. If you’re building a SaaS product where per-user memory isolation matters and you want to avoid monthly vector database bills, Memori makes sense. If you need advanced graph relationships or managed enterprise services, look at Zep or Mem0.
The trade-off is straightforward: Memori sacrifices some sophistication (no knowledge graphs, six-hour background cycles) for extreme simplicity and cost efficiency. That’s the right trade for most applications.
Key Takeaways
Memory infrastructure is critical for AI agents, and most solutions over-engineer it. Memori proves that SQL databases—tools developers already understand—can handle LLM memory at a fraction of the cost and complexity of vector stores. The one-line enable pattern removes integration friction, while the Conscious Agent provides intelligent curation without manual memory management.
The project’s momentum (GitHub trending #6, 263 daily stars, version 2.3.3 released November 22) signals that developers are ready for simpler approaches. Production deployments work with PostgreSQL, multi-user isolation, and framework-agnostic design. Start with Memori when simplicity and ownership matter more than managed complexity.
Get started at the GitHub repository or install directly from PyPI.