The Observability Cost Crisis Nobody Talks About
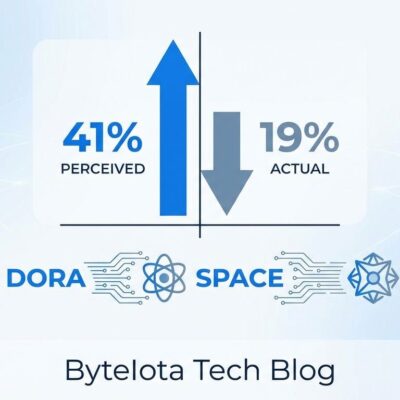
Observability is eating companies alive. Organizations now spend $1 million to $10 million annually just to see what their systems are doing. The average enterprise collects over 10TB of telemetry data every day—a fivefold increase since 2019. Costs surged 212% in four years. And here’s the kicker: 84% of observability users tell Gartner they’re struggling with these costs.
OpenTelemetry—the open-source telemetry standard—is being positioned as the solution. Industry analysts predict it will become the default standard in 2026. Real-world case studies show 50-72% cost reductions. Nearly half of adopters report over 20% ROI.
But is OpenTelemetry actually solving the cost crisis, or just shifting the burden from vendor bills to internal complexity?
Why Observability Costs Exploded
The root problem is simple: Vendor pricing scales linearly with data volume, but value doesn’t. As organizations adopted microservices and Kubernetes, telemetry data exploded. Every microservice generates metrics, logs, and traces. Containers multiply this across thousands of ephemeral instances. Real-time demands shortened collection intervals, creating even more data points.
Enterprise spending on observability increased 212% between 2019 and 2023. Many organizations now face $1M-10M annual budgets. Small teams pay $500-1000 monthly. Large enterprises routinely exceed $10,000 per month.
The cruel irony? More data doesn’t mean proportionally more insights. Teams drown in telemetry while missing critical issues. The “collect everything” mindset creates waste. Yet proprietary vendors charge per GB ingested, per host monitored, and per feature enabled. Once you’re locked into their instrumentation agents and proprietary formats, migration becomes painful enough that vendors can raise prices with impunity.
Datadog exemplifies the problem. Its modular pricing includes up to 20 different SKUs. Costs can explode 100x over initial budgets. Peak usage pricing means you’re charged for traffic spikes, not actual sustained load. New Relic offers more predictable consumption-based pricing at $0.30-0.55 per GB, but that still adds up fast when you’re ingesting terabytes daily.
The shift to cloud-native architectures created better systems. It also created an observability cost crisis that legacy vendor pricing can’t sustain.
OpenTelemetry: Breaking Vendor Lock-In
OpenTelemetry provides an exit strategy. It’s an open standard for collecting metrics, logs, and traces—a CNCF graduated project with 10,000 contributors from 1,200 companies. Unlike proprietary agents, OpenTelemetry instrumentation works with any observability backend. This vendor neutrality changes the economics entirely.
Adoption momentum in 2026 is undeniable. 48.5% of organizations already use OpenTelemetry, with another 25% planning implementation. Among users, 61% consider it “Very Important” or “Critical,” and 81% believe it’s production-ready today. It’s becoming the default standard.
The OpenTelemetry cost benefits are real. STCLab achieved a 72% cost reduction compared to their previous vendor while eliminating sampling constraints. They went from 5% sampled production traces to 100% APM coverage across all environments. Managing millions of concurrent connections during global events, they migrated to the LGTM stack (Loki, Grafana, Tempo, Mimir) with OpenTelemetry instrumentation.
Broader statistics confirm the pattern: 57% successfully reduced costs with OpenTelemetry, 46.4% report over 20% ROI, and 84% saw at least 10% cost decreases. Forrester estimates savings up to 50% versus proprietary tools.
How does OpenTelemetry enable this? By giving teams control over what data is collected, where it goes, and how long it’s retained—control that proprietary vendors will never provide.
Cost Optimization Strategies OpenTelemetry Enables
With OpenTelemetry, teams can implement sophisticated cost optimization strategies that proprietary agents simply don’t allow.
Intelligent sampling reduces data volume without sacrificing visibility. Head-based sampling drops data at collection time, reducing network and storage costs. Tail-based sampling makes smarter decisions after seeing complete traces. Dynamic sampling rates adjust by environment: 100% for critical production paths, 10% for development. A Google Cloud Trace proof-of-concept reduced 42 million spans via strategic sampling.
Data tiering matches storage costs to data value. Recent data (7-30 days) goes to fast, expensive backends for real-time debugging. Medium-term data (30-90 days) lives in compressed warm storage. Long-term data (90+ days) archives to cheap object storage like S3 or GCS. Compliance data rarely accessed sits in archive tiers. This approach delivers massive observability cost savings versus single-tier vendor pricing.
Multi-backend routing sends different telemetry to different destinations. Critical production metrics go to your expensive real-time vendor. Historical debugging data routes to cheaper open-source backends. High-cardinality traces stay in short-term storage only. This cost arbitrage is impossible when you’re locked into a single vendor.
STCLab’s target allocator strategy reduced metric explosion from 20-40x multiplication. Instead of every collector scraping all targets (creating redundancy), per-node allocation assigns scrape jobs only to collectors on matching nodes. This eliminates duplicate metric collection across clusters.
Per-tenant rate limiting prevents “noisy neighbor” problems. A metric surge in your development environment only throttles that tenant’s budget, protecting production costs. This enables chargeback models within organizations and prevents runaway costs from experimental workloads.
The common thread: OpenTelemetry gives teams granular control over observability costs. Proprietary agents offer none of this flexibility.
The Reality Check: It’s Not Magic
OpenTelemetry solves cost problems, but it introduces operational complexity. This is a trade-off, not a silver bullet.
More control means more configuration burden. Teams need expertise in OpenTelemetry Collector, multiple backend integrations, and data pipeline management. Version alignment is critical—mismatched component versions cause failures. Collectors require minimum 4GB nodes; smaller instances can’t handle graceful shutdown memory requirements. Teams accustomed to turnkey vendor solutions face a steep learning curve.
Storage costs don’t disappear. You’re still paying for S3 or GCS retention somewhere. Operational overhead remains: Platform team time managing infrastructure, integrating separate tools (Grafana, Tempo, Loki, Mimir), and handling incidents without vendor support SLAs.
For small teams (under 10 engineers) without platform or SRE expertise, proprietary vendors often make more sense. The operational overhead of self-hosted observability exceeds the vendor costs. If your budget isn’t constrained and you need turnkey solutions with minimal ops burden, Datadog or New Relic might still be the right choice.
The common hybrid approach: Instrument with OpenTelemetry now (future-proof), send data to your existing proprietary vendor (familiar UX), then gradually migrate backends as your team matures. This reduces migration risk while gaining the flexibility to move later when costs justify the operational investment.
OpenTelemetry isn’t “free observability.” You’re trading vendor costs for operational investment. Do the math honestly for your situation.
What OpenTelemetry Observability Means for 2026
OpenTelemetry is becoming table stakes in 2026. It’s the default choice for new projects, with 90%+ greenfield adoption expected. Existing projects are planning migration paths. Job postings increasingly require OpenTelemetry experience. Universities are teaching it in DevOps curricula.
But the observability cost crisis won’t disappear—it’s shifting forms. Data volumes continue growing as IoT, edge computing, and AI workloads generate even more telemetry. Serverless functions produce ephemeral, high-cardinality data that’s expensive to store and query. The growth rate may outpace optimization gains.
AI-powered cost optimization is emerging. Automatic sampling rate adjustment based on system health. Predictive data collection that increases fidelity when anomalies are likely. AI-driven retention policies that keep what matters and discard noise. These capabilities will separate leaders from laggards.
Platform engineering teams will own observability strategy in 2026. Cost budgets will be enforced at the platform level. FinOps integration will include pre-deployment cost gates that reject services generating excessive telemetry. Chargeback models within organizations will make costs visible to product teams.
The vendor market is shifting too. Proprietary vendors face pricing pressure as customers gain OpenTelemetry leverage in negotiations. More “OpenTelemetry-first” commercial products are emerging. Vendors differentiate on UX and intelligence, not data collection. Open-core models proliferate: Free OpenTelemetry collection, paid analytics layers.
The skills gap is widening. High demand for OpenTelemetry expertise means platform and SRE teams need deep understanding. Training and certification programs are emerging to meet demand.
OpenTelemetry is the right architectural choice for 2026. But teams must invest in expertise to capture the cost benefits. Those that don’t will continue drowning in observability bills, wondering why their “modern” architecture costs so much to monitor.