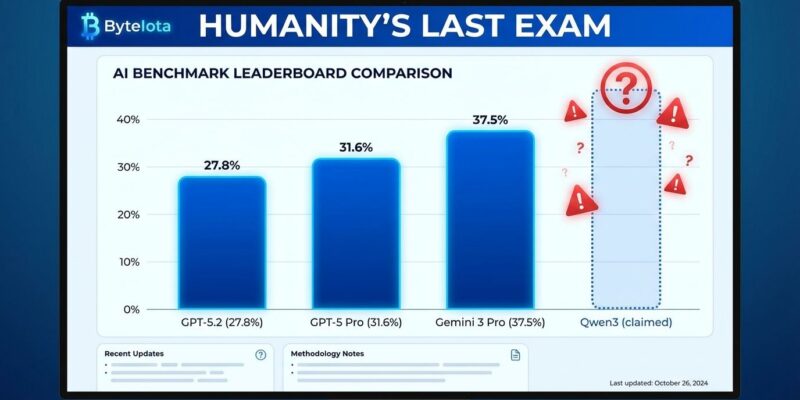
Alibaba announced on January 26 that its Qwen3-Max-Thinking model beats GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro on reasoning benchmarks. The problem? The official Humanity’s Last Exam leaderboard shows Qwen3-Max-Thinking nowhere in the top 10, while Gemini 3 Pro leads at 37.5% and GPT-5.2 scores 27.8%. This isn’t just marketing spin—it’s the latest symptom of an industry-wide benchmark trust crisis.
The Claims vs the Receipts
Alibaba’s announcement cited victories on GPQA Diamond, IMO-AnswerBench, LiveCodeBench, and Humanity’s Last Exam. The company reported 100% accuracy on AIME25 mathematical benchmarks and claimed “state-of-the-art” reasoning performance. These are extraordinary claims for a trillion-parameter model released just days ago.
The Scale.com leaderboard, however, tells a different story. Gemini 3 Pro sits at the top with 37.52%, followed by GPT-5 Pro at 31.64% and GPT-5.2 at 27.80%. Claude Opus 4.5 ranks fifth at 25.20%. Qwen3-Max-Thinking doesn’t crack the top 10. If the model truly “beats” these competitors on Humanity’s Last Exam, the independent leaderboard should reflect it. It doesn’t.
Pattern Recognition: After Meta, Now Alibaba
This comes days after Meta admitted to AI benchmark manipulation, a scandal that shook trust across the industry. The pattern is identical: vendors self-report impressive scores, media amplifies the claims, and independent verification reveals inflated results. When benchmark scores determine billions in enterprise AI contracts, this isn’t just marketing—it’s deception that misallocates capital and erodes trust.
Seeking Alpha’s coverage used careful language: Qwen3-Max “outperforms rivals in some benchmarks.” That qualifier—”some benchmarks”—carries weight. It suggests cherry-picked tests, favorable conditions, or self-administered evaluations. When you control the testing environment, you control the results.
The Nuance: Qwen3 Open Models Actually Deliver
Here’s the frustrating part: Chinese AI models are genuinely competitive. Alibaba doesn’t need to inflate scores.
Qwen3-235B, the open-source flagship, tops LiveBench rankings for open models, beating DeepSeek R1. It’s the most downloaded model family on Hugging Face globally. Developers on Reddit’s r/LocalLLaMA praise its “truly impressive programming capabilities, exceeding expectations in actual projects.” The model works, and it’s good.
DeepSeek R1, released in January, captured 15% global market share through pure reinforcement learning and transparent benchmarking. These aren’t marketing claims—they’re verified by independent tests and real-world adoption. The MIT license and full parameter release built trust that proprietary models struggle to match.
So why does Alibaba undermine this credibility with unverifiable claims about Qwen3-Max-Thinking? The open models prove Chinese AI can compete. The closed model’s marketing suggests insecurity.
The Geopolitical Subtext
Benchmark inflation isn’t just corporate rivalry—it’s soft power competition. Chinese companies face pressure to demonstrate technological parity with US models as export controls and geopolitical tensions intensify. Inflated benchmarks serve dual purposes: they attract customers and signal national AI competence. But this strategy backfires when independent leaderboards contradict the narrative.
The Atlantic Council notes that 2026 is a decisive year for AI geopolitics, with China doubling down on open-source strategies to influence global infrastructure. That strategy works—permissive licenses and genuine quality drive adoption. Unverifiable benchmark claims undermine it.
How Developers Should Respond
Stop trusting vendor benchmarks. Use independent leaderboards like Humanity’s Last Exam, Artificial Analysis, and LiveBench. These platforms test models under controlled conditions without vendor involvement. They’re not perfect—benchmark saturation is a real problem—but they’re orders of magnitude more reliable than self-reported scores.
Test models yourself when possible. Qwen3-Max is available through Alibaba Cloud’s API, starting at $1.20 per million input tokens. Qwen3’s open models (235B, 8B, 32B) can be downloaded and run locally. Real-world performance on your specific use cases matters infinitely more than claimed AIME scores.
Check community feedback on Hacker News and Reddit. Developers who’ve actually used these models provide ground truth that benchmarks can’t capture. The consensus on Qwen3? Strong coding capabilities, excellent multilingual support, genuinely competitive with Western models. That’s valuable signal.
The Real Question
Does benchmark accuracy matter if the models work? Qwen3’s open variants prove Chinese AI is competitive regardless of Qwen3-Max-Thinking’s dubious claims. Developers care about reliability, cost, and performance on real tasks—not leaderboard positioning.
But trust matters too. When vendors lie about benchmarks, how do we trust their API reliability? Their data privacy? Their model safety? Benchmark manipulation is a symptom of an industry that prioritizes marketing over truth. After Meta’s admission and now Alibaba’s claims, the question isn’t whether Chinese or American models are better. It’s whether we can believe anyone.