
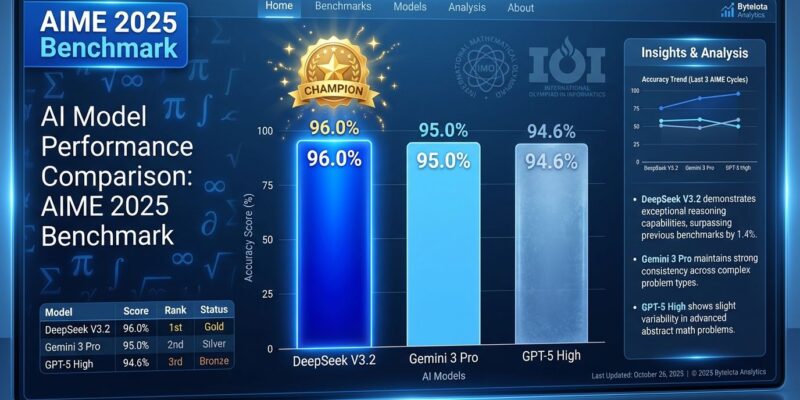
Chinese AI startup DeepSeek launched V3.2 and V3.2-Speciale today (December 1, 2025), claiming the first open-source models to match GPT-5-level reasoning performance. DeepSeek-V3.2-Speciale achieved a 96.0% pass rate on the AIME 2025 benchmark, beating both OpenAI’s GPT-5 High (94.6%) and Google’s Gemini 3 Pro (95.0%). Both models are available immediately via API and released under MIT license on HuggingFace with full weights, code, and technical reports—dramatically undercutting proprietary competitors at $0.28 per million input tokens.
Beating GPT-5 on Math Reasoning
DeepSeek-V3.2-Speciale topped the AIME 2025 mathematics benchmark with a 96.0% pass rate, surpassing GPT-5 High’s 94.6% and Gemini 3 Pro’s 95.0%. The achievement marks the first time an open-source model has outperformed proprietary frontier models on advanced reasoning tasks. DeepSeek also claimed gold medal performance at the 2025 International Mathematical Olympiad (IMO), 10th place at the International Olympiad in Informatics (IOI), and 2nd place at the ICPC World Final.
However, performance isn’t uniform across all benchmarks. On LiveCodeBench, V3.2 scored 83.3%—trailing GPT-5’s 84.5% and well behind Gemini 3 Pro’s 90.7% lead. Nevertheless, DeepSeek reversed the gap on SWE Multilingual software engineering tasks, scoring 70.2% versus GPT-5’s 55.3%. The mixed results suggest V3.2 excels at mathematical reasoning but hasn’t achieved universal GPT-5 parity across all domains.
Gold medals are impressive, but they don’t guarantee real-world usefulness. Furthermore, developers should validate performance on their specific tasks rather than relying solely on olympiad scores. Independent verification is still pending—DeepSeek’s claims are backed by their track record (DeepSeek Math V2’s benchmark scores were validated), but V3.2 launched today, leaving limited time for third-party testing.
Related: DeepSeek Math V2 Hits IMO Gold: First Free AI Model
DeepSeek Sparse Attention Enables Efficiency
The technical breakthrough powering V3.2 is DeepSeek Sparse Attention (DSA), a fine-grained sparse attention mechanism that delivers “substantial improvements in long-context training and inference efficiency while maintaining virtually identical model output quality.” Consequently, DSA enables the 671B-parameter model (with Mixture-of-Experts architecture activating only 37B parameters per token) to process extremely long contexts without the computational explosion of traditional attention.
Moreover, DeepSeek validated DSA by comparing V3.2-Exp against its predecessor V3.1-Terminus with deliberately aligned training configurations. The results showed near-identical performance (MMLU-Pro: 85.0 for both, AIME: 88.4 vs 89.3) while delivering efficiency gains for long-context scenarios. This controlled experiment approach—testing one architectural change while holding everything else constant—is rare in AI research and earned praise from developers as “the kind of release we need more of.”
First Model Integrating Thinking into Tool-Use
V3.2 introduces a capability no other model offers: integrating thinking directly into tool-use workflows. The standard V3.2 supports both thinking mode (where the model shows its reasoning chains) and non-thinking mode (direct answers), while maintaining tool calling capabilities in both modes. Additionally, DeepSeek trained the models on a massive synthetic data pipeline covering 1,800+ environments and 85,000+ complex instructions specifically designed for agent development.
For developers building autonomous agents, this integration is significant. Most LLMs separate reasoning and tool-use into distinct workflows—models either think through problems or call functions, but rarely both simultaneously. In contrast, DeepSeek’s approach enables more sophisticated agentic behavior where models reason through multi-step tasks while actively using external tools.
However, V3.2-Speciale sacrifices this capability for maximum reasoning depth. The Speciale variant doesn’t support tool calls, focusing entirely on pure reasoning tasks. Therefore, choose standard V3.2 for agent development, Speciale only for experimental reasoning tests.
50% Cheaper, But with Caveats
DeepSeek V3.2 costs $0.28 per million input tokens—a 50% reduction from the previous $0.56 rate and dramatically cheaper than GPT-5’s enterprise pricing. Furthermore, both models are released under MIT license on HuggingFace with complete weights, code, and inference tools, enabling commercial fine-tuning and deployment without restrictions. Multiple serving options are available: SGLang, vLLM (with day-0 support), and high-performance CUDA kernels for production deployments.
The lower per-token pricing is real, but Speciale’s economics tell a different story. It consumes 77,000 tokens on average for Codeforces programming problems compared to Gemini 3 Pro’s 22,000 tokens—a 3.5x multiplier that partially offsets the cheaper pricing. Consequently, this extreme token consumption explains why Speciale is only available through a temporary API endpoint that expires December 15, 2025. DeepSeek is clearly testing whether ultra-deep reasoning justifies the computational costs before committing to a permanent offering.
Don’t build production systems dependent on Speciale. The 2-week availability window makes it unsuitable for anything beyond experimental testing. For real-world deployments, standard V3.2 offers permanent API access, tool call support, and local deployment options—making it the pragmatic choice despite lower peak reasoning performance.
While OpenAI and Google focus on ecosystem lock-in, DeepSeek targets developers with unrestricted open access. The MIT license enables fine-tuning and commercial deployment without vendor dependence—a stark contrast to proprietary competitors. For indie developers and startups, V3.2 dramatically lowers the barrier to GPT-5-class AI.
Key Takeaways
- DeepSeek-V3.2-Speciale achieved 96.0% on AIME 2025, beating GPT-5 High (94.6%) and Gemini 3 Pro (95.0%)—the first open-source model matching proprietary frontier performance on reasoning
- DeepSeek Sparse Attention (DSA) delivers efficiency gains for long-context processing while maintaining model quality, validated through controlled experimental comparison
- V3.2 integrates thinking directly into tool-use for the first time, enabling sophisticated agent development—but Speciale sacrifices tool calls for maximum reasoning depth
- Pricing dropped 50% to $0.28/M tokens with MIT-licensed open weights, but Speciale’s 3.5x token consumption and December 15 API expiration limit production viability
- Gold medal benchmarks require independent validation—developers should test V3.2 on their specific tasks rather than relying solely on olympiad scores


