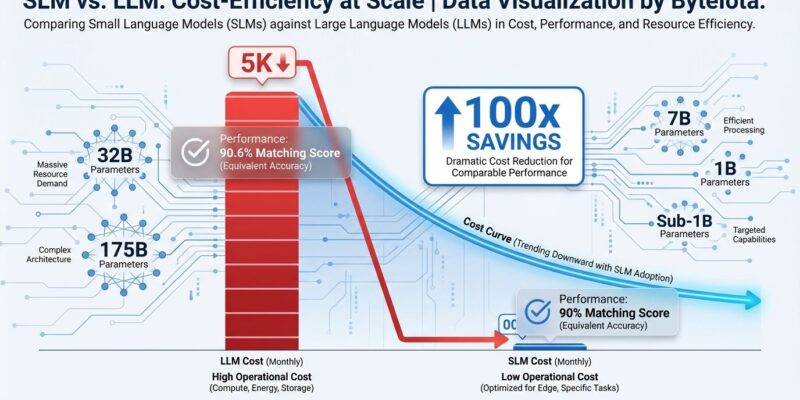
Small Language Models are reshaping enterprise AI with a simple truth: for most tasks, bigger isn’t better—it’s just more expensive. Processing a million conversations costs $15,000 to $75,000 with large language models, but only $150 to $800 with small language models—a 100x cost reduction that’s forcing CTOs to rethink AI budgets. Moreover, benchmarks now prove small models match LLM performance for domain-specific work, and 41% of new deployments are choosing smaller architectures. The AI industry’s most expensive assumption is collapsing.
However, this isn’t speculation. QwQ 32B, a 32-billion-parameter model, beats GPT-4 on mathematics benchmarks and runs on consumer hardware. Companies deploying these models report identical accuracy for specialized tasks at a fraction of the operational cost. When NVIDIA—the company selling GPUs for massive models—publishes research arguing small models are “the future of agentic AI,” it signals more than optimization. It signals pragmatism is replacing hype.
The Benchmark Surprise: Small Models Match GPT-4 Performance
QwQ 32B outperforms GPT-4 on mathematics and matches it on coding, demolishing the assumption that only massive models handle complex tasks. On the MATH-500 benchmark, QwQ scores 90.6%, beating GPT-4o and Claude 3.5 Sonnet. For graduate-level questions (GPQA), it achieves 50.0%, surpassing GPT-4o. In real-world code generation and debugging, it scores 50.0%—competitive with OpenAI’s o1 model.
Furthermore, these aren’t small differences. QwQ 32B—with 32 billion parameters—outperforms models with 175 billion+ parameters on tasks requiring deep reasoning. Its LMSYS leaderboard scores match DeepSeek R1, placing it among frontier models despite being 5-6x smaller. Consequently, the performance gap between “small” and “large” models has effectively disappeared for well-optimized architectures.
Additionally, Gemma 3 27B runs on a single consumer GPU (NVIDIA RTX 3090) using quantization-aware training, not enterprise clusters. Apple Intelligence uses a 3-billion-parameter model to generate 30 tokens per second on the iPhone 15 Pro, with latency under 0.6 milliseconds per token. The hardware requirements for competitive AI performance have dropped from multi-million-dollar data centers to devices people carry in their pockets.
The benchmark data challenges the “frontier model” narrative. If a 32B model beats a 175B+ model on mathematics, what exactly are enterprises paying for? The answer increasingly appears to be overhead, not capability.
The Cost Math Driving SLM vs LLM Decisions
Small models cost 10-30x less to run than large models, with training expenses dropping from $100 million to $3 million for comparable performance. GPT-4 cost over $100 million to train. Google’s Gemini Ultra required $191 million. Meanwhile, 01.ai claims to have trained a GPT-4-comparable model using $3 million in compute—a 97% cost reduction through optimization alone.
Operational costs show even starker differences. Processing one million conversations costs $15,000 to $75,000 with LLMs versus $150 to $800 with SLMs—a 100x savings that compounds across high-volume deployments. Running a 7-billion-parameter SLM is 10-30x cheaper than a 70-175-billion-parameter LLM when measuring latency, energy consumption, and floating-point operations. Additionally, on-device deployment cuts cloud costs by 70%, eliminating API fees and data transfer expenses.
Moreover, the hidden operational costs of LLMs account for 20-40% of total expenses. Token-based pricing models balloon as usage scales across enterprises. Mistral 7B costs 62.5% less than Llama 3 8B for input tokens and 66.7% less for output tokens—savings that accumulate into millions annually for companies processing billions of tokens monthly.
Gartner predicts 40% of enterprise applications will include AI agents by 2026. That vision is only economically viable with SLMs. The enterprise LLM market is projected to grow from $6.7 billion in 2024 to $71.1 billion by 2034, but that growth requires models that companies can actually afford to deploy at scale. TechCrunch’s prediction that “2026 is the year AI moves from hype to pragmatism” translates directly to CFOs counting costs.
Real Enterprise Deployments Prove SLMs Work
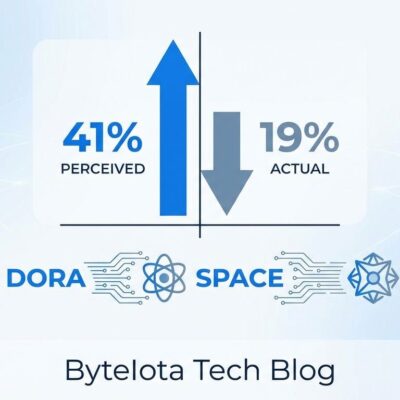
Small models account for 41% of new enterprise deployments, matching LLM accuracy within 3-5 percentage points for domain-specific tasks. This isn’t theory—it’s production systems with measurable ROI.
Oscar Health deployed SLM-powered chatbots integrated with medical records and claims data to handle benefits questions. The system answers 58% of questions instantly and resolves 39% of inquiries without human escalation. Healthcare AI adoption is growing 8x year-over-year, driven by SLMs’ ability to operate on-premise for HIPAA compliance while delivering specialized medical knowledge. One hospital reduced HIPAA violations by 68% in six months using SLMs to scan patient records for exposed Social Security numbers and unauthorized disclosures.
In finance, a Fortune 500 bank automated contract review for loan agreements using a fine-tuned SLM, scanning 12,000 contracts in two weeks—work that would have taken 18 months manually. The model flagged 37% more risky clauses than the human team had identified in the previous year. JPMorgan Chase uses similar models for fraud detection, benefiting from deployment speeds measured in weeks rather than quarters.
Similarly, in customer service, a global retail chain saw satisfaction scores jump 24 points after switching to a Retrieval-Augmented Generation system powered by SLMs. The approach pulls from internal documents, policies, and past interactions to deliver context-aware responses without needing the broad knowledge base of GPT-4. The specialized focus outperforms general-purpose models for the actual queries customers ask.
Privacy and compliance requirements are driving on-premise SLM adoption in banking, healthcare, insurance, and public sectors. When sensitive data cannot leave the security perimeter to comply with GDPR, HIPAA, and ISO 27001, SLMs running on internal infrastructure become the only viable option. Consequently, fine-tuned SLMs don’t just cost less—they often outperform generic LLMs for these specialized domains.
NVIDIA’s Pivot: “Small Models Are the Future of Agentic AI”
NVIDIA, the company selling GPUs for training massive models, published research arguing that small models are better suited for agentic AI systems. The paper’s central claim: SLMs under 10 billion parameters are “sufficiently powerful to take the place of LLMs in agentic systems” because they’re “principally sufficiently powerful, inherently more operationally suitable, and necessarily more economical.”
The cost difference matters for real-time systems. Running a 7B SLM is 10-30x cheaper than a 175B LLM for agentic responses that need sub-second latency. NVIDIA’s position is that enterprises should build heterogeneous agent systems relying on SLMs by default, reserving larger models only for tasks genuinely requiring complex reasoning. The company’s Dynamo inference platform explicitly supports high-throughput, low-latency SLM deployment in both cloud and edge environments.
Furthermore, the strategic insight is architectural. NVIDIA argues for “Lego-like composition of agentic intelligence”—scaling out by adding small, specialized models rather than scaling up monolithic systems. The modular approach delivers systems that are cheaper to run, faster to debug, easier to deploy, and better aligned with the operational diversity enterprises actually face. When combined with tool calling, caching, and fine-grained routing, SLM-first architectures offer the path to cost-effective and sustainable agentic AI.
When the company with the strongest financial interest in selling GPUs for massive models advocates for smaller ones, it’s a signal worth heeding. NVIDIA’s position isn’t altruism—it’s a bet on where the enterprise market is heading. Companies want private inference, making on-device and on-premises execution meaningful advantages. Systems dependent on large cloud models face enterprise barriers that SLMs circumvent.
The Hybrid Future: When LLMs Still Win
The future isn’t SLMs replacing LLMs—it’s intelligent routing between both. Microsoft Research demonstrated that hybrid architectures make up to 40% fewer calls to large models with no drop in response quality, using a router that assigns queries based on predicted difficulty and desired quality levels.
Two routing mechanisms have emerged. Query-level routing trains a classifier to discriminate between “hard” and “easy” queries, directing routine requests to SLMs and complex reasoning to LLMs. Token-level routing dynamically determines LLM involvement during generation, allowing the SLM to handle straightforward portions while escalating to the LLM only for challenging segments. Both approaches balance cost against quality in ways static model selection cannot.
LLMs still win for specific use cases. Complex multi-step reasoning, open-ended creative tasks, broad knowledge across diverse domains, novel or ambiguous problems, tasks with many edge cases, and long document generation all favor larger models. Conversely, SLMs excel at domain-specific tasks in finance, healthcare, and legal contexts, high-volume routine queries, on-device and on-premise deployment, real-time low-latency responses, and cost-sensitive applications.
The best practice emerging from production systems: default to SLMs, escalate to LLMs only when necessary. Route routine or narrow queries through SLMs while reserving complex reasoning tasks for LLMs. This creates a two-tier market—inexpensive general models for routine work and premium models for tasks demanding stronger reasoning performance. The hybrid approach gives reproducibility, predictable cost, and performance matching actual workload demands.
This is the practical takeaway. Enterprises aren’t abandoning LLMs—they’re using them smarter. The decision framework is straightforward: start with SLMs for validation and production deployment, then add LLM escalation paths for the edge cases that genuinely require it. Simple economics.
Key Takeaways
- Small Language Models deliver 100x cost savings compared to LLMs: $15,000-$75,000 drops to $150-$800 for processing a million conversations
- QwQ 32B beats GPT-4 on mathematics benchmarks (90.6% on MATH-500) and matches it on coding, proving small models handle complex reasoning
- 41% of new enterprise deployments choose SLMs for domain-specific tasks, matching LLM accuracy within 3-5 percentage points at a fraction of the cost
- Training costs drop from $100 million+ (GPT-4) to $3 million for comparable models, with operational costs 10-30x lower for SLMs
- NVIDIA argues small models are “the future of agentic AI,” recommending heterogeneous systems that default to SLMs and escalate to LLMs only when needed
- Hybrid architectures using intelligent routing make 40% fewer LLM calls with no quality drop, balancing cost and performance for real-world workloads
- Privacy and compliance requirements (GDPR, HIPAA, ISO 27001) drive on-premise SLM adoption where data cannot leave security perimeters
- Gemma 3 27B runs on consumer GPUs (RTX 3090), and Apple Intelligence’s 3B model generates 30 tokens/sec on iPhone—proving deployment viability
The shift from “bigger is better” to “right-sized for the task” represents AI pragmatism finally catching up to AI hype. Enterprises that continue deploying GPT-4-class models for tasks SLMs handle equally well are paying a premium for capabilities they don’t use. The benchmark data and deployment economics make the case clear: most companies don’t need frontier models. They need models optimized for their specific workloads at costs that scale.