
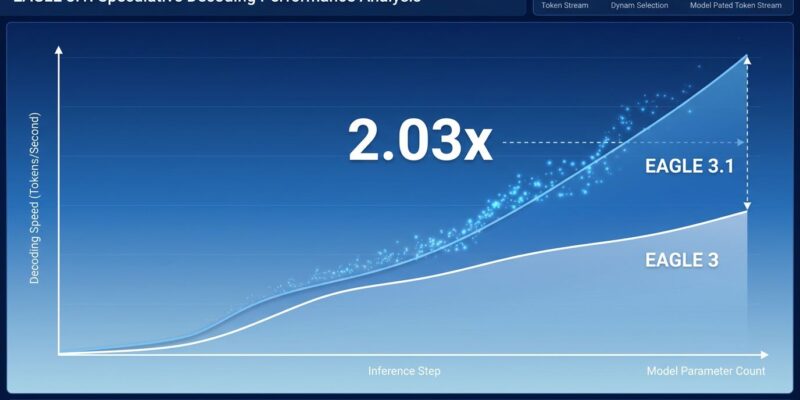
Today, the EAGLE Team, vLLM Team, and TorchSpec Team jointly released EAGLE 3.1 — the most significant upgrade to the leading speculative decoding algorithm in production LLM inference. The headline result: 2.03× throughput improvement at single-user concurrency, with gains holding at 1.66× even at sixteen concurrent users. More importantly, EAGLE 3.1 fixes the production reliability problem that made earlier versions a gamble in real-world deployments.
What Speculative Decoding Does (The Short Version)
Speculative decoding uses two models: a small, fast draft model that speculatively proposes the next N tokens, and the large target model that verifies all of them in a single parallel GPU pass. Because verification is parallel and generation is sequential, batching multiple draft tokens into one verification step cuts wall-clock time without changing the output. The result is mathematically identical to what the target model would have generated alone — just faster.
EAGLE is the dominant implementation of this technique in vLLM’s inference stack. Unlike simpler approaches, EAGLE extrapolates the target model’s own internal feature vectors to generate draft tokens, which produces higher acceptance rates and better real-world speedups. It’s been through three published versions (ICML’24, EMNLP’24, NeurIPS’25) before today’s 3.1 release.
EAGLE 3.1 and the Attention Drift Problem
EAGLE 3 looked strong in benchmarks. In production, it was less predictable. The culprit was a phenomenon the team calls attention drift: as speculative depth increases, the draft model’s attention gradually shifts away from the original input context and toward its own generated tokens. The longer the chain of speculation, the worse this instability gets.
Two underlying causes compound the problem. First, higher-layer hidden states increasingly dominate the drafter’s input, creating an imbalanced feature representation. Second, unnormalized residual connections allow hidden-state magnitude to grow unchecked across each speculation step. The effect cascades — the draft model becomes progressively unreliable the deeper it speculates.
This showed up as degraded performance with varied chat templates, long-context inputs, and out-of-distribution system prompts — exactly the conditions production deployments encounter. Lab benchmarks use clean, consistent inputs. Real workloads don’t. This gap burned teams that deployed EAGLE 3 expecting benchmark-level consistency.
Related: vLLM v0.21.0: Spec Decode for Reasoning Models — Upgrade Now
What Changed: FC Normalization and Post-Norm Feedback
EAGLE 3.1 introduces two targeted architectural fixes. The first is FC normalization — applied after each target hidden state and before the fully connected layer. This prevents magnitude from compounding across speculation steps by stabilizing the scale of inputs entering each computation. The second is post-norm hidden-state feedback: instead of passing raw hidden states into subsequent decoding steps, normalized states are used.
The combined effect is that the drafter now behaves “more like recursively invoking the drafter across decoding steps, rather than simply appending additional layers to the target model,” according to the EAGLE 3.1 release post. Attention drift is suppressed because normalization keeps each step’s input representation consistent regardless of depth.
The outcome in numbers: up to 2× longer acceptance length in long-context workloads. On Kimi K2.6 benchmarks using SPEED-Bench, EAGLE 3.1 delivered 2.03× throughput at single-user concurrency, 1.71× at four users, and 1.66× at sixteen. These are improvements over EAGLE 3, which was already 3–6× faster than vanilla autoregressive generation — so the compounded gain over no speculative decoding is substantial.
Deploying EAGLE 3.1 in vLLM
The upgrade path is a checkpoint swap. EAGLE 3.1 lands in vLLM as a config-driven extension with full backward compatibility for existing EAGLE 3 checkpoints — no code changes, no API changes. The team open-sourced an EAGLE 3.1 draft model for Kimi K2.6 alongside the announcement, trained using TorchSpec’s infrastructure. Deploy using the same --speculative-config pattern:
VLLM_USE_V1=1 vllm serve meta-llama/Llama-3.3-70B-Instruct \
--seed 42 -tp 4 \
--speculative-config '{"model": "yuhuili/EAGLE3-LLaMA3.3-Instruct-70B",
"num_speculative_tokens": 3, "method": "eagle3",
"draft_tensor_parallel_size": 1}'One practical note: speculative decoding gains compress at very high concurrency, where inference shifts from memory-bandwidth-bound to compute-bound. However, 1.66× at C=16 remains meaningful for teams running shared inference endpoints. The EAGLE GitHub repository has updated checkpoints, open-sourced training code via TorchSpec, and compatibility details for supported model families.
Key Takeaways
- EAGLE 3.1 fixes attention drift — the compounding instability that caused EAGLE 3 to underperform with varied chat templates, long contexts, and deep speculation in production environments
- Two architectural changes (FC normalization + post-norm hidden-state feedback) deliver 2× longer acceptance length in long-context workloads and 2.03× throughput at single-user concurrency
- The upgrade is a checkpoint swap: EAGLE 3.1 is backward compatible with EAGLE 3 in vLLM, no code changes required
- If you’re running vLLM with EAGLE 3 today, this upgrade is low-risk and likely worth the switch — the benchmarks show consistent gains across concurrency levels, not just ideal-condition numbers

