2026 is the year enterprise AI gets real. After two years watching LLM costs spiral into “tens of millions per month,” companies like AT&T just proved the alternative works: switch to specialized Small Language Models and cut costs 90% without sacrificing accuracy. The shift is happening now, and it’s not subtle.
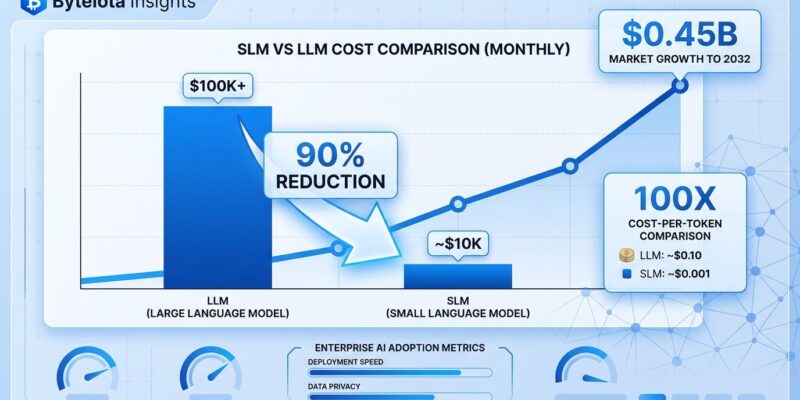
AT&T partnered with Mistral AI this month to deploy fine-tuned SLMs on-premise, achieving both the 90% cost reduction and a 70% latency improvement. Meanwhile, the broader SLM market is projected to grow from $0.93 billion in 2025 to $5.45 billion by 2032—a 28.7% CAGR that’s outpacing the overall LLM market. The message is clear: enterprises are done paying premium prices for general-purpose models when specialized ones deliver better results for less.
The Cost Crisis That Broke The LLM Spell
Frontier LLMs looked brilliant during proof-of-concept demos. Then enterprises tried scaling them to production workloads and discovered a hard truth: what costs $50K for a pilot balloons to millions monthly at scale. One enterprise AI leader put it bluntly: “What works perfectly fine for proof-of-concept projects becomes financially unsustainable when scaled across actual business operations.”
The economics are brutal. Ministral 8B, a small language model from Mistral AI, costs 100x less per token than frontier models like GPT-4 or Claude Opus. When you’re running agentic AI workflows—which involve continuous inference that can “send token costs spiraling,” according to Deloitte’s 2026 infrastructure report—that difference matters. A lot.
AT&T’s Chief Data Officer Andy Markus watched this play out firsthand. His team calculated the total cost of ownership for their AI workloads and realized they could fine-tune domain-specific SLMs for a fraction of what they were paying OpenAI and Anthropic. The result: 90% cost reduction. Not 10%. Not 50%. Ninety percent.
AT&T Proves Small Language Models Work at Fortune 50 Scale
When a telecommunications giant with AT&T’s infrastructure complexity bets on SLMs, the market pays attention. The company partnered with Mistral AI and deployed Ministral 8B and other fine-tuned models on-premise, keeping all data within their firewalls. This wasn’t just about cost—it was about control.
“Fine-tuned SLMs will be the big trend and become a staple used by mature AI enterprises in 2026,” Markus told TechCrunch in early January, “as the cost and performance advantages will drive usage over out-of-the-box LLMs.” He’s running automated customer support, document processing, and knowledge management on these models now. The accuracy matches their previous LLM setup, but the latency dropped 70% and the monthly bill dropped 90%.
The architecture AT&T landed on is telling: they use LLMs as “master control” for agentic workflows, while SLMs handle the specialized execution. “The large language and reasoning models will often handle the master control,” Markus explained, “but the purpose-built SLMs very adequately deliver the required accuracy and efficiency when trained for their dedicated job within the agentic workflow.” It’s a hybrid approach that extracts value from both model types without overpaying for either.
Market Economics: Winners, Losers, and the 28% CAGR Reality
Moreover, the SLM market isn’t just growing—it’s accelerating past the overall LLM market. From $0.93 billion in 2025 to a projected $5.45 billion by 2032, that 28.7% compound annual growth rate tells you where enterprise budgets are shifting. Meanwhile, 73% of organizations are actively moving AI inference to edge environments, away from cloud APIs, to cut costs and improve latency.
OpenAI and Anthropic are feeling the pressure. OpenAI’s enterprise market share dropped from 50% in late 2023 to 25% by mid-2025, according to Menlo Ventures’ market analysis. That’s not because their models got worse—it’s because enterprises realized they could fine-tune their own specialized models cheaper than paying per-token forever. Mistral AI, NVIDIA, and other infrastructure players are the clear winners here. Cloud API vendors? They’re facing margin compression as enterprises bring inference in-house.
However, this doesn’t mean frontier LLMs are dead. Anthropic captured 32% enterprise market share by mid-2025, overtaking OpenAI, largely on the strength of Claude’s coding capabilities. But the use cases are narrowing: complex multi-domain reasoning, research-heavy tasks, situations where performance trumps cost. For everything else—high-volume customer support, document classification, domain-specific analysis—SLMs are winning on economics.
When to Use Small Language Models vs LLMs: The Decision Framework
Here’s the calculation CTOs are making right now. SLMs win on three dimensions: cost (90% reduction), privacy (on-premise deployment for GDPR and HIPAA compliance), and domain-specific performance (healthcare SLMs beat GPT-4 on medical tasks). But they’re not universal replacements.
Use SLMs when you have high-volume, repetitive workloads that need domain expertise—customer support bots trained on your company’s documentation, legal document analysis for financial services, medical diagnosis from structured clinical data. These are cases where fine-tuning a 7B-parameter model on your specific dataset delivers higher accuracy than prompting a 400B-parameter general model. Furthermore, research backs this up: one study on requirements classification found LLMs offered only a 2% F1 score improvement over fine-tuned SLMs. The performance gap isn’t worth 100x the cost.
Consequently, stick with frontier LLMs when you need broad general knowledge, complex reasoning across multiple domains, or you’re doing exploratory research where you can’t predict the queries in advance. Use them strategically—as AT&T does, for “master control” of workflows—rather than for every inference call.
The smart play is hybrid: let expensive LLMs handle strategic decisions while purpose-built SLMs execute specialized tasks. You get LLM intelligence where it matters and SLM economics everywhere else.
The Pragmatic Future: Inference Economics Drive Architecture
TechCrunch called 2026 “the year AI gets practical.” After two years of “bigger is better” hype, the industry is pivoting to “what actually works economically.” Inference workloads now consume 55% of AI-optimized infrastructure spending, projected to hit 70-80% by year-end. That’s why SLMs matter: they make continuous inference affordable.
Additionally, edge AI is accelerating this shift. Three-quarters of enterprise data is now created and processed outside traditional data centers, which means inference needs to run locally—on edge servers, on-device with NPUs, anywhere but expensive cloud round-trips. SLMs are small enough to deploy at the edge while delivering real-time performance. Dell’s 2026 edge AI predictions emphasize this: “micro LLMs” optimized for efficiency are moving intelligence to where data lives, not forcing data to travel to centralized GPUs.
The architecture pattern emerging across enterprises is clear: distributed SLMs at the edge for routine operations, frontier LLMs in the cloud for complex reasoning, and hybrid orchestration that routes queries to the right model based on cost and performance needs. This isn’t a fad. Therefore, it’s enterprises doing the ROI math and realizing that paying for GPT-4 to classify customer support tickets is like hiring a PhD mathematician to add up your grocery bill.
AT&T’s Andy Markus proved the model works at scale. The market validated it with 28.7% CAGR growth projections. Now it’s on CTOs and engineering leaders to decide: keep paying OpenAI and Anthropic for every token, or invest in fine-tuning SLMs that actually fit your workload. The companies choosing option two are cutting costs 90% and calling it “getting practical about AI.” The companies sticking with option one are explaining to CFOs why their monthly AI bill is in the millions.
2026 is when the economics win.