In January 2026, a viral claim erupted across AI development communities: “RAG is DEAD!” The argument is seductively simple. With Gemini offering 1 million token context windows and Claude at 200,000, why bother with the complexity of vector databases and retrieval pipelines? Just dump your entire knowledge base into the prompt and let the LLM handle it. The debate has split developers 50/50, but here’s the truth neither camp wants to hear: naive RAG is dead, sophisticated RAG is thriving, and knowing when to use which approach is the actual skill that matters.
Why “RAG is Dead” Feels Convincing
The long-context argument has real appeal. Million-token windows eliminate chunking and retrieval for small corpora. No embeddings. No vector database infrastructure. Single inference cycle processes everything. For developers exhausted by RAG’s operational complexity, it sounds like liberation.
The use cases exist. Small document sets under 100 docs and 100K tokens total? Long context wins. Static data that never updates? Long context works. Rapid prototyping where you need answers fast, not architecture? Gemini’s 1 million token window beats building a retrieval pipeline. The simplicity pitch resonates because RAG infrastructure genuinely adds moving parts: vector databases, embedding models, orchestration layers, and the DevOps burden that comes with them.
The Brutal Numbers Tell a Different Story
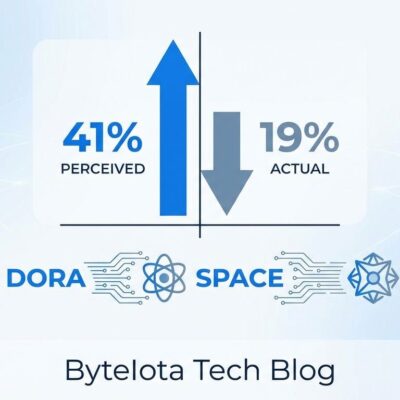
Here’s what the “RAG is dead” advocates aren’t advertising. RAG average query cost: $0.00008. Long context average query cost: $0.10. That’s not a rounding error. RAG is 1,250 times cheaper per query. Cost scales with prompt length on every single call for long context. At 1 million tokens with Gemini pricing, you’re paying $2-$10 per query. Scale that to thousands of daily queries and the monthly bill becomes a budget discussion with your CFO.
Speed compounds the problem. RAG average query speed: 1 second. Long context average: 45 seconds. Users report 30-60 second latencies when context approaches hundreds of thousands of tokens. That’s not acceptable for production applications where users expect sub-second responses.
Then there’s the accuracy issue. Stanford’s “Lost in the Middle” research revealed that LLMs fail to utilize information in the middle of long contexts. Performance degrades by 30% or more when relevant information shifts from the start or end positions to the middle. Gemini 3.0 Pro maintains only 77% accuracy at full 1 million token load. Competitors hit 65-70% at their maximum context lengths. The U-shaped performance curve is real: primacy bias at the beginning, recency bias at the end, and a black hole in the middle where your critical data disappears.
Million-token context doesn’t equal perfect recall. It equals expensive, slow, and lossy retrieval disguised as simplification.
What Actually Died: Naive RAG
So if long context has fatal flaws, what’s the “RAG is dead” crowd actually observing? They’re seeing the death of naive RAG, not retrieval itself. Simple vector similarity search followed by dumping results into context was overengineered for small corpora. That specific pattern deserved to die. Million-token windows made it obsolete for datasets that fit comfortably in memory.
What’s thriving is sophisticated RAG. Agentic RAG embeds autonomous agents into retrieval pipelines, dynamically managing strategies based on query complexity. Multi-hop reasoning systems iterate over knowledge graphs, handling queries that require connecting multiple pieces of information. Hybrid architectures combine RAG with long context, using retrieval for precision and expanded windows for nuance.
Advanced techniques have evolved: two-stage retrieval with broad recall followed by cross-encoder reranking, hybrid search merging semantic and BM25 approaches, strategic ordering that places top evidence at the start and end of context to combat the “lost in the middle” problem. These aren’t academic exercises. They’re production patterns at companies running AI at scale.
The adoption data proves it. RAG framework usage surged 400% since 2024. Sixty percent of production LLM applications now use retrieval-augmented generation. Enterprises report 30-70% efficiency gains in knowledge-heavy workflows, 25-30% reductions in operational costs, and 40% faster information discovery. This isn’t a dead technology. This is infrastructure that works.
The Decision Framework Developers Actually Need
So when should you use long context, and when should you stick with RAG? Here’s the honest breakdown.
Use long context when datasets are static, document counts stay below 100, total tokens remain under 100K, you can tolerate 30-60 second response times, and you’re prototyping or running one-off analysis. Long context shines in these constrained scenarios because the simplicity genuinely outweighs the costs.
Use RAG when you’re dealing with large corpora over 1,000 documents, precision and cost-efficiency matter (remember that 1,250x cheaper figure), real-time data updates are required, speed is critical (1 second versus 45 seconds per query), or traceability is needed for enterprise and regulated industries. RAG’s retrieval logs provide an audit trail that massive context windows can’t match.
Use hybrid approaches combining RAG with long context when queries require multi-hop reasoning, you’re integrating multi-source data, you need both scale and accuracy, or you’re building agentic workflows with tool use. The future isn’t binary. It’s intelligent layering of techniques based on what the problem actually demands.
The Real Lesson: Tools, Not Ideologies
The “RAG is dead” debate exposes something deeper than architectural preferences. Developers are exhausted by unnecessary complexity. They want clear guidance, not religious wars between camps. “One size fits all” mandates don’t work in production environments where cost, latency, accuracy, and scale requirements vary wildly across use cases.
Neither extreme is right. “RAG is dead” is clickbait. “Always use RAG” is cargo cult engineering. The correct answer is boring: evaluate your requirements, understand the tradeoffs, and choose the simplest solution that meets your constraints. If that’s long context for your 50-document internal knowledge base, great. If that’s sophisticated RAG for your 10-million-document customer support system, equally great. The best architecture is the one that solves your specific problem without over-engineering or under-delivering.
RAG isn’t dead. It’s evolving. Long context isn’t a panacea. It’s a tool. And developers who understand when to use which approach are the ones shipping AI products that actually work at scale.