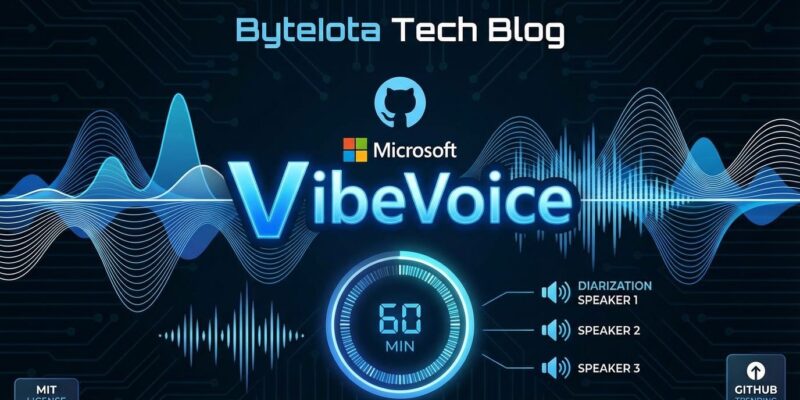
Microsoft open-sourced VibeVoice-ASR on January 21, 2026, a frontier voice AI model that processes 60-minute audio files in a single pass—a capability that sets it apart from dominant players like OpenAI’s Whisper, which chunks audio into 30-second segments. The 7-billion-parameter model integrates speech recognition, speaker diarization, and timestamping into one unified system, and it’s already trending at #2 on GitHub with 21,300 stars. Released under an MIT License, VibeVoice competes directly with OpenAI’s Whisper while paradoxically cannibalizing Microsoft’s own Azure Speech Services.
Single-Pass Processing: The Technical Leap
VibeVoice-ASR-7B processes up to 60 minutes of audio within a 64K token context window, maintaining global semantic coherence and consistent speaker tracking throughout. Traditional ASR systems split a 60-minute audio file into 120 separate 30-second chunks, which creates boundary effects—speaker IDs get lost across segments, context disappears, and transcription quality degrades for long-form content like podcasts, meetings, or lectures.
The breakthrough comes from continuous speech tokenizers operating at an ultra-low 7.5 Hz frame rate, compared to the traditional 50-100 Hz used by most TTS systems. This innovation achieves 3200x compression from 24kHz audio input while preserving perceptual quality, dramatically reducing computational requirements for processing extended sequences. Whisper, Google Cloud Speech-to-Text, and Amazon Transcribe all rely on chunking approaches, making VibeVoice the first open-source ASR model to handle hour-long audio in one inference.
Integrated Diarization: One Model, Structured Output
VibeVoice jointly performs ASR, speaker diarization, and timestamping in a single unified model, producing structured transcriptions that show who said what and when. Traditional workflows require running separate models—first transcribe with Whisper, then run Pyannote for speaker diarization, then manually align timestamps and speakers—introducing complexity and error propagation at each step.
The integrated approach eliminates this toolchain complexity. For meeting transcription, VibeVoice automatically generates reports with speaker labels and timestamps. For podcast search, users can navigate directly to “where Speaker B discusses topic X.” Customer service teams get instant customer-vs-agent dialogue tracking. Accessibility applications benefit from multi-speaker differentiation in real-time captions.
Custom hotword support enables domain-specific accuracy. Developers can provide technical terms, product names, or jargon (e.g., “Kubernetes,” “ByteIota,” drug names in medical contexts), significantly improving transcription quality for specialized content. Whisper doesn’t offer this capability.
The Strategic Paradox: Microsoft Competes with Itself
Microsoft is open-sourcing what Azure sells. Azure Speech Services ranks second-to-last in ASR benchmarks, while Whisper dominates the open-source market. Rather than improving Azure, Microsoft chose a different path: win developer mindshare on GitHub, then convert them to Azure cloud infrastructure later.
This GitHub-first strategy is intentional. Microsoft’s R&D investment is concentrated on GitHub, not Azure DevOps. In 2024, GitHub hosted 518 million open-source projects and saw a 59% year-over-year surge in generative AI contributions. By releasing VibeVoice under MIT License, Microsoft positions GitHub as its AI innovation engine while Azure remains the enterprise infrastructure layer. It’s a classic freemium play—free ASR today, paid compute tomorrow.
The timing aligns with the voice AI arms race. OpenAI reorganized teams around audio and plans to launch a new audio model in Q1 2026, alongside “Sweetpea” ChatGPT-powered earbuds targeting 40-50 million units. Google delayed Gemini’s replacement of Google Assistant until March 2026. Meta shipped Ray-Ban AI glasses with five-microphone arrays. Microsoft isn’t leading this “war on screens”—it’s responding with an open-source counterattack.
Market Context: Voice AI Goes Long-Form
The speech-to-text market is projected to grow from $3.81 billion in 2024 to $8.57 billion by 2030, driven by voice interfaces, accessibility regulations, and the long-form content explosion. Podcasts, Zoom meetings, and video captions generate millions of hours of audio daily, and chunking-based ASR systems struggle with context loss.
VibeVoice addresses this gap. Podcasters can transcribe entire episodes without segmentation artifacts. Educators can transcribe 60-minute lectures with consistent speaker tracking. Enterprises can analyze hour-long customer calls without losing semantic coherence across chunks.
But the model is only three days old. Microsoft’s repository explicitly warns: “We do not recommend using VibeVoice in commercial or real-world applications without further testing.” The company also notes that “high-quality synthetic speech can be misused to create convincing fake audio content,” flagging deepfake concerns. VibeVoice supports primarily English and Chinese, far short of Whisper’s 99-language capability.
Developer Impact: Open Source Democratizes Frontier AI
GitHub trending #2 status—with 261 stars gained in one day—signals strong developer interest. The MIT License grants freedom to use, modify, and commercialize the model without API costs, leveling the playing field for startups competing against Google Cloud Speech and Amazon Transcribe.
Whether VibeVoice displaces Whisper remains uncertain. Whisper has years of production validation, 99-language support, and a massive training corpus (1 million hours of labeled audio). VibeVoice is bleeding-edge—unproven, limited in language scope, and likely unstable for production use.
But the 60-minute single-pass capability is a genuine differentiator. If community validation confirms Microsoft’s claims, VibeVoice could redefine long-form ASR. For now, developers have a Whisper alternative optimized for the use case Whisper struggles with: hour-long audio that demands global context and multi-speaker tracking.