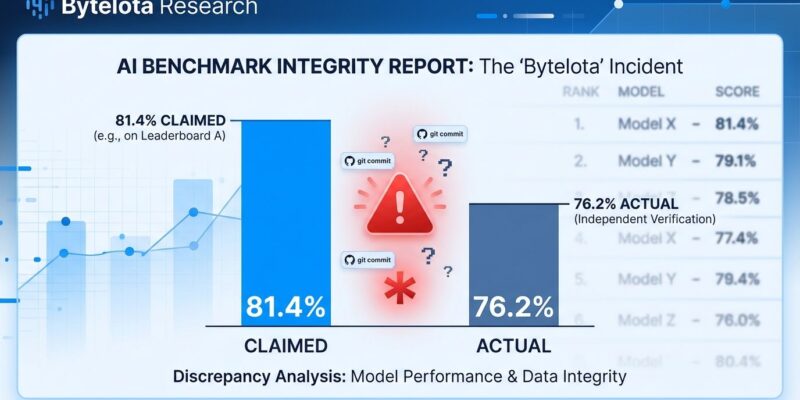
## Beyond the Hype: 76.2% Still Matters Strip away the benchmark drama, and IQuest Coder V1 is genuinely interesting. It’s a 40-billion parameter model from Ubiquant’s IQuest Lab that matches much larger models through “Code-Flow Training”—learning from repository evolution patterns and commit histories, not just static code snapshots. The model is fully open-source under a Modified MIT license, supports 128K tokens natively (no rope scaling tricks), and comes in three variants: Instruct for general coding, Thinking for complex reasoning, and Loop for efficient inference. The corrected 76.2% on SWE-Bench Verified is competitive with GPT-5.1 (76.3%) and close to Claude Sonnet 4.5 (77.2%). China’s AI ecosystem is maturing fast. Ubiquant joining DeepSeek, Alibaba, and Tencent in releasing competitive open-source models signals a shift. Western companies can’t rely on closed-source advantage anymore—even with the scandal, IQuest Coder’s 76.2% shows Chinese labs are catching up technically. They just need better evaluation rigor.Related: AI Code Verification Bottleneck: 96% Don’t Trust AI Code
## What Developers Should Do Don’t abandon AI coding tools, but stop trusting marketing claims. The corrected IQuest Coder (76.2%) is worth testing if you need self-hosting, 128K context, or open-source control—but run it against YOUR codebase first, not public benchmarks. The model requires 80GB VRAM for the 40B variant, though community-created GGUF quantized versions bring requirements down to ~40GB with minimal quality loss. IQuest Lab’s transparency in acknowledging the flaw and releasing corrected scores is better than most vendors—but real-world performance on domain-specific code is what matters, not leaderboard position. The future of AI evaluation isn’t blind trust in benchmarks. It’s independent verification, rotating test sets, and testing on YOUR tasks. Developers who adapt to this reality will make better tool choices. Those who keep chasing leaderboard leaders will get burned. ## Key TakeawaysRelated: DeepSeek mHC: $5M AI Model Challenges Scaling Myths
- IQuest Coder V1 initially claimed 81.4% on SWE-Bench Verified but corrected to 76.2% after a git history exploit was discovered—competitive but not record-breaking
- Benchmark gaming is systemic across the industry, with Alibaba, Google, Meta, Microsoft, and OpenAI all caught using questionable methodologies
- Only 16% of 445 LLM benchmarks use rigorous scientific methods, and independent testing shows 8-point gaps between official and verified scores
- IQuest Coder is legitimately interesting despite the scandal: 40B parameters competing with 100B+ models through Code-Flow Training, fully open-source, 128K native context
- Test AI coding tools on YOUR codebase, not public leaderboards—real-world performance on domain-specific tasks is what matters