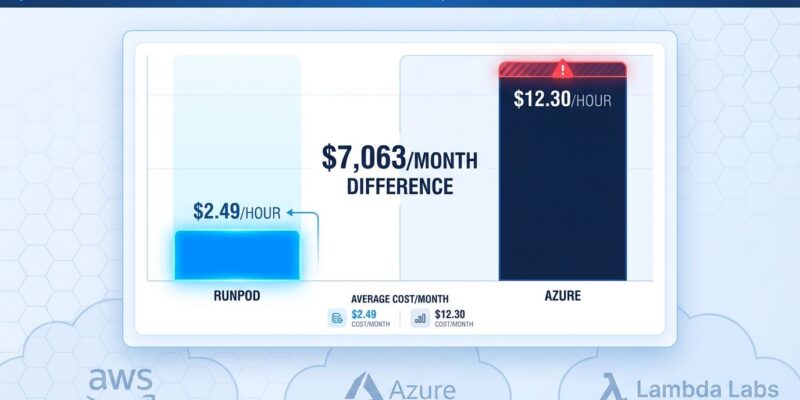
The same NVIDIA H100 GPU costs $2.49 per hour on RunPod but $12.30 per hour on Azure—a nearly 5X price difference that compounds to $7,063 per month for a single GPU running 24/7. Fresh March 2026 market data reveals a persistent 60-85% pricing gap between hyperscalers and specialized providers, yet most teams still default to AWS or Azure without understanding they’re massively overpaying for identical hardware.
With the GPU rental market reaching $7.38 billion in 2026, this isn’t academic. Developers and CTOs making infrastructure decisions today are either saving thousands monthly or throwing money away.
The GPU Pricing Collapse Nobody Talks About
H100 pricing crashed 64-75% from its Q4 2024 peak of $8-10 per hour to today’s stabilized range of $2.50-$3.50 per hour. The cause? Expiring long-term enterprise reservations are flooding the market with available capacity, erasing the panic-buyer premium that dominated 2024.
The $7.38 billion GPU rental market is normalizing faster than most realize. Specialized providers like Lambda Labs and RunPod offer H100s at $2.49/hour while Azure charges $12.30 and Google Cloud hits $10.60 for identical hardware. Even AWS, typically competitive on compute, lists on-demand H100s at $6.98 per hour—still 2.8X more expensive than Lambda Labs’ reserved pricing of $1.89/hour.
The monthly impact is brutal. A 10-GPU cluster on Azure costs $88,560 monthly at 24/7 utilization. The same setup on RunPod? $17,928. Consequently, that’s a $70,632 monthly difference, or $847,584 annually for hardware that performs identically.
Why Hyperscalers Cost 3-6X More
The pricing gap isn’t arbitrary—it reflects fundamentally different business models. Hyperscalers aren’t selling GPU compute; they’re selling ecosystem integration wrapped in compliance certifications. However, most teams pay for abstraction layers they don’t need.
The core economics are simple. GPU server costs break down to roughly 78% capital expenses (hardware depreciation at $7,025 monthly) versus 22% operating costs (power, cooling, space at $1,871 monthly). Therefore, third-party clouds succeed because hosting costs are dwarfed by capital costs—they can undercut hyperscalers significantly while maintaining healthy margins.
Then come the hidden fees. Hyperscalers charge $0.08-$0.12 per GB for data egress while six specialized providers—including RunPod, Lambda Labs, and Vast.ai—offer unlimited free egress. A typical training job that downloads 1TB of data and exports checkpoints regularly accumulates $50-$120 in egress fees on AWS. Export a 100GB model checkpoint? That’s $8-12 in egress charges on top of GPU hours. Industry analyses show these hidden costs add 20-40% to total bills—sometimes more.
Moreover, storage fees ($0.10-$0.30 per GB monthly), high-performance networking surcharges, and the infamous “ecosystem tax” of maintaining 100+ integrated services all compound. You’re paying for IAM complexity, compliance frameworks, and enterprise support whether you need them or not.
When The Premium Actually Makes Sense
Before you migrate everything to Lambda Labs, understand that hyperscalers aren’t universally wrong—just wrong for many use cases.
Use AWS, Azure, or GCP when your infrastructure is already committed to their ecosystem. If your data lives in S3, your orchestration runs on EKS, and your ML pipelines depend on SageMaker, the cross-cloud data transfer costs and authentication headaches can exceed GPU savings. Additionally, enterprises requiring HIPAA, FedRAMP, or SOC 2 compliance don’t have much choice—specialized providers rarely match hyperscaler certification depth.
Production workloads needing 99.99% SLAs, granular IAM policies, and guaranteed capacity also justify the premium. As DigitalOcean’s GPU provider guide notes, hyperscalers win on compliance, global presence, and enterprise-grade reliability. If downtime costs exceed savings, pay the premium.
However, for pure GPU compute—training jobs, batch inference, experimentation—specialized providers deliver identical performance at 50-70% cost reduction. One ML engineer documented 70%+ inference cost savings migrating from AWS to RunPod, with per-second billing eliminating the idle waste that hourly rounding creates.
The Hybrid Strategy Winning Teams Use
The smartest approach isn’t picking one provider and going all-in. Different workloads have different requirements.
Run compute-intensive training on Lambda Labs or CoreWeave where H100s cost $2.49/hour. Deploy inference workloads on RunPod Serverless with pay-per-second pricing that scales to zero. Furthermore, store your model registry in S3 for durability and access patterns. Serve production traffic from hyperscaler-managed services with reserved instances negotiated at volume discounts.
This hybrid model captures cost efficiency where it matters (training often represents 60-80% of compute spend) while maintaining operational simplicity for production serving. Training a 70B-parameter model costs $14.4 million on CUDO Compute versus $71 million on GCP—an 80% saving that dwarfs the operational overhead of managing multiple providers.
Market Outlook: Stabilization With Buyer Power
Prices are stabilizing in the $2.50-$3.50/hour range for H100s, with conflicting forces at play. Continued supply increases from expiring reservations push prices down. The upcoming B200 GPU release will make H100s commodity hardware, likely driving another 10-20% price reduction.
But memory costs (HBM, GDDR7) are rising, creating upward pricing pressure. Net effect: stable pricing through 2026 with potential sub-$2/hour rates by year-end. Meanwhile, specialized providers are gaining market share through aggressive pricing while hyperscalers maintain premium positioning through ecosystem lock-in.
For buyers, this stabilization phase offers leverage. Long-term contracts can be negotiated at favorable rates while supply exceeds immediate demand. Teams locked into expensive hyperscaler contracts should revisit terms—the market has shifted dramatically in your favor.
Key Takeaways
- H100 GPU pricing varies 5X across providers: $2.49/hr (specialized) vs $12.30/hr (Azure)
- Hidden costs (egress, storage, networking) add 20-40% to hyperscaler bills
- Use hyperscalers for compliance, SLAs, and ecosystem integration; use specialized providers for pure compute
- Hybrid strategy delivers optimal cost-performance: training on Lambda Labs, inference on RunPod, registry on S3
- Market stabilizing at $2.50-$3.50/hr with buyer power increasing through 2026
The decision framework is straightforward: if you need compliance certifications, enterprise SLAs, and deep ecosystem integration, hyperscaler premium is justified. If you’re optimizing for pure compute efficiency, specialized providers deliver identical hardware at 50-85% cost reduction.
Most teams fall somewhere in between, making a hybrid strategy optimal. But continuing to default to hyperscalers without evaluating alternatives is leaving $7,063 per GPU per month on the table—money that could fund additional compute, expand your team, or improve profitability.
The GPU rental market has normalized. Buyer power is shifting. The question is whether you’re using it.