ICML 2026 just rejected 497 papers after catching AI researchers using AI to fake peer reviews. The conference embedded watermarks in submitted papers that triggered telltale phrases when fed to LLMs—a technique published at ICLR 2026 and now weaponized against its creators. The rejection rate: 2% of all submissions. The detection method: 0.0001 false positive rate. The irony: the people building AI for the world got caught misusing it to cut corners in academic peer review.
This isn’t about technology failure. It’s about trust collapse in the community responsible for shaping AI’s future. When the experts can’t use their own tools responsibly, what does that say about the rest of us?
The Watermark Trap That Caught 497 Cheaters
ICML organizers embedded machine-readable instructions into PDF papers sent to reviewers. If a reviewer fed the watermarked PDF to an LLM—ChatGPT, Claude, Gemini, doesn’t matter—the hidden prompt instructed the AI to include two specific phrases in the generated review. Those phrases were randomly selected from a dictionary of around 170,000 options. Moreover, detection was automated: phrases present equals policy violation equals paper rejected.
The technique is based on research published at ICLR 2026: “In-Context Watermarks for Large Language Models.” It combines in-context learning with prompt injection, leveraging the very instruction-following capability that makes LLMs useful to detect when they’re misused. Success rate exceeded 80% across most models, with a family-wise error rate of 0.0001—virtually no false positives.
However, ICML acknowledges the method isn’t perfect. As organizers noted, watermarking is “not difficult to circumvent, particularly if it is known publicly” and “may only catch some of the most egregious and careless uses of LLMs in reviewing.” Nevertheless, catching 497 violations proves the honor system is dead. Trust-based peer review just ended.
2% Violation Rate Signals Systematic Abuse
497 rejected papers represent roughly 2% of ICML’s ~25,000 submissions. That’s not a few bad actors—it’s systematic abuse. Furthermore, the numbers tell the story: 398 reciprocal reviewers violated the policy they explicitly agreed to, producing 795 flagged reviews across 506 unique violators. 51 reviewers were so egregious—using LLMs in more than half their reviews—that ICML deleted all their reviews and banned them from the reviewer pool entirely.
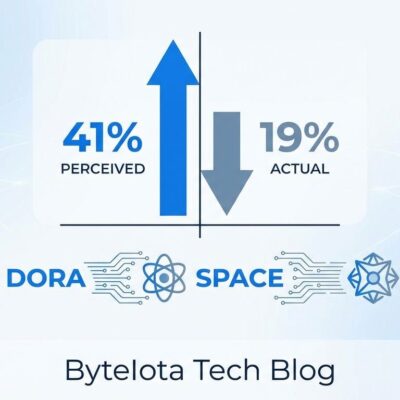
Context makes it worse. ICLR 2026 discovered that 21% of peer reviews were entirely AI-generated, with over 50% showing signs of AI use. At ICLR, 199 manuscripts (1%) were fully AI-generated. Consequently, the integrity crisis isn’t unique to ICML—it’s endemic across top AI conferences.
The academic honor system has failed. When 2% of submissions at a flagship conference involve review fraud, and 21% of reviews at another conference are AI slop, peer review credibility is in free fall.
Collateral Damage: Innocent Co-Authors Pay the Price
ICML’s reciprocal review policy creates a brutal outcome: every paper author must review other papers, and if one co-author violates policy, the entire team’s paper gets desk-rejected. Therefore, co-authors who did nothing wrong suffer career consequences—delayed graduations, lost funding, reputational damage—because a collaborator cut corners.
The community is divided. Pro-enforcement voices argue, “Co-authors should vet their collaborators’ ethics.” Meanwhile, anti-enforcement critics counter, “Research teams shouldn’t be held hostage to one member’s mistakes.” ICML’s position is clear: “We cannot grant exceptions based on the degree of LLM involvement, as doing so would make the policy unenforceable and erode the trust the community places in it.”
It’s harsh, but the alternative—no consequences for violators—would incentivize more cheating. Collateral damage is the price of enforcement in a system where trust has already broken down.
Policy A Violators Broke Explicit Promises
ICML offered reviewers two policies. Policy A (Conservative) strictly banned LLM use at any stage of reviewing. In contrast, Policy B (Permissive) allowed LLMs for understanding papers, related work searches, and polishing grammar, but still required human judgment for evaluations.
The 497 rejected papers were all from Policy A violators—reviewers who explicitly chose the stricter policy, agreed to it, and then broke their word. They weren’t caught in a gray area. They lied, got caught, and now face consequences. This wasn’t accidental; it was deliberate rule-breaking by people who knew the rules.
The Precedent: Trust-Based Peer Review is Over
ICML’s enforcement sets a precedent that will ripple across academic publishing. NeurIPS 2026 is piloting AI-assisted reviews with mandatory human oversight. Additionally, ICLR 2026 introduced a new mandatory disclosure policy: use an LLM, acknowledge it. CVPR, AAAI, and other major conferences are adopting stricter policies after watching ICML’s success.
The shift is fundamental. Academic peer review previously operated on an honor system: trust reviewers to be honest, ethical, and thorough. That’s over. The new model is adversarial verification: assume cheating will happen, deploy technical countermeasures, catch violators through detection systems. Conferences now compete on who has the best watermarking, linguistic AI detection, and behavioral analysis tools.
We’re entering a technology arms race. Conferences develop better detection methods; reviewers develop better evasion techniques. The cat-and-mouse game replaces trust-based collaboration. As ICML organizers put it: “As our field changes rapidly the thing we must protect most actively is our trust in each other.”
The irony is thick: protecting trust now requires assuming distrust.
What This Says About AI and Trust
The most damning aspect of ICML 2026’s 497 rejections is the message it sends: AI researchers—the people building these models, advocating for their deployment, and shaping AI policy—can’t be trusted to use AI responsibly themselves. If the experts cheat with AI to avoid peer review work, why should society trust AI in healthcare, finance, or governance?
The academic integrity crisis reflects the broader AI governance challenge. The same tension exists everywhere: efficiency vs. trust. LLMs can generate peer reviews faster, write code faster, produce content faster. However, speed without accountability erodes the systems those tools are meant to improve.
ICML’s watermark detection is a win—497 violations caught, consequences enforced, message sent. Nevertheless, it’s also a defeat. The fact that watermarks were necessary proves the community has a trust problem it can’t solve with policy alone. Technology caught the cheaters this time. Next time, the cheaters will be more sophisticated. And the cycle continues.
The future of peer review will likely involve normalized AI assistance with strict guardrails: AI handles routine tasks like literature searches and grammar checks, humans handle critical judgment on novelty and significance, and transparency is mandatory. Policy B—allow AI with disclosure—will become the standard. But the trust that once defined academic collaboration is gone. ICML 2026 marked the inflection point where honor systems died and adversarial verification became the norm.
For more details on ICML’s detection method, see the Nature coverage and the original ICLR 2026 watermarking paper.