
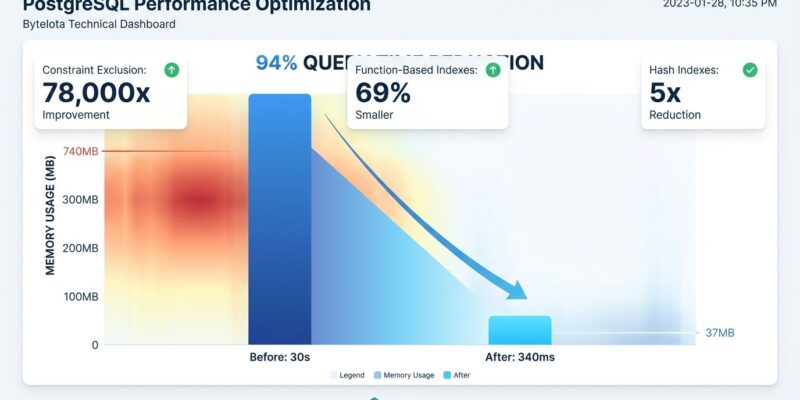
PostgreSQL 17 cut production query times by 94%—from 30 seconds to 340 milliseconds—but most development teams haven’t adopted it yet. While standard optimization advice stops at “add an index” and “tune shared_buffers,” unconventional techniques deliver dramatic performance gains that experienced PostgreSQL developers often miss. Released in late 2025, PostgreSQL 17 introduces incremental VACUUM, bi-directional index scanning, and write-ahead log optimizations that fundamentally change database performance at scale.
PostgreSQL 17 Delivers Game-Changing Performance Improvements
PostgreSQL 17’s incremental VACUUM feature uses 20 times less memory than previous versions—just 37 megabytes versus 740 megabytes for the same operation. The new TidStore internal memory structure tracks dirty pages proportional to write volume, not table size, which means vacuum overhead scales with activity rather than database size. Previous PostgreSQL versions silently capped vacuum memory at 1 gigabyte even when maintenance_work_mem was configured higher.
Moreover, bi-directional index scanning eliminates the need to create reverse-order indexes. Before PostgreSQL 17, queries using ORDER BY ... DESC often required separate descending indexes to maintain performance. Now indexes can be scanned efficiently in both directions without rebuilds. Additionally, high-concurrency workloads see up to 2x better write throughput thanks to write-ahead log (WAL) processing improvements, and IN clause optimizations make multi-value filters substantially faster.
Constraint Exclusion Eliminates Impossible Queries
Enabling constraint_exclusion allows PostgreSQL to skip entire table scans when queries contradict check constraints. This unconventional optimization technique delivered a 78,000x performance improvement in production—reducing query time from 627 milliseconds to 0.008 milliseconds for invalid queries. The approach works best in business intelligence and reporting environments where ad-hoc queries sometimes contain typos or invalid filter values.
Here’s how constraint exclusion works in practice:
-- Enable constraint exclusion
SET constraint_exclusion to 'on';
-- Add check constraint defining valid values
ALTER TABLE users ADD CONSTRAINT users_plan_check
CHECK (plan IN ('free', 'pro'));
-- Query with typo or invalid value
SELECT * FROM users WHERE plan = 'Pro'; -- Capital P
-- Result: 0.008ms (table excluded entirely)
-- Without constraint exclusion: 627ms (full scan)PostgreSQL recognizes that the query condition contradicts the check constraint and skips the scan entirely. However, the technique adds query planning overhead, so it’s not recommended for high-frequency OLTP queries. For read-heavy analytical workloads where users run ad-hoc queries with potential input errors, the performance gain far outweighs the planning cost.
Function-Based Indexes Shrink Storage by 69%
Indexing aggregated expressions instead of high-precision columns reduces index size by 69%—from 214 megabytes to 66 megabytes—and improves query speed 4.3 times. The problem arises when tables store high-cardinality data like timestamps with millisecond precision, but queries aggregate at coarser granularity like daily or hourly intervals. Consequently, traditional indexes on full timestamps balloon in size while providing unnecessary precision.
The unconventional solution indexes the aggregated expression directly:
-- Traditional: Index full timestamp (214MB)
CREATE INDEX sale_sold_at_ix ON sale(sold_at);
-- Unconventional: Index date only (66MB)
CREATE INDEX sale_sold_at_date_ix ON sale(
(date_trunc('day', sold_at AT TIME ZONE 'UTC'))::date
);Furthermore, PostgreSQL 18 enhances this technique with virtual generated columns that compute values at query time instead of storing them. Virtual columns occupy zero disk storage while maintaining query performance. Additionally, adding a virtual column requires only a metadata change—no table rewrite—making it extremely fast to implement:
-- PostgreSQL 18: Virtual generated column
ALTER TABLE sale ADD sold_at_date DATE
GENERATED ALWAYS AS (
(date_trunc('day', sold_at AT TIME ZONE 'UTC'))::date
);
CREATE INDEX sale_sold_at_date_ix ON sale(sold_at_date);This approach enforces discipline across queries since all developers use the same aggregation logic, and index deduplication reduces storage further when multiple timestamps fall within the same day.
Hash Indexes Cut Uniqueness Overhead by 5x
Hash-based exclusion constraints enforce uniqueness on large text fields with indexes 5 times smaller than traditional B-tree approaches—32 megabytes versus 154 megabytes—and deliver 2x faster lookups. B-tree unique indexes store the full text value in the index structure, which creates massive storage overhead for columns like URLs, email addresses, or large text fields. In contrast, hash indexes compute a fixed-size fingerprint regardless of text length.
-- Traditional: B-tree unique index (154MB)
CREATE UNIQUE INDEX urls_url_unique ON urls(url);
-- Unconventional: Hash exclusion constraint (32MB)
ALTER TABLE urls ADD CONSTRAINT urls_url_unique_hash
EXCLUDE USING HASH (url WITH =);The exclusion constraint prevents two rows from having the same hash value, effectively enforcing uniqueness. Lookups run in 0.022 milliseconds versus 0.046 milliseconds with B-tree indexes. However, the technique has limitations: hash indexes cannot be referenced by foreign keys, and INSERT ... ON CONFLICT (column) syntax doesn’t work. The workaround uses the constraint name explicitly:
INSERT INTO urls (id, url) VALUES (3, 'https://example.com')
ON CONFLICT ON CONSTRAINT urls_url_unique_hash
DO NOTHING;Hash indexes only support exact match lookups, not range queries or sorting operations, so they work best when uniqueness is required on large text fields without complex query patterns.
When to Apply Unconventional PostgreSQL Optimizations
Start with standard optimization techniques before reaching for unconventional approaches. Add missing indexes, run EXPLAIN ANALYZE to identify slow operations, tune shared_buffers to 25-40% of system RAM, and adjust work_mem for sort and hash operations. Update table statistics with ANALYZE to ensure the query planner has accurate information. These foundational steps from the PostgreSQL tuning wiki resolve most performance issues.
Nevertheless, unconventional optimizations make sense when standard techniques prove insufficient. If index size exceeds 1 gigabyte and becomes a performance bottleneck, consider function-based indexes or hash exclusion constraints. When query patterns don’t match index structure—like timestamp queries aggregating to daily intervals—function-based indexes deliver substantial improvements. For BI and reporting environments where ad-hoc queries hit impossible conditions, constraint exclusion eliminates wasteful table scans.
Profile first using pg_stat_statements to identify the slowest queries consuming the most resources. The 80/20 rule applies: fixing the slowest 20% of queries typically delivers 80% of the performance improvement. Unconventional techniques have trade-offs—constraint exclusion adds planning overhead, hash indexes can’t be used with foreign keys, and function-based indexes require consistent expression matching. Therefore, choose techniques strategically based on measured bottlenecks rather than theoretical concerns.
Key Takeaways
- PostgreSQL 17 delivers 94% query time reductions through incremental VACUUM (20x less memory) and bi-directional indexes—upgrade now to unlock these performance gains
- Constraint exclusion eliminates invalid queries 78,000x faster by skipping impossible table scans, ideal for BI and reporting environments
- Function-based indexes reduce storage by 69% and speed up queries 4.3x by indexing aggregated expressions instead of high-precision columns
- Hash exclusion constraints shrink unique indexes 5x for large text fields while delivering 2x faster lookups on URLs and emails
- Profile with pg_stat_statements first, apply unconventional techniques strategically when standard optimizations reach their limits
For developers running PostgreSQL in production, these unconventional techniques offer proven paths to dramatic performance gains. The PostgreSQL vs MySQL debate increasingly favors PostgreSQL as these optimizations widen the performance gap. Profile your slowest queries, identify bottlenecks, and apply these techniques where standard approaches fall short.


